LLM 애플리케이션의 핵심 구성 요소 식별
LLM(대규모 언어 모델)은 인간의 언어를 이해하고 생성하도록 설계된 정교한 언어 처리 시스템과 같습니다. 자동차가 제대로 작동하려면 엔진, 연료 시스템, 변속기 및 스티어링 휠이 필요한 방법과 비슷하게 함께 작동하는 네 가지 필수 부품이 있다고 생각합니다.
- 프롬프트: 모델에 대한 지침입니다. 프롬프트는 LLM과 통신하는 방법입니다. 그것은 당신의 질문, 요청, 또는 지침입니다.
- Tokenizer: 언어를 구분합니다. tokenizer는 사용자 텍스트를 컴퓨터가 이해할 수 있는 형식으로 변환하는 언어 번역기입니다.
- 모델: 작업의 '브레인'입니다. 모델은 정보를 처리하고 응답을 생성하는 실제 '브레인'입니다. 일반적으로 변환기 아키텍처를 기반으로 하며, 자기 주의 메커니즘을 활용하여 텍스트를 처리하고, 상황에 맞는 응답을 생성합니다.
- 작업: LLM이 수행할 수 있는 작업 작업은 텍스트 분류, 번역 및 대화 상자 생성과 같이 LLM이 수행할 수 있는 다양한 언어 관련 작업입니다.
이러한 구성 요소는 강력한 언어 처리 시스템을 만듭니다.
- 프롬프트(지침)를 제공합니다 .
- 토케나이저는 이를 분해 합니다(컴퓨터에서 읽을 수 있도록 합니다).
- 모델은 이를 처리 합니다(변환기 아키텍처 및 자기 주의 사용).
- 모델은 작업을 수행합니다 (필요한 응답을 생성).
이 조정된 시스템은 LLM이 놀라운 정확도와 유창성으로 복잡한 언어 작업을 수행할 수 있게 해 줍니다. 이를 통해 고객 서비스에 대한 쓰기 지원부터 창의적인 콘텐츠 생성에 이르기까지 모든 작업에 유용합니다.
LLM이 수행하는 작업 이해
LLM은 광범위한 언어 관련 업무를 수행하도록 설계되었습니다. LLM은 텍스트와 컨텍스트에 대한 깊은 이해로 인해 자연어 처리 또는 NLP(1) 작업에 이상적입니다. NLP(자연어 처리)는 컴퓨터가 의미 있고 유용한 방식으로 인간의 언어를 이해하고 해석하고 생성할 수 있도록 하는 데 중점을 둔 인공 지능 분야입니다. LLM 작업의 컨텍스트에서 NLP는 텍스트 및 컨텍스트에 대한 깊은 이해로 인해 LLM 모델이 뛰어난 언어 관련 함수의 범주를 나타냅니다.
