OCR(광학 문자 인식)
비고
자세한 내용은 텍스트 및 이미지 탭을 참조하세요.
OCR(광학 문자 인식)은 스캔한 문서, 사진 또는 디지털 파일 등 이미지의 시각적 텍스트를 편집 가능하고 검색 가능한 텍스트 데이터로 자동으로 변환하는 기술입니다. OCR은 정보를 수동으로 전사하는 대신 다음에서 자동화된 데이터 추출을 가능하게 합니다.
- 스캔한 청구서 및 영수증
- 문서의 디지털 사진
- 텍스트 이미지가 포함된 PDF 파일
- 스크린샷 및 캡처된 콘텐츠
- 양식 및 필기 노트
OCR 파이프라인: 단계별 프로세스
OCR 파이프라인은 시각적 정보를 텍스트 데이터로 변환하기 위해 함께 작동하는 다섯 가지 필수 단계로 구성됩니다.
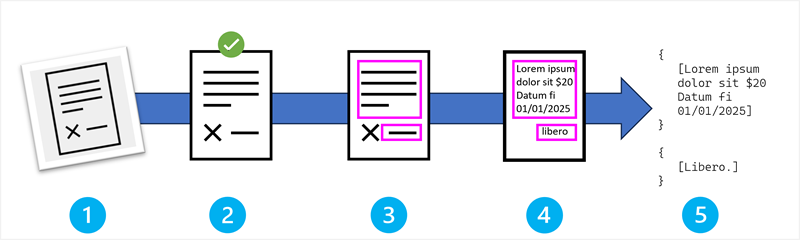
OCR 프로세스의 단계는 다음과 같습니다.
- 이미지 획득 및 입력.
- 전처리 및 이미지 향상.
- 텍스트 영역 검색.
- 문자 인식 및 분류.
- 출력 생성 및 후처리.
각 단계를 좀 더 자세히 살펴보겠습니다.
1단계: 이미지 획득 및 입력
파이프라인은 텍스트가 포함된 이미지가 시스템에 들어갈 때 시작됩니다. 이는 다음과 같습니다.
- 스마트폰 카메라로 찍은 사진.
- 플랫베드 또는 문서 스캐너에서 스캔한 문서입니다.
- 비디오 스트림에서 추출된 프레임입니다.
- 이미지로 렌더링된 PDF 페이지입니다.
팁 (조언)
이 단계의 이미지 품질은 텍스트 추출의 최종 정확도에 크게 영향을 줍니다.
2단계: 전처리 및 이미지 향상
텍스트 검색을 시작하기 전에 다음 기술을 사용하여 더 나은 인식 정확도를 위해 이미지를 최적화합니다.
노이즈 감소 는 시각적 아티팩트, 먼지 반점 및 텍스트 감지를 방해할 수 있는 스캔 결함을 제거합니다. 노이즈 감소를 수행하는 데 사용되는 특정 기술은 다음과 같습니다.
- 필터링 및 이미지 처리 알고리즘: Gaussian 필터, 중앙값 필터 및 형태 연산.
- 기계 학습 모델: 문서 이미지 정리를 위해 특별히 학습된 디노이징 자동 인코더 및 컨볼루션 신경망(CNN)
대비 조정 을 사용하면 텍스트와 배경의 차이가 향상되어 문자가 더 구별됩니다. 다시 말하지만, 다음과 같은 여러 가지 방법이 있습니다.
- 클래식 메서드: 히스토그램 균등화, 적응 임계값 및 감마 보정.
- 기계 학습: 다양한 문서 유형에 대한 최적의 향상된 매개 변수를 학습하는 딥 러닝 모델입니다.
기울이기 보정 은 문서 회전을 감지하고 수정하여 텍스트 줄이 가로로 올바르게 정렬되도록 합니다. 기울이기 수정에 대한 기술은 다음과 같습니다.
