연습: 기계 학습 모델 학습
정상적 제조 디바이스와 오류가 발생한 제조 디바이스에서 센서 데이터를 수집했습니다. 이제 Model Builder를 사용하여 머신에 오류가 발생할지 여부를 예측하는 기계 학습 모델을 학습시키려 합니다. 기계 학습을 사용하여 이러한 디바이스에 대한 모니터링을 자동화하면 적시에 안정적인 유지 관리를 제공하여 회사 비용을 절감할 수 있습니다.
새 기계 학습 모델(ML.NET) 항목 추가
학습 프로세스를 시작하려면 새 "기계 학습 모델(ML.NET)" 항목을 기존 또는 새 .NET 애플리케이션에 추가해야 합니다.
C# 클래스 라이브러리 만들기
처음부터 시작하므로 기계 학습 모델을 추가할 새 C# 클래스 라이브러리 프로젝트를 만듭니다.
Visual Studio를 시작합니다.
시작 창에서 새 프로젝트 만들기를 선택합니다.
새 프로젝트 만들기 대화 상자에서 검색창에 class library를 입력합니다.
옵션 목록에서 클래스 라이브러리를 선택합니다. 언어가 C#인지 확인하고 다음을 선택합니다.
프로젝트 이름 텍스트 상자에 PredictiveMaintenance를 입력합니다. 나머지 필드는 기본값으로 두고 다음을 선택합니다.
프레임워크 드롭다운 목록에서 .NET 6.0(미리 보기)을 선택한 다음 만들기를 선택하여 C# 클래스 라이브러리를 스캐폴드합니다.

프로젝트에 기계 학습 추가
클래스 라이브러리 프로젝트가 Visual Studio에서 열리면 기계 학습을 추가해야 합니다.
Visual Studio 솔루션 탐색기에서 프로젝트를 마우스 오른쪽 단추로 클릭합니다.
추가>기계 학습 모델을 선택합니다.
새 항목 추가 대화 상자의 새 항목 목록에서 기계 학습 모델(ML.NET)을 선택합니다.
이름 텍스트 상자에 모델 이름으로 PredictiveMaintenanceModel.mbconfig를 입력하고 추가를 선택합니다.


몇 초 후에 PredictiveMaintenanceModel.mbconfig라는 파일이 프로젝트에 추가됩니다.
시나리오 선택
프로젝트에 기계 학습 모델을 처음 추가하면 Model Builder 화면이 열립니다. 이제 시나리오를 선택해야 합니다.
사용 사례에 대해 머신이 손상되었는지 여부를 확인하려고 합니다. 두 가지 옵션만 있고 머신의 상태를 확인하려고 하므로 데이터 분류 시나리오가 가장 적합합니다.
Model Builder 화면의 시나리오 단계에서 데이터 분류 시나리오를 선택합니다. 이 시나리오를 선택하면 환경 단계로 바로 이동하게 됩니다.

환경 선택
데이터 분류 시나리오의 경우 CPU를 사용하는 로컬 환경만 지원됩니다.
- Model Builder 화면의 환경 단계에서는 기본적으로 로컬(CPU)이 선택됩니다. 기본 환경을 선택된 상태로 둡니다.
- 다음 단계를 선택합니다.

데이터 로드 및 준비
시나리오와 학습 환경을 선택했으므로 이제 Model Builder를 사용하여 수집한 데이터를 로드하고 준비해야 합니다.
데이터 준비
선택한 텍스트 편집기에서 파일을 엽니다.
원래 열 이름에는 특수 대괄호 문자가 포함됩니다. 데이터 구문 분석 문제를 방지하려면 열 이름에서 특수 문자를 제거합니다.
원래 헤더:
UDI,Product ID,Type,Air temperature [K],Process temperature [K],Rotational speed [rpm],Torque [Nm],Tool wear [min],Machine failure,TWF,HDF,PWF,OSF,RNF업데이트된 헤더:
UDI,Product ID,Type,Air temperature,Process temperature,Rotational speed,Torque,Tool wear,Machine failure,TWF,HDF,PWF,OSF,RNFai4i2020.csv 파일을 변경 내용과 함께 저장합니다.
데이터 원본 형식 선택
예측 유지 관리 데이터 세트는 CSV 파일입니다.
Model Builder 화면의 데이터 단계에서 데이터 원본 형식으로 파일(csv, tsv, txt)을 선택합니다.
데이터의 위치 제공
찾아보기 단추를 선택하고 파일 탐색기를 사용하여 ai4i2020.csv 데이터 세트의 위치를 제공합니다.
레이블 열 선택
예측할 열(레이블) 드롭다운 목록에서 머신 오류를 선택합니다.