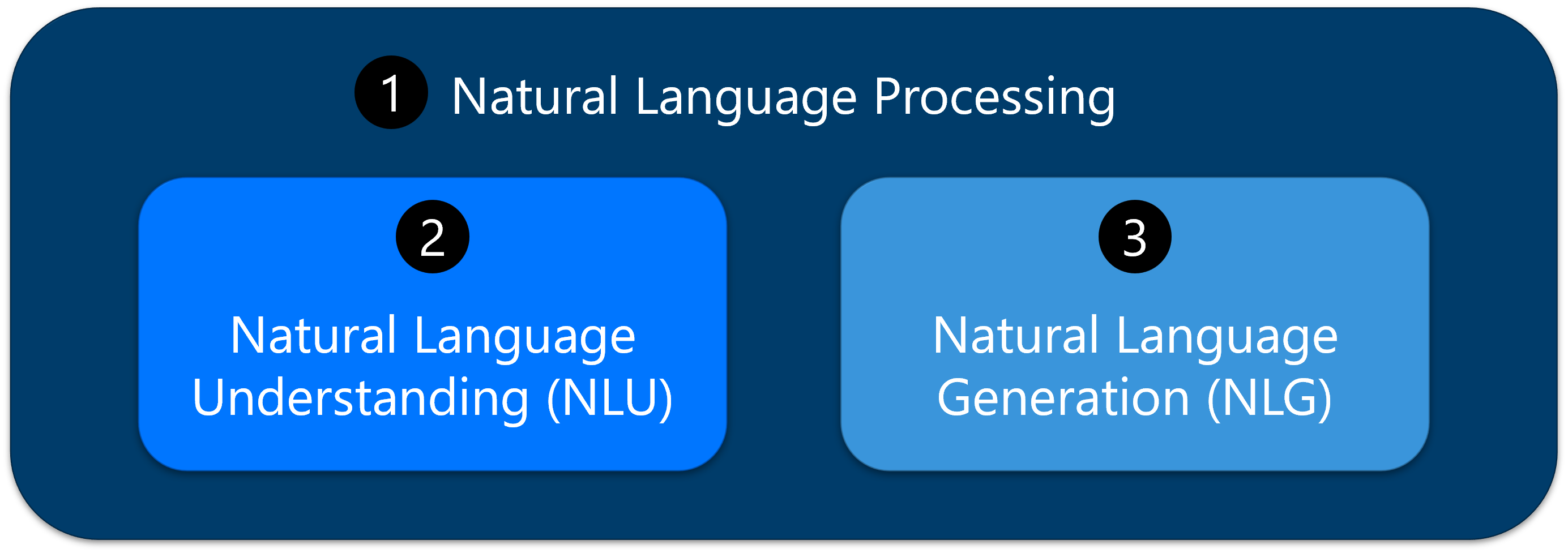
NLP 작업의 한 범주에는 자연어 이해 또는 NLU(2)가 포함되며, 여기에는 감정 분석, NER(명명된 엔터티 인식), 텍스트 분류와 같은 작업이 포함되며, 이러한 작업에는 의미를 추출하고 텍스트 내의 특정 요소를 식별하는 작업이 포함됩니다.
또 다른 NLP 작업 집합은 텍스트 완료, 요약, 번역 및 콘텐츠 만들기를 포함하는 자연어 생성 또는 NLG(3)에 속합니다. 여기서 모델은 지정된 입력을 기반으로 일관되고 상황에 맞는 적절한 텍스트를 생성합니다.
LLM은 대화 시스템과 대화형 에이전트에도 사용되어 사람과 비슷한 대화를 나누고 사용자 질의에 대해 적절하고 정확한 응답을 제공할 수 있습니다.
토크나이저의 중요도 이해
토큰화 는 LLM에서 중요한 전처리 단계입니다. 사용자 텍스트를 컴퓨터가 이해할 수 있는 형식으로 변환합니다. 텍스트는 토큰이라는 관리 가능한 단위로 세분 화됩니다. 토큰화 전략에 따라 이러한 토큰은 단어, 하위 단어 또는 개별 문자가 될 수 있습니다.
토큰화 프로세스는 다음과 같이 요약할 수 있습니다.
- 텍스트를 토큰으로 나누기: "Hello world"는 ["Hello", "world"] 또는 ["Hel", "lo", "wor", "ld"]가 될 수 있습니다.
- 다른 언어 처리: 영어, 스페인어, 중국어 등을 처리합니다.
- 처리 효율성을 높입니다. 더 작은 조각은 모델이 작업하기 쉽습니다.
- 숫자로 변환: 컴퓨터는 문자가 아닌 숫자로 작동하므로 "Hello"는 [7592, 1917]
BPE(바이트 쌍 인코딩) 및 WordPiece와 같은 최신 토크나이저는 드물거나 알려지지 않은 단어를 하위 단어 단위로 분할하여 모델이 어휘에 없는 용어를 보다 효과적으로 처리할 수 있도록 합니다.