- 수학 기술: 선 감지, 프로젝션 프로필 및 연결된 구성 요소 분석을 위한 Hough 변환입니다.
- 신경망 모델: 이미지 기능에서 직접 회전 각도를 예측하는 회귀 CNN입니다.
해상도 최적화 는 이미지 해상도를 문자 인식 알고리즘의 최적 수준으로 조정합니다. 다음을 사용하여 이미지 해상도를 최적화할 수 있습니다.
- 보간 방법: 쌍입방, 쌍선형 및 Lanczos 다시 샘플링 알고리즘.
- 초고해상도 모델: 저해상도 텍스트 이미지를 지능적으로 스케일 업스케일하는 GAN(생성 적대적 네트워크) 및 잔차 네트워크입니다.
3단계: 텍스트 영역 검색
시스템은 전처리된 이미지를 분석하여 다음 기술을 사용하여 텍스트가 포함된 영역을 식별합니다.
레이아웃 분석은 텍스트 영역, 이미지, 그래픽 및 공백 영역을 구분합니다. 레이아웃 분석을 위한 기술은 다음과 같습니다.
- 기존 방법: 연결된 구성 요소 분석, 실행 길이 인코딩 및 프로젝션 기반 세분화입니다.
- 딥 러닝 모델: U-Net, 마스크 R-CNN 및 특수 문서 레이아웃 분석 모델(예: LayoutLM 또는 PubLayNet 학습 모델)과 같은 의미 체계 구분 네트워크입니다.
텍스트 블록 식별 은 개별 문자를 공간 관계에 따라 단어, 줄 및 단락으로 그룹화합니다. 일반적인 방법은 다음과 같습니다.
- 클래식 방법: 거리 기반 클러스터링, 공백 분석 및 형태 연산
- 신경망: 공간 문서 구조를 이해하는 그래프 신경망 및 변환기 모델
읽기 순서 결정은 텍스트를 읽어야 하는 시퀀스를 설정합니다(영어의 경우 왼쪽에서 오른쪽, 위에서 아래로). 올바른 순서는 다음을 통해 확인할 수 있습니다.
- 규칙 기반 시스템: 경계 상자 좌표 및 공간 추론을 사용하는 기하학적 알고리즘입니다.
- 기계 학습 모델: 학습 데이터에서 읽기 패턴을 학습하는 시퀀스 예측 모델 및 그래프 기반 접근 방식입니다.
지역 분류 는 다양한 유형의 텍스트 영역(머리글, 본문 텍스트, 캡션, 표)을 식별합니다.
- 기능 기반 분류자: 글꼴 크기, 위치 및 서식 지정과 같은 수공예 기능을 사용하여 SVM(벡터 머신) 지원
- 딥 러닝 모델: 레이블이 지정된 문서 데이터 세트에 대해 학습된 나선형 신경망 및 비전 변환기
4단계: 문자 인식 및 분류
개별 문자가 식별되는 OCR 프로세스의 핵심은 다음과 같습니다.
기능 추출: 각 문자 또는 기호의 모양, 크기 및 고유 특성을 분석합니다.
- 기존 방법: 모멘트, 푸리에 설명자 및 구조적 기능(루프, 엔드포인트, 교집합)과 같은 통계 기능
- 딥 러닝 접근 방식: 원시 픽셀 데이터에서 차별적인 기능을 자동으로 학습하는 나선형 신경망
패턴 일치: 추출된 기능을 다양한 글꼴, 크기 및 쓰기 스타일을 인식하는 학습된 모델과 비교합니다.
- 템플릿 일치: 상관 관계 기술을 사용하여 저장된 문자 템플릿과 직접 비교
- 통계적 분류자: HMM(Hidden Markov 모델), 지원 벡터 컴퓨터, 기능 벡터를 사용하는 K 가장 인접한 항목
- 신경망: 다중 계층 퍼셉트론, CNN 및 숫자 인식을 위한 LeNet과 같은 특수 아키텍처
- 고급 딥 러닝: 강력한 문자 분류를 위한 잔차 네트워크(ResNet), DenseNet 및 EfficientNet 아키텍처
컨텍스트 분석: 주변 문자와 단어를 사용하여 사전 조회 및 언어 모델을 통해 인식 정확도를 향상시킵니다.