고급 데이터 옵션 선택
기본적으로 레이블이 아닌 모든 열은 기능으로 사용됩니다. 일부 열에는 중복 정보가 포함되고 일부 열에는 예측 정보가 없습니다. 이러한 열은 고급 데이터 옵션을 사용하여 무시하세요.
고급 데이터 옵션을 선택합니다.
고급 데이터 옵션 대화 상자에서 열 설정 탭을 선택합니다.
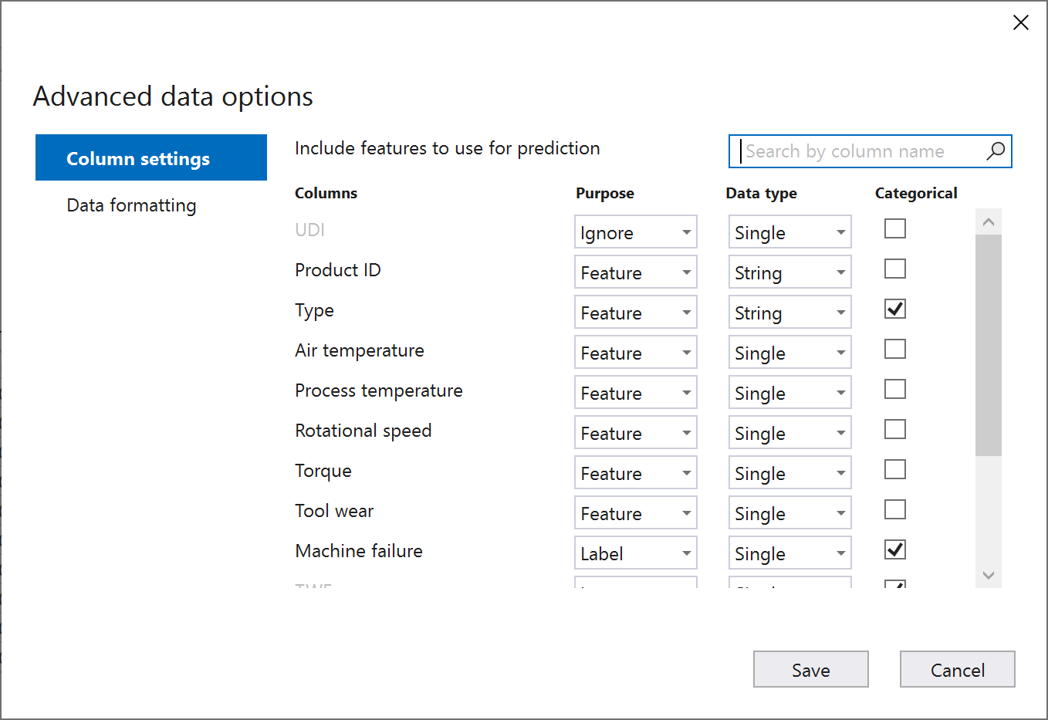
다음과 같이 열 설정을 구성합니다.
열 목적 데이터 형식 범주 UDI 무시 Single Product ID 기능 String Type 기능 String X 대기 온도 기능 Single 프로세스 온도 기능 Single 회전 속도 기능 Single 토크 기능 Single 도구 마모 기능 Single 머신 오류 레이블 Single X TWF 무시 Single X HDF 무시 Single X PWF 무시 Single X OSF 무시 Single X RNF 무시 Single X 저장을 선택합니다.
Model Builder 화면의 데이터 단계에서 다음 단계를 선택합니다.

모델 학습
Model Builder 및 AutoML을 사용하여 모델을 학습합니다.
학습 시간 설정
Model Builder는 파일의 크기에 따라 학습해야 하는 시간을 자동으로 설정합니다. 이 경우 Model Builder가 더 많은 모델을 탐색할 수 있도록 하려면 학습 시간을 늘립니다.
- Model Builder 화면의 학습 단계에서 학습 시간(초)를 30으로 설정합니다.
- 학습을 선택합니다.
학습 프로세스 추적

학습 프로세스가 시작되면 Model Builder가 다양한 모델을 탐색합니다. 학습 프로세스는 학습 결과 및 Visual Studio 출력 창에서 추적됩니다. 학습 결과는 학습 프로세스 전체에서 발견된 최선의 모델에 대한 정보를 제공합니다. 출력 창에는 사용된 알고리즘의 이름, 학습에 걸린 시간 및 해당 모델의 성능 메트릭과 같은 자세한 정보가 제공됩니다.
동일한 알고리즘 이름이 여러 번 표시될 수 있습니다. 이는 Model Builder가 다양한 알고리즘을 시도할 뿐 아니라 이러한 알고리즘에 다양한 하이퍼 매개 변수 구성을 시도하기 때문에 발생합니다.
모델 평가
평가 메트릭 및 데이터를 사용하여 모델의 성능을 테스트합니다.
모델 검사
Model Builder 화면의 평가 단계를 사용하면 최선의 모델을 위해 선택된 평가 메트릭 및 알고리즘을 검사할 수 있습니다. 선택한 알고리즘 및 하이퍼 매개 변수가 다를 수 있으므로 이 모듈에 언급된 것과 결과가 달라도 괜찮습니다.
모델 테스트
평가 단계의 모델 시험 섹션에서 새 데이터를 제공하고 예측 결과를 평가할 수 있습니다.

샘플 데이터 섹션에서는 모델이 예측을 수행할 수 있도록 입력 데이터를 제공합니다. 각 필드는 모델을 학습시키는 데 사용되는 열에 해당합니다. 이 방법은 모델이 예상대로 동작하는지 확인하는 편리한 방법입니다. 기본적으로 Model Builder는 데이터 세트의 첫 번째 행으로 샘플 데이터를 미리 채웁니다.
모델을 테스트하여 예상 결과를 생성하는지 확인해 보겠습니다.
샘플 데이터 섹션에서 다음 데이터를 입력합니다. 이 데이터는 UID 161이 있는 데이터 세트의 행에서 가져온 것입니다.
열 값 Product ID L47340 Type L 대기 온도 298.4 프로세스 온도 308.2 회전 속도 1282 토크 60.7 도구 마모 216 예측을 선택합니다.
예측 결과 평가
결과 섹션에는 모델이 수행한 예측과 이 예측의 신뢰도가 표시됩니다.
데이터 세트에서 UID 161의 머신 오류 열을 보면 값이 1임을 알 수 있습니다. 이는 결과 섹션에서 신뢰도가 가장 높은 예측 값과 동일합니다.
원하는 경우 다른 입력 값을 사용하여 모델을 계속 시험하고 예측을 평가할 수 있습니다.
축하합니다! 머신 오류를 예측하는 모델을 학습했습니다. 다음 단원에서는 모델 사용에 대해 알아봅니다.