예를 들어 다음 문장을 살펴봅니다.
I heard a dog bark loudly at a cat
이 텍스트를 토큰화하기 위해 각 불연속 단어를 식별하고 토큰 ID를 할당할 수 있습니다. 예를 들면 다음과 같습니다.
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- a (3)
- cat (8)
이제 문장을 토큰으로 나타낼 수 있습니다.
{1 2 3 4 5 6 7 3 8}
토큰화는 모델이 어휘 크기와 표현 효율성 간의 균형을 유지하는 데 도움이 되며, 다양한 텍스트 입력을 정확하게 처리할 수 있도록 보장합니다.
토큰화를 통해 모델은 텍스트를 학습 및 유추 중에 효율적으로 처리할 수 있는 숫자 형식으로 변환할 수도 있습니다.
기본 모델 아키텍처 이해
LLM의 아키텍처를 집의 청사진과 같이 생각하면 모든 부품이 어떻게 구성되고 함께 작동하여 기능적인 것을 만들 수 있는지를 보여줍니다.
LLM은 변환기 아키텍처 라는 항목을 사용하여 빌드됩니다. 책을 읽고 있으며 다른 문장이 서로 어떻게 관련되어 있는지 이해해야 한다고 상상해 보십시오. 기존의 접근 방식은 일반적으로 읽는 것과 같이 단어로 단어를 읽는 것입니다. 변환기 접근 방식에서는 전체 페이지를 한 번에 보고 모든 단어가 서로 연결되는 방식을 즉시 확인할 수 있습니다.
자기 주의 는 변압기 아키텍처에서 사용되는 주요 혁신입니다. 마치 각 문장을 이해하기 위해 가장 중요한 단어를 자동으로 표시하는 초 스마트 형광펜을 사용하는 것과 같습니다.
예를 들면 다음과 같습니다. "개가 흥분했기 때문에 공을 쫓아갔다"라는 문장에서 모델은 "개"가 문장의 앞부분에 나타나더라도 "개"가 "개"(공이 아님)를 가리킨다는 것을 알 수 있습니다.
변환기는 입력 텍스트를 분석하고 출력을 생성하기 위해 함께 작동하는 인코더와 디코더 계층으로 구성됩니다. 자기 주의 메커니즘을 통해 모델은 문장에서 다양한 단어의 중요도를 평가할 수 있어 장거리 종속성과 컨텍스트를 효과적으로 캡처할 수 있습니다.
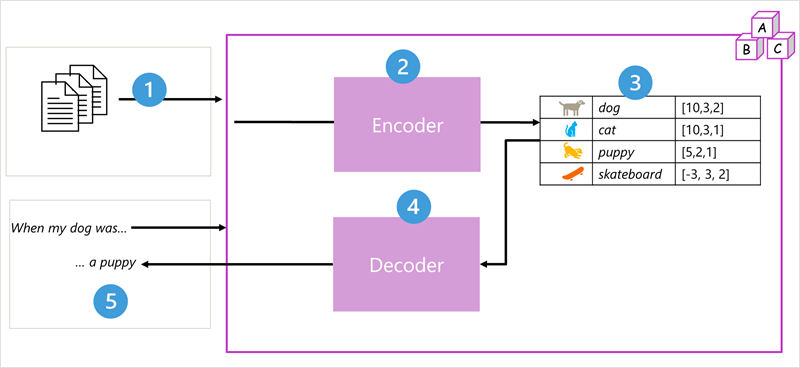
LLM 처리가 작동하는 방식의 예로 이 다이어그램을 사용하겠습니다.
LLM은 대량의 자연어 텍스트에서 학습됩니다.
1단계: 입력 - 교육 문서 및 프롬프트 "내 개가..." 시스템에 입력합니다.
2단계: 인코더(분석기) - 텍스트를 토큰 으로 구분하고 그 의미를 분석합니다. 인코더 블록은 자체 주의를 사용하여 토큰 또는 단어 간의 관계를 결정하는 토큰 시퀀스를 처리합니다.
