소개
오늘날 많은 조직은 ‘빅 데이터’로 작업합니다. 대량 볼륨과 다양한 데이터 및 데이터 생성 속도 등을 지원하려면 이를 관리하고 제어하는 데 도움이 되는 시스템이 필요합니다. 과거에는 조직에서 관계형 데이터베이스 관리 시스템을 사용하여 데이터를 제어했습니다. 그러나 이제 조직에서는 오픈 소스 소프트웨어의 기능을 호스트된 플랫폼의 이점과 결합하고자 합니다. Azure HDInsight는 이러한 파트너 관계의 완벽한 예입니다. HDInsight를 사용하면 기록 또는 실시간 데이터를 사용하여 다양한 시나리오에서 빅 데이터를 처리할 수 있습니다.
다음 그림은 HDInsight를 사용할 수 있는 방법의 개요를 보여 줍니다. IoT(사물 인터넷) 센서, 데이터베이스, 여러 Azure 데이터 저장소를 포함한 다수의 데이터 원본을 보여 줍니다. HDInsight는 이러한 위치의 데이터를 처리합니다. 그런 다음 해당 데이터를 실시간 앱 및 추가 분석을 위해 장기 스토리지에서 사용할 수 있도록 합니다.
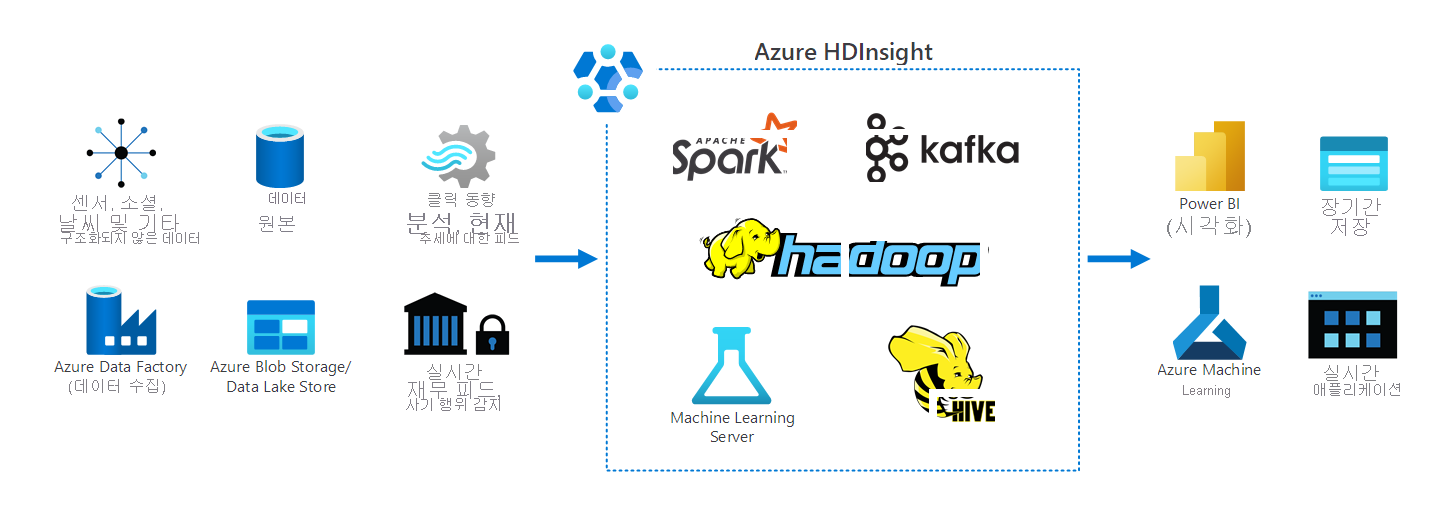
예제 시나리오
기록 보고 및 고급 분석을 위한 데이터를 수집하는 워크로드를 구축하는 조직에서 근무한다고 가정하겠습니다. 분석이 필요한 스트리밍 데이터도 있을 수 있습니다. 이 경우 HDInsight 사용을 고려하는 것이 좋습니다. 이를 통해 모든 데이터를 단일 Data Lake 위치로 수집할 수 있습니다. 그런 다음 해당 데이터를 사용하여 다음 워크로드를 관리할 수 있습니다.
- 일괄 처리
- 데이터 웨어하우징
- 데이터 과학 작업
- 스트리밍
이 모듈에서 수행할 작업
이 모듈이 끝나면 조직이 빅 데이터를 처리하는 데 HDInsight가 도움이 될 수 있는지를 평가할 수 있습니다. 또한 HDInsight가 다양한 데이터 시나리오를 지원하는, 널리 사용되는 오픈 소스 프레임워크를 사용하는 방법을 설명할 수 있게 됩니다.
주요 목표는 무엇인가요?
주요 목표는 HDInsight가 빅 데이터 처리 요구 사항에 적합한 선택인지 여부를 결정하는 것입니다.