조기 종료 구성
하이퍼 매개 변수 튜닝을 사용하면 모델을 미세 조정하고 모델의 성능이 최적화되도록 하이퍼 매개 변수 값을 선택할 수 있습니다.
하지만 최상의 모델을 찾는 것은 끝없는 과정이 될 수 있습니다. 더 나은 성능을 발휘할 수 있는 모델을 찾기 위해 새 하이퍼 매개 변수 값을 테스트하는 데 어느 정도의 시간과 비용이 드는지 항상 고려해야 합니다.
스윕 작업의 각 시도에서 새 모델은 하이퍼 매개 변수 값의 새로운 조합으로 학습됩니다. 새 모델을 학습해도 훨씬 더 나은 모델이 되지 않는 경우 스윕 작업을 중지하고 지금까지 가장 괜찮았던 모델을 사용할 수 있습니다.
Azure Machine Learning에서 스윕 작업을 구성할 때 최대 시도 수를 설정할 수도 있습니다. 더 정교한 방법은 최신 모델이 훨씬 더 나은 결과를 생성하지 않을 때 스윕 작업을 중지하는 것입니다. 모델의 성과를 기반으로 스윕 작업을 중지하려면 조기 종료 정책을 사용할 수 있습니다.
조기 종료 정책을 사용하는 경우
조기 종료 정책을 사용할지 여부는 사용 중인 검색 공간 및 샘플링 방법에 따라 달라질 수 있습니다.
예를 들어 그리드 샘플링 방법과 불연속 검색 공간을 사용하면 최대 6회의 시도가 이루어질 수 있습니다. 6회의 시도를 통해 최대 6개의 모델이 학습되고 조기 종료 정책이 필요하지 않을 수 있습니다.
조기 종료 정책은 검색 공간에서 연속 하이퍼 매개 변수를 사용할 때 특히 도움이 될 수 있습니다. 연속 하이퍼 매개 변수는 선택할 수 있는 값의 수를 무제한으로 제공합니다. 연속 하이퍼 매개 변수와 임의 또는 베이지언 샘플링 방법을 사용할 때 조기 종료 정책을 사용할 가능성이 가장 높습니다.
조기 종료 정책 구성
조기 종료 정책을 사용하는 경우 두 가지 주요 매개 변수가 있습니다.
evaluation_interval: 정책을 평가할 간격을 지정합니다. 시도에 대한 기본 메트릭이 로그될 때마다 간격으로 계산됩니다.delay_evaluation: 정책 평가를 시작할 시기를 지정합니다. 이 매개 변수를 사용하면 조기 종료 정책이 영향을 미치지 않으면서 최소 한 번의 시도를 완료할 수 있습니다.
새 모델은 이전 모델에 비해 약간만 더 나은 성능을 보일 수 있습니다. 모델이 이전 평가판보다 어느 정도 성능이 나아져야 하는지 결정하기 위해 세 가지 조기 종료 옵션이 있습니다.
- 산적 정책:
slack_factor(상대) 또는slack_amount(절대)를 사용합니다. 모든 새 모델은 성능이 가장 뛰어난 모델의 Slack 범위 내에서 성과를 보여야 합니다. - 중앙값 중지 정책: 기본 메트릭의 평균 중앙값을 사용합니다. 새 모델은 중앙값보다 성능이 높아야 합니다.
- 잘림 선택 정책: 성능이 가장 저조한 시도의 비율인
truncation_percentage를 사용합니다. 모든 새 모델은 성능이 가장 떨어지는 시도보다 성능이 높아야 합니다.
산적 정책
대상 성능 메트릭이 지정된 범위를 기준으로 지금까지 가장 적합한 시도를 수행하지 않은 경우에는 산적 정책을 사용하여 시도를 중지할 수 있습니다.
예를 들어 다음 코드는 5번의 시도 지연이 포함된 산적 정책을 적용하고, 간격마다 정책을 평가하며, 절대 Slack 시간(0.2)을 허용합니다.
