Azure Stack HCI 클러스터 쿼럼 구성
최근 Contoso의 온-프레미스 데이터 센터에서 발생한 하드웨어 장애 및 정전에서 고가용성 프로비전 부족을 포함하여 더 중요한 내부 개발 애플리케이션 중 일부가 구현된 방식에서 결함이 드러났습니다. Azure Stack HCI 평가의 일환으로 구현이 이러한 프로비전의 필요성을 고려하는지 확인하려고 합니다. 이 목표를 달성하기 위해 Azure Stack HCI의 클러스터 쿼럼 및 감시 개념을 탐색하고 최적의 구성을 찾기로 결정합니다.
Azure Stack HCI 클러스터의 클러스터 쿼럼 및 클러스터 감시 개요
Azure Stack HCI는 Windows Server 장애 조치(Failover) 클러스터링 운영 체제 기능을 사용하여 고가용성 기능을 구현합니다. 장애 조치(failover) 클러스터에서 쿼럼은 해당 클러스터가 온라인 상태를 유지하는 데 사용할 수 있어야 하는 클러스터링 구성 요소 수입니다. 이러한 구성 요소에는 클러스터 노드 및 감시가 포함될 수 있습니다. 감시는 쿼럼을 설정하고 유지 관리하는 데 도움이 되는 리소스입니다.
참고
쿼럼의 목적은 ‘스플릿 브레인’ 시나리오를 방지하는 것입니다. 이러한 시나리오에서는 노드 간 연결 문제로 인해 클러스터의 두 노드 집합이 독립적으로 작동하기 시작하여 클러스터 상태 및 리소스가 손상됩니다.
각 구성 요소와 연결된 투표 수와 및 쿼럼 메커니즘에 따라 쿼럼을 결정할 수 있습니다. Azure Stack HCI에는 두 가지 쿼럼 메커니즘이 포함됩니다.
클러스터 쿼럼 - 클러스터 수준에서 작동하며 노드 및 미러링 모니터의 투표를 기반으로 합니다. 이러한 감시를 파일 공유로 구현하거나 Azure Storage 계정의 Blob으로 구현할 수 있습니다.
참고
Azure Stack HCI는 디스크 감시를 지원하지 않습니다.
풀 쿼럼 - 스토리지 풀 수준에서 작동하며 노드 및 스토리지 복원력의 투표를 기반으로 합니다. 풀 쿼럼은 스토리지 풀 리소스를 소유하는 노드를 감시로 지정합니다.
다음 표에서는 노드 수 및 감시 존재를 기반으로 한 클러스터 복원력을 간략하게 설명합니다.
| 서버 노드 | 한 번의 서버 노드 오류에서 살아남을 수 있음 | 서버 노드 오류 한 번, 다른 서버 노드 오류 한 번에서 살아남을 수 있음 | 두 번의 동시 서버 노드 오류에서 살아남을 수 있음 |
|---|---|---|---|
| 2 | 50/50 | 아니요 | 예 |
| 2+ 감시 | 예 | 없음 | 예 |
| 3 | 예 | 50/50 | 아니요 |
| 3+ 감시 | 예 | 네 | 예 |
| 4 | 예 | 예 | 50/50 |
| 4+ 감시 | 예 | 네 | 예 |
| 5 이상 | 예 | 네 | 예 |
다음 표에서는 노드 수 및 감시 존재를 기반으로 한 풀 쿼럼 복원력을 간략하게 설명합니다.
| 서버 노드 | 한 번의 서버 노드 오류에서 살아남을 수 있음 | 서버 노드 오류 한 번, 다른 서버 노드 오류 한 번에서 살아남을 수 있음 | 두 번의 동시 서버 노드 오류에서 살아남을 수 있음 |
|---|---|---|---|
| 2 | 아니요 | 아니요 | 예 |
| 2+ 감시 | 예 | 없음 | 예 |
| 3 | 예 | 없음 | 예 |
| 3+ 감시 | 예 | 없음 | 예 |
| 4 | 예 | 없음 | 예 |
| 4+ 감시 | 예 | 네 | 예 |
| 5 이상 | 예 | 네 | 예 |
참고
스토리지 공간 다이렉트는 클러스터 크기에 관계없이 감시가 포함된 4개 이상의 노드에 대해 최대 두 개의 동시 노드 장애를 허용합니다.
참고
Azure Stack HCI 클러스터의 기능은 쿼럼뿐만 아니라 클러스터 노드에서 사용할 수 있는 리소스 및 해당 노드로 장애 조치(failover)되는 클러스터된 워크로드를 실행하는 기능에도 의존합니다. 예를 들어 5개 노드로 구성된 클러스터는 2개의 노드에 장애가 발생하더라도 쿼럼이 계속 유지됩니다. 그러나 나머지 각 클러스터 노드는 남은 3개 노드로 장애 조치(failover)된 클러스터 역할을 실행하는 데 충분한 리소스가 있는 경우에만 클라이언트에 서비스를 계속 제공합니다. 이러한 리소스에는 스토리지, 처리 능력, 네트워크 대역폭 및 메모리가 포함됩니다.
