연습 - 조인 연산자를 사용하여 테이블 결과를 결합합니다.
이 연습에서는 join 연산자를 사용하는 방법을 알아봅니다. join 연산자는 각 테이블에서 지정된 열의 값을 일치시켜 두 테이블의 행을 병합합니다.
join 연산자의 결과를 사용하여 영업에 대한 질문에 답변해 보겠습니다.
join 연산자 사용
소매 회사 시나리오에서 팀은 판매액이 가장 많은 3개 국가/지역을 나열하도록 요청합니다.
SalesFact 표 검사를 시작할 때 필요한 수치는 SalesAmount 열에서 사용할 수 있지만 이 표에는 국가/지역 데이터가 포함되어 있지 않습니다. 다른 표를 살펴보면 Customers 표의 RegionCountryName 열에서 국가/지역 데이터를 사용할 수 있습니다. 또한 두 표에는 CustomerKey 열도 있습니다.
데이터는 두 표에 분산되므로 요청된 정보를 제공하는 쿼리를 작성하려면 고객 데이터와 판매 데이터가 모두 필요합니다. 쿼리를 작성하려면 연산자와 joinCustomerKey 열을 사용하여 두 표의 행을 일치시킵니다.
이제 쿼리를 작성할 준비가 되었습니다. inner join을 사용하여 두 표에서 일치하는 모든 행을 가져옵니다. 최상의 성능을 위해 고객 차원 표를 왼쪽 테이블로 사용하고 판매 팩트 표를 오른쪽 표로 사용합니다.
다음 절차에서는 join 연산자를 사용한 결과를 더 잘 이해할 수 있도록 쿼리를 단계별로 빌드합니다.
다음 쿼리를 실행하여 SalesFact 표 및 Customers 표에서 일치하는 10개의 임의의 행을 가져옵니다.
Customers | join kind=inner SalesFact on CustomerKey | take 10결과 목록을 살펴보세요. 결과 표에는 SalesFact 표의 열과 Customers 표의 일치하는 열이 포함됩니다.
다음 쿼리를 실행하여 조인된 테이블을 요약하고 판매액이 가장 많은 3개 국가/지역을 가져옵니다.
Customers | join kind=inner SalesFact on CustomerKey | summarize TotalAmount = round(sum(SalesAmount)) by RegionCountryName | top 3 by TotalAmount결과는 다음 이미지와 같아야 합니다.

결과 목록을 살펴보세요. 쿼리를 수정하여 해당 국가/지역의 총 비용 및 수익도 표시해 보세요.
그런 다음, 팀은 최근 기록된 연도의 수익이 가장 낮은 국가/지역을 월별로 식별하도록 요청합니다. 이 데이터를 가져오려면 비슷한 쿼리를 사용합니다. 그러나 이번에는 함수를 startofmonth() 사용하여 월별 그룹화가 용이합니다. 또한 arg_min() 집계 함수를 사용하여 매월 수익이 가장 낮은 국가/지역을 찾습니다.
다음 쿼리를 실행합니다.
Customers | join kind=inner SalesFact on CustomerKey | summarize TotalAmount = round(sum(SalesAmount)) by Month = startofmonth(DateKey), RegionCountryName | summarize arg_min(TotalAmount, RegionCountryName) by Month | top 12 by Month desc결과는 다음 이미지와 같아야 합니다.

각 열을 살펴봅니다. 첫 번째 열은 지난 해의 월을 내림차순으로 표시한 다음, 해당 월의 판매 수가 가장 낮은 국가/지역의 총 판매액을 보여 주는 열을 표시합니다.
rightouter join 종류 사용
영업 팀은 제품 범주별 총 매출을 알고자 합니다. 사용 가능한 데이터를 검토하기 시작하면 제품 범주 목록을 가져오는 Products 표와 판매 데이터를 가져오는 SalesFact 표가 필요하다는 것을 알게 될 것입니다. 또한 각 범주의 매출을 계산하고 모든 제품 범주를 나열하려고 합니다.
요청을 분석한 후에는 오른쪽 표의 모든 판매 레코드를 반환하고 왼쪽 표의 일치하는 데이터 제품 범주로 보강되므로 rightouter join을 사용하도록 선택합니다. Products 표를 왼쪽 차원 표를 사용하고, SalesFact 팩트 표를 데이터를 일치시키고, 제품 범주별로 결과를 그룹화하여 쿼리를 작성합니다.
다음 쿼리를 실행합니다.
Products | join kind=rightouter SalesFact on ProductKey | summarize TotalSales = count() by ProductCategoryName | order by TotalSales desc결과는 다음 이미지와 같아야 합니다.
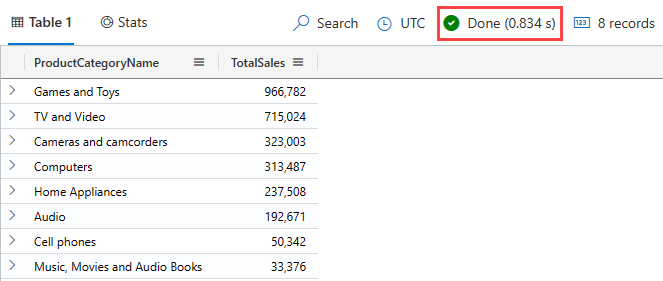
실행 시간은 0.834초이지만 이 시간은 실행마다 다를 수 있습니다. 이 쿼리는 이 답변을 가져오는 한 가지 방법이며 성능에 최적화되지 않은 쿼리의 좋은 예입니다. 이후 이 데이터 형식에 최적화된
lookup연산자를 사용하여 이 시간을 해당 쿼리의 실행 시간과 비교할 수 있습니다.
rightanti join 종류 사용
마찬가지로 영업 팀은 각 제품 범주에서 판매하지 않는 제품의 수를 알고 싶어 합니다. rightanti join을 사용하여 SalesFacts 표의 행과 일치하지 않는 Products 표의 모든 행을 가져와서 제품 범주별로 결과를 그룹화할 수 있습니다.
다음 쿼리를 실행합니다.
SalesFact | join kind=rightanti Products on ProductKey | summarize Count = count() by ProductCategoryName | order by Count desc결과는 다음 이미지와 같아야 합니다.

각 열을 살펴봅니다. 결과에는 제품 범주당 미분양 제품 수가 표시됩니다. rightanti
join은 판매 팩트가 없는 제품만 선택하여join연산자가 반환한 제품에 대한 판매가 없음을 나타냅니다.