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(
slack_amount = 0.2,
delay_evaluation = 5,
evaluation_interval = 1
)
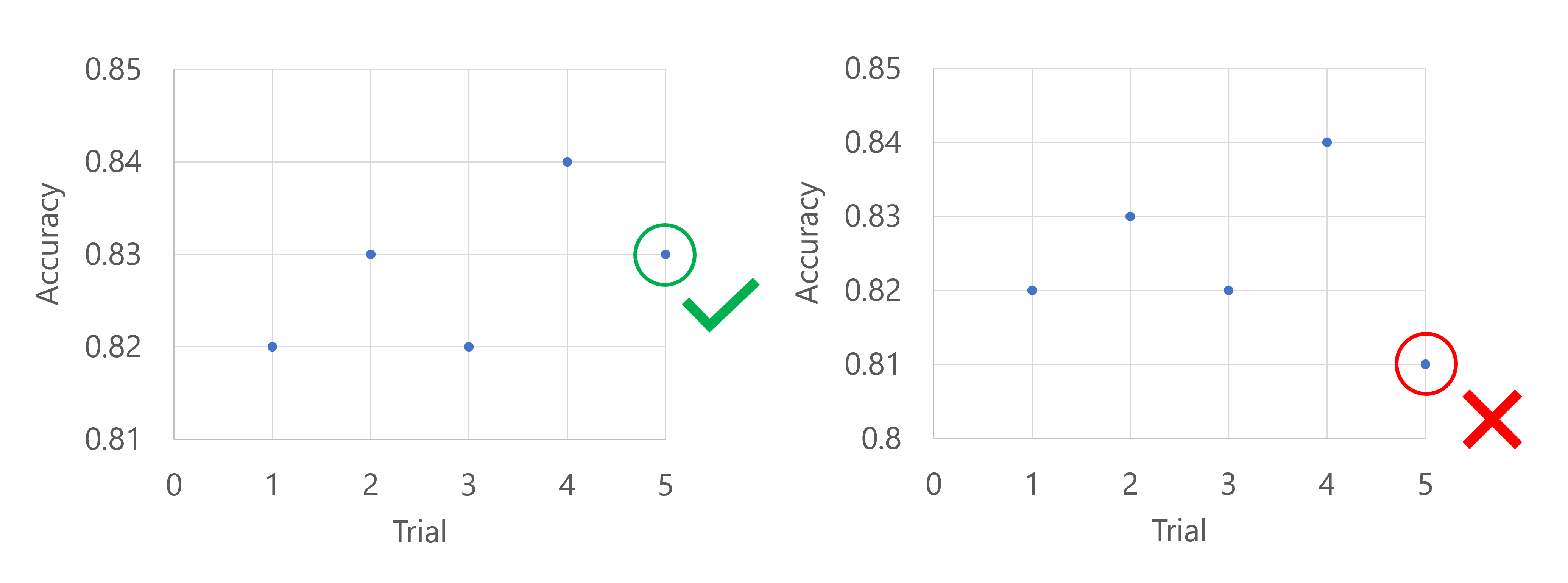
기본 메트릭이 모델의 정확도라고 상상해 보세요. 처음 다섯 번의 시도 후에 가장 성능이 좋은 모델의 정확도가 0.9이면 모든 새 모델은 (0.9-0.2), 즉 0.7보다 더 나은 성능을 보여야 합니다. 새 모델의 정확도가 0.7보다 높으면 스윕 작업이 계속됩니다. 새 모델의 정확도 점수가 0.7보다 낮은 경우 정책에서 스윕 작업을 종료합니다.
또한 성능 메트릭을 절대값이 아닌 비율로 비교하는 여유 요소를 사용하여 산적 정책을 적용할 수 있습니다.
중앙값 중지 정책
중앙값 중지 정책은 대상 성능 메트릭이 모든 시도에 대한 실행 평균의 중간값보다 좋지 않은 시도를 중지합니다.