- N-gram 모델: 확률 분포를 기반으로 문자 시퀀스를 예측하는 통계 언어 모델입니다.
- 사전 기반 수정: 맞춤법 교정을 위한 편집 거리 알고리즘(예: Levenshtein 거리)이 있는 Lexicon 조회입니다.
- 신경망 언어 모델: 컨텍스트 관계를 이해하는 LSTM 및 변환기 기반 모델(예: BERT 변형)
- 주의 메커니즘: 문자 예측을 수행할 때 입력의 관련 부분에 초점을 맞춘 변환기 모델입니다.
신뢰도 점수 매기기: 시스템이 식별에 대해 얼마나 확실한지에 따라 인식된 각 문자에 확률 점수를 할당합니다.
- Bayesian 접근 방식: 문자 예측의 불확실성을 정량화하는 확률적 모델입니다.
- Softmax 출력: 신경망 최종 계층 활성화가 확률 분포로 변환됩니다.
- 앙상블 메서드: 여러 모델의 예측을 결합하여 신뢰도 추정을 향상시킵니다.
5단계: 출력 생성 및 후처리
최종 단계에서는 인식 결과를 사용 가능한 텍스트 데이터로 변환합니다.
텍스트 컴파일: 개별 문자 인식을 전체 단어 및 문장으로 어셈블합니다.
- 규칙 기반 어셈블리: 공간 근접 및 신뢰도 임계값을 사용하여 문자 예측을 결합하는 결정적 알고리즘입니다.
- 시퀀스 모델: 텍스트를 순차 데이터로 모델링하는 RNN(되풀이 신경망) 및 LSTM(Long Short-Term Memory) 네트워크입니다.
- 주의 기반 모델: 가변 길이 시퀀스와 복잡한 텍스트 레이아웃을 처리할 수 있는 변환기 아키텍처입니다.
서식 유지: 단락, 줄 바꿈 및 간격을 포함하여 문서 구조를 유지합니다.
- 기하학적 알고리즘: 경계 상자 좌표 및 공백 분석을 사용하는 규칙 기반 시스템입니다.
- 레이아웃 이해 모델: 구조적 관계를 학습하는 그래프 신경망 모델 및 문서 인공 지능 모델.
- 다중 모달 변환기: 구조 유지를 위해 텍스트 및 레이아웃 정보를 결합하는 LayoutLM과 같은 모델입니다.
좌표 매핑: 원본 이미지 내에서 각 텍스트 요소의 정확한 위치를 기록합니다.
- 좌표 변환: 이미지 픽셀과 문서 좌표 간의 수학 매핑입니다.
- 공간 인덱싱: 효율적인 공간 쿼리를 위한 R-트리 및 쿼드 트리와 같은 데이터 구조입니다.
- 회귀 모델: 정확한 텍스트 위치 지정 좌표를 예측하도록 학습된 신경망.
품질 유효성 검사: 맞춤법 및 문법 검사를 적용하여 잠재적 인식 오류를 식별합니다.
- 사전 기반 유효성 검사: 포괄적인 단어 목록 및 특수 도메인 어휘를 조회합니다.
- 통계 언어 모델: 문법 및 컨텍스트 유효성 검사를 위한 N-gram 모델 및 확률 파서입니다.
- 신경망 언어 모델: OCR 오류 검색 및 수정을 위해 GPT 또는 BERT와 같은 미리 학습된 모델을 미세 조정합니다.
- 앙상블 유효성 검사: 여러 유효성 검사 방법을 결합하여 오류 검색 정확도를 향상시킵니다.