3단계: 포함 만들기 - 인코더의 출력은 벡터 의 각 요소가 토큰의 의미 체계 특성을 나타내는 벡터(다중값 숫자 배열)의 컬렉션입니다. 이러한 벡터를 embeddings라고 합니다. 의미를 캡처하는 숫자 표현입니다.
- 개 [10,3,2] - 동물, 애완 동물, 주제
- 고양이 [10,3,1] - 동물, 애완 동물, 다른 종
- 강아지 [5,2,1] - 어린 동물, 개 관련
- 스케이트 보드 [-3,3,2] - 물체, 동물과 관련이 없는 물건
4단계: 디코더(기록기) - 디코더 블록은 새 텍스트 토큰 시퀀스에서 작동하며 인코더에서 생성된 포함을 사용하여 적절한 자연어 출력을 생성합니다. 옵션을 비교하고 가장 적절한 응답을 선택합니다.
5단계: 생성된 출력 - 다음과 같은
When my dog was입력 시퀀스가 지정된 경우 모델은 자기 주의 메커니즘을 사용하여 포함에 인코딩된 입력 토큰 및 의미 체계 특성을 분석하여 문장a puppy의 적절한 완성을 예측할 수 있습니다.
이 아키텍처는 병렬화가 가능하므로 대규모 데이터 세트를 학습하는 데 효율적입니다. 매개 변수 수로 정의되는 LLM의 크기는 언어 지식을 저장하고 복잡한 작업을 수행할 수 있는 용량을 결정합니다. 매개 변수를 언어 규칙과 패턴을 저장하는 수백만 또는 수십억 개의 작은 메모리 셀로 간주합니다. 메모리 셀이 많을수록 모델은 언어에 대해 더 많이 기억하고 더 어려운 작업을 처리할 수 있습니다. GPT-3 및 GPT-4와 같은 대형 모델에는 수십억 개의 매개 변수가 포함되어 있어 방대한 언어 지식을 저장할 수 있습니다.
프롬프트의 중요도 이해
프롬프트는 LLM에게 응답을 안내하기 위해 제공되는 초기 입력입니다. 4개의 LLM 구성 요소(프롬프트, 토케나이저, 모델, 출력)가 모두 효과적으로 함께 작동하도록 하는 도체입니다. 프롬프트의 품질과 명확성은 모델의 성능에 크게 영향을 미치며, 잘 구성된 프롬프트는 보다 정확하고 관련 있는 응답으로 이어질 수 있습니다.
모델에서 원하는 결과를 가져오려면 효과적인 프롬프트를 작성해야 합니다. 프롬프트는 간단한 지침에서 복잡한 쿼리까지 다양하며, 모델은 프롬프트에 제공된 컨텍스트와 정보를 기반으로 텍스트를 생성합니다.
예를 들어, 프롬프트는 다음과 같습니다.
Translate the following English text to French: "Hello, how are you?"
표준 프롬프트 외에도 프롬프트 엔지니어링과 같은 기술에는 특정 작업이나 애플리케이션에 대한 모델의 출력을 향상시키기 위해 프롬프트를 개선하고 최적화하는 작업이 포함됩니다.
보다 자세한 지침이 제공되는 프롬프트 엔지니어링의 예:
Generate a creative story about a time-traveling scientist who discovers a new planet. Include elements of adventure and mystery.
작업, 토큰화, 모델, 프롬프트 간의 상호 작용은 LLM을 매우 강력하고 다재다능하게 만듭니다. 효과적인 토큰화가 있으면 다양한 작업을 수행하는 모델의 기능이 개선되어 텍스트 입력이 정확하게 처리됩니다. 변환기 기반 아키텍처를 통해 모델은 토큰과 프롬프트에서 제공된 컨텍스트를 기반으로 텍스트를 이해하고 생성할 수 있습니다.