예를 들어 다음 코드는 5회 시도의 지연이 포함된 중앙값 중지 정책을 적용하고 매 간격마다 정책을 평가합니다.
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation = 5,
evaluation_interval = 1
)
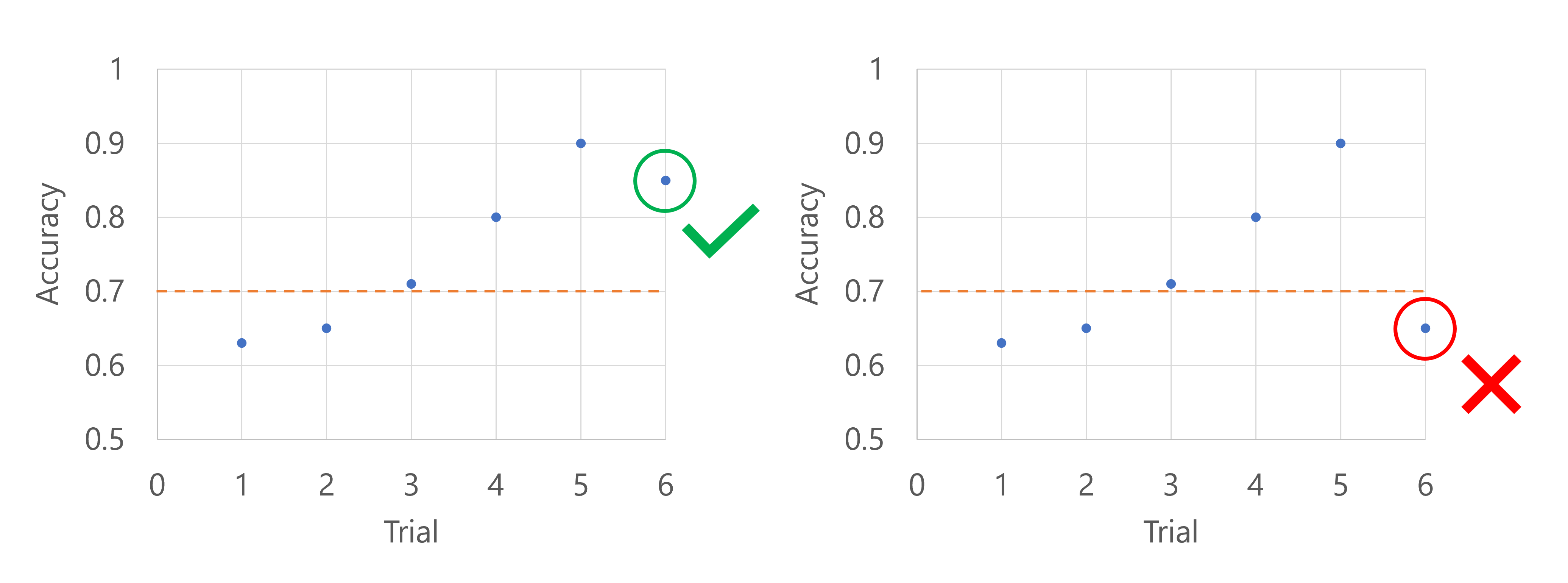
기본 메트릭이 모델의 정확도라고 상상해 보세요. 여섯 번째 시도에 대한 정확도를 기록할 때 메트릭은 지금까지 정확도 점수의 중앙값보다 높아야 합니다. 지금까지 정확도 점수의 중앙값이 0.82라고 가정합니다. 새 모델의 정확도가 0.82보다 높으면 스윕 작업이 계속됩니다. 새 모델의 정확도 점수가 0.82보다 낮으면 정책에서 스윕 작업을 중지하고 새 모델은 학습되지 않습니다.
잘림 선택 영역 정책
잘림 선택 영역 정책은 X에 대해 지정한 truncation_percentage 값을 기준으로 하여 각 평가 간격에 가장 낮게 수행되는 X%의 시도를 취소합니다.
