GitHub Copilot LLM(대규모 언어 모델)
GitHub Copilot은 LLM(대규모 언어 모델)을 기반으로 하여 코드를 원활하게 작성하는 데 도움을 줍니다. 이 단원에서는 GitHub Copilot에서 LLM의 통합 및 영향을 이해하는 데 중점을 두고 있습니다. 다음 항목을 검토해 보겠습니다.
- LLM이란?
- GitHub Copilot에서 LLM의 역할 및 프롬프트
- LLM 미세 조정
- LoRA 미세 조정
LLM이란?
LLM(대규모 언어 모델)은 인간 언어를 이해, 생성 및 조작하도록 설계되고 학습된 인공 지능 모델입니다. 이러한 모델에는 학습된 방대한 양의 텍스트 데이터 덕분에 텍스트와 관련된 광범위한 작업을 처리할 수 있는 기능이 내장되어 있습니다. LLM에 대해 이해해야 할 몇 가지 핵심 측면은 다음과 같습니다.
학습 데이터의 양
LLM은 다양한 원본의 방대한 양의 텍스트에 노출됩니다. 이러한 노출을 통해 학생들은 다양한 형태의 의사 소통과 관련된 언어, 컨텍스트 및 복잡성에 대한 폭넓은 이해를 갖추게 됩니다.
상황에 따른 이해
상황에 맞게 적절하고 일관된 텍스트를 생성하는 데 탁월합니다. 컨텍스트를 이해하는 기능을 통해 문장, 단락을 완료하거나 컨텍스트에 맞는 전체 문서를 생성하는 등 의미 있는 기여를 할 수 있습니다.
기계 학습 및 AI 통합
LLM은 기계 학습 및 인공 지능 원리를 기반으로 합니다. 이는 텍스트를 효과적으로 이해하고 예측하기 위해 학습 과정에서 미세 조정되는 수백만, 심지어 수십억 개의 매개 변수를 갖춘 신경망입니다.
다양성
이러한 모델은 특정 형식의 텍스트나 언어로 제한되지 않습니다. 전문적인 작업을 수행하기 위해 맞춤화되고 미세 조정될 수 있으므로 다양한 도메인과 언어에 걸쳐 매우 다재다능하고 적용 가능합니다.
GitHub Copilot에서 LLM의 역할 및 프롬프트
GitHub Copilot은 LLM을 활용하여 상황 인식 코드 제안을 제공합니다. LLM은 현재 파일뿐만 아니라 IDE에 열려 있는 다른 파일과 탭도 고려하여 정확하고 관련성이 높은 코드 완료를 생성합니다. 이러한 동적 방식은 맞춤형 제안을 보장하여 생산성을 개선시킵니다.
LLM 미세 조정
미세 조정은 특정 작업이나 도메인에 대해 미리 학습된 LLM(대규모 언어 모델)을 맞춤화할 수 있는 중요한 프로세스입니다. 여기에는 원본 모델이라고 하는 미리 학습된 대규모 데이터 세트에서 가져오는 지식과 매개 변수를 사용하는 동시에 대상 데이터 세트로 알려진 더 작은 작업별 데이터 세트에 대한 모델 학습이 포함됩니다.
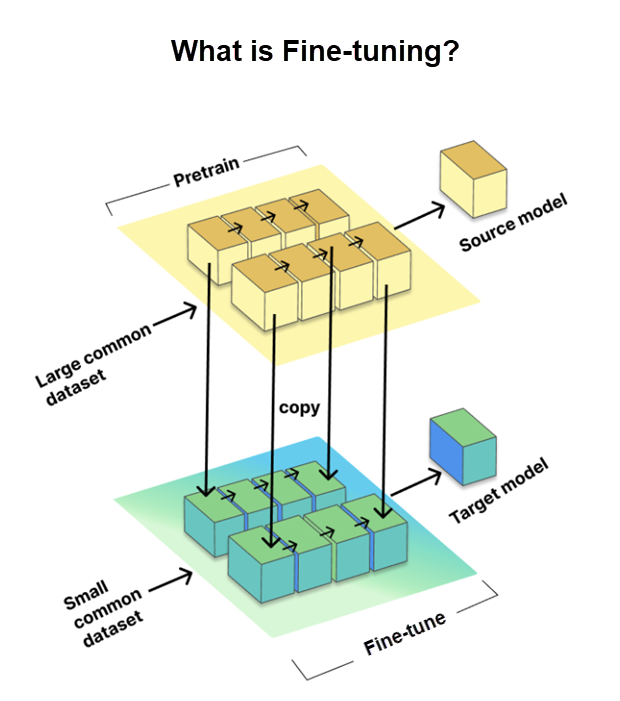
LLM을 특정 작업에 맞게 튜닝하여 성능을 향상시키려면 미세 조정이 필수적입니다. 그러나 GitHub는 다음에 설명하는 LoRA 미세 조정 방법을 사용하여 한 단계 더 발전했습니다.
LoRA 미세 조정
전통적인 완전 미세 조정은 느리고 리소스에 크게 의존할 수 있는 신경망의 모든 파트를 학습하는 것을 의미합니다. 하지만 LoRA(하위 순위 적응) 미세 조정은 현명한 대안입니다. 모든 학습을 다시 수행하지 않고도 대규모 미리 학습된 언어 모델(LLM)이 특정 작업에 더 잘 작동하도록 만드는 데 사용됩니다.
LoRA의 작동 방식은 다음과 같습니다.
- LoRA는 모든 항목을 변경하는 대신 미리 학습된 모델의 각 계층에 더 작은 학습 가능한 부품을 추가합니다.
- 원본 모델은 동일하게 유지되므로 시간과 리소스가 절약됩니다.
LoRA의 장점:
- 이는 어댑터 및 접두사 튜닝과 같은 다른 적응 방법보다 뛰어납니다.
- 움직이는 파트 수가 적어서 좋은 결과를 가져오는 것과 같습니다.
간단히 말해서 LoRA 미세 조정은 Copilot을 사용할 때 특정 코딩 요구 사항에 맞게 LLM을 개선하기 위해 더 스마트하게 작업하는 것입니다.