Windows Admin Center를 사용하여 Azure Stack HCI 클러스터 감시 구성
클러스터 감시를 파일 공유로 구성하거나 Azure Storage 계정의 Blob으로 구성할 수 있지만 클러스터가 스토리지 계정을 호스트하는 Azure 지역에 대한 안정적인 네트워크 연결을 유지하는 한 Blob 옵션을 권장합니다. 이 방법은 더 높은 복원력을 제공하여 확대 클러스터를 사용할 때 재해 복구가 용이해집니다. 이는 다음 학습 단원에 설명되어 있습니다.
이러한 유형의 구성을 클라우드 감시라고 하며, 이를 설정하는 가장 간단한 방법은 Windows Admin Center를 사용하는 것입니다. 개략적인 설정 단계는 다음과 같습니다.
클라우드 감시 Blob을 포함하는 Azure Storage 계정을 호스트할 Azure 구독에 연결합니다.
Azure 구독에서 LRS(로컬 중복 스토리지) 복제 설정으로 구성된 범용 v1 또는 범용 v2 Azure Storage 계정을 만듭니다.
스토리지 계정과 연결된 두 액세스 키 중 하나의 값을 검색합니다. Azure Portal의 스토리지 계정 블레이드에서 직접 키 값을 식별할 수 있습니다.

Windows Admin Center를 사용하여 Azure Stack HCI 클러스터에 연결합니다.
스토리지 계정 이름과 해당 액세스 키 중 하나를 제공하여 Windows Admin Center의 클러스터 관리자 인터페이스에서 클라우드 감시 쿼럼을 구성합니다.
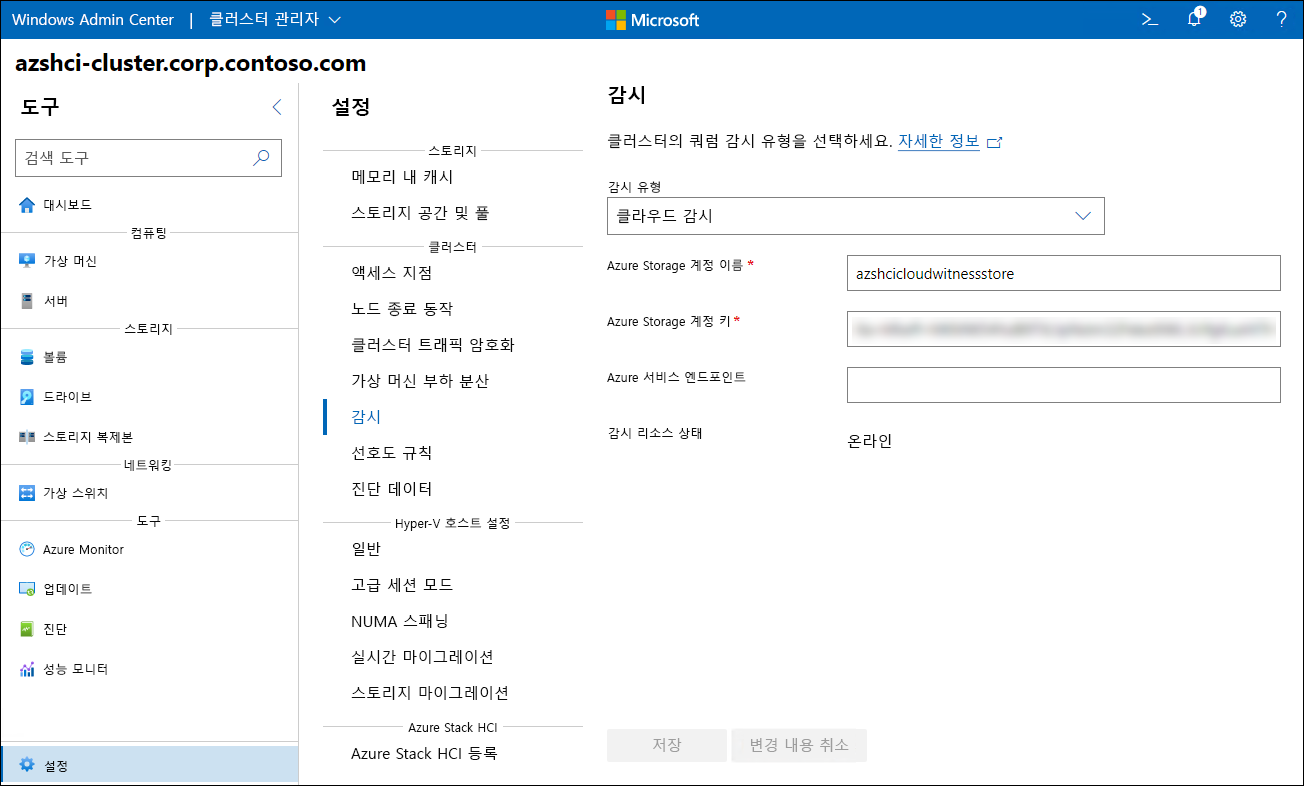
데모: Azure Stack HCI에서 클라우드 감시 구성
이 데모에서는 Azure Stack HCI에서 클라우드 감시를 구성하는 방법을 알아봅니다.