예를 들어 다음 코드는 4회의 시도 지연이 포함된 잘림 선택 정책을 적용하고, 간격마다 정책을 평가하며, 잘림 비율 20%를 사용합니다.
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(
evaluation_interval=1,
truncation_percentage=20,
delay_evaluation=4
)
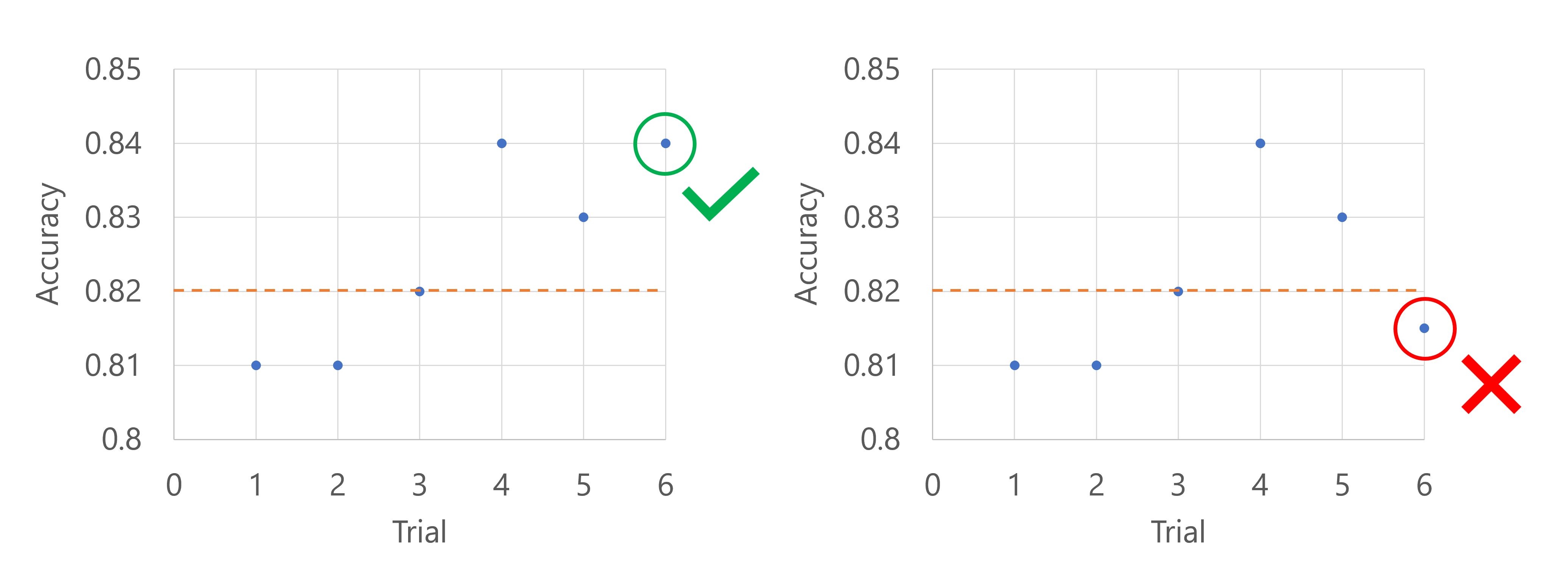
기본 메트릭이 모델의 정확도라고 상상해 보세요. 다섯 번째 시도에 대한 정확도가 로그되면 메트릭은 지금까지 시도의 최하 20%에 속하지 않아야 합니다. 이 경우 20%는 한 번의 시도로 해석됩니다. 즉, 다섯 번째 시도는 지금까지 성능이 가장 떨어지는 모델이 아닌 경우 스윕 작업은 계속됩니다. 다섯 번째 시도가 지금까지 모든 시도 중 정확도 점수가 가장 낮으면 스윕 작업이 중지됩니다.