Apache HBase 설명
Apache HBase는 Apache Hadoop을 기반으로 빌드된 오픈 소스 NoSQL 데이터베이스입니다. HBase는 열 패밀리로 구성된 스키마 없는 데이터베이스에서 대량의 비정형 데이터 및 반정형 데이터에 임의 액세스 및 뛰어난 일관성을 제공합니다. HDInsight 4.0 HBase 클러스터는 Apache HBase 2.1.6 및 Apache Phoenix 5와 함께 제공됩니다.
사용자 관점에서 볼 때 HBase는 데이터베이스와 유사합니다. 데이터는 테이블의 행과 열에 저장되고 행 내의 데이터는 열 제품군으로 그룹화됩니다. HBase는 사용 전에 열과 열에 저장되는 데이터 형식을 정의할 필요가 없다는 점에서 스키마 없는 데이터베이스입니다. 오픈 소스 코드는 수천 대의 노드에 있는 페타바이트 크기의 데이터를 처리할 수 있을 정도로 선형으로 확장됩니다.
HBase의 고유한 기능은 다음과 같습니다.
일관된 읽기 및 쓰기
대기 시간이 짧은 작업
자동 분할
자동 지역 서버 장애 조치(failover)
Hadoop/HDFS/MapReduce 통합
Java 클라이언트 API
Java가 아닌 프런트 엔드에 Thrift 및 REST 지원
블록 캐시 및 블룸 필터
Apache Phoenix를 사용하는 Azure HDInsight HBase는 다음과 같은 추가 이점을 제공합니다.
SQL 및 비 SQL 인터페이스
유연한 용량 계획
Azure 네트워킹을 통한 전역 배포 및 복제
컴퓨팅과 스토리지의 분리
HDInsight Enterprise 보안 기능과 긴밀하게 통합
대기 시간이 매우 짧은 읽기 및 쓰기를 위한 HDInsight HBase의 가속화된 쓰기
쿼리와 같은 실시간 SQL을 위한 Apache Phoenix
Azure HDInsight를 HBase와 함께 사용하면 대규모로 NoSQL 데이터베이스를 실행할 수 있습니다. Contoso 데이터 엔지니어로서, 중요 업무용 프로덕션 시나리오에 이 플랫폼을 사용하기 전에 HDInsight HBase의 성능 및 규모를 이해하기 위한 벤치마크 테스트를 실행할 수 있어야 합니다.
HDInsight 기반 HBase는 컴퓨팅 및 스토리지를 분리하여 실행합니다. HDInsight HBase 클러스터는 Azure Storage에 직접 데이터를 저장하도록 구성되며, 그러면 대기 시간이 짧고 성능 및 비용 선택 시 탄력성이 높습니다. 이 속성을 통해 고객은 대규모 데이터 세트로 작동하는 대화형 웹 사이트를 빌드할 수 있습니다. 수백만 개의 엔드포인트에서 발생하는 센서 및 원격 분석 데이터를 저장하는 서비스를 빌드하고 Hadoop 작업을 사용해 이 데이터를 분석할 수 있습니다. HBase와 Hadoop은 Azure의 빅 데이터 프로젝트를 위한 좋은 시작점입니다. 이 서비스를 통해 실시간 애플리케이션에서 대규모 데이터 세트를 사용할 수 있습니다. HDInsight HBase 구현에서는 HBase의 스케일 아웃 아키텍처를 사용하여 테이블 자동 분할을 제공합니다. 읽기 및 쓰기와 자동 장애 조치(failover)에 대해서도 뛰어난 일관성을 제공합니다. 읽기를 위한 메모리 내 캐싱과 쓰기를 위한 높은 처리량 스트리밍을 통해 성능이 향상됩니다. HBase 클러스터는 가상 네트워크 내에 만들 수 있습니다. 자세한 내용은 Create HDInsight clusters on Azure Virtual Network(Azure Virtual Network에 HDInsight 클러스터 생성)를 참조하세요.
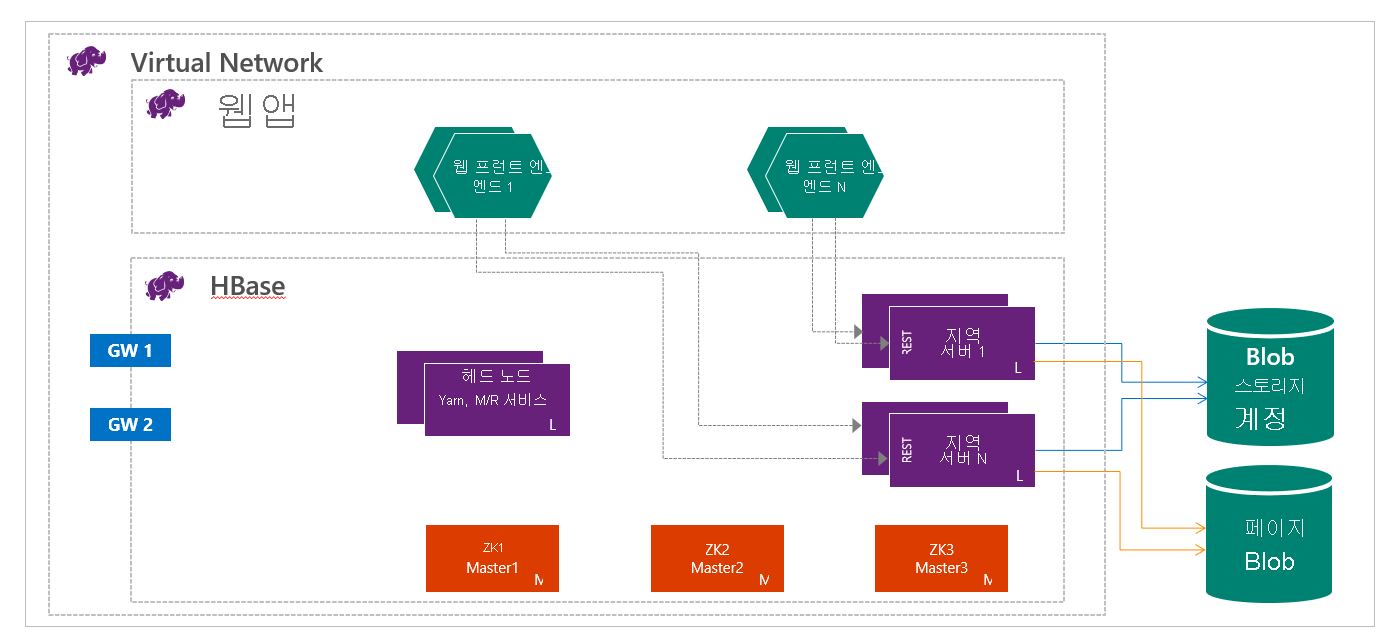
데이터 엔지니어는 솔루션을 빌드하기 위해 만들 가장 적절한 유형의 HDInsight 클러스터를 결정해야 합니다. 선형적으로 크기를 조정하는 NoSQL 데이터베이스를 위해 HDInsight에서 HBase 클러스터를 사용하여 엄청난 양의 처리량을 갖추고 저렴한 비용에 대기 시간이 짧은 읽기 및 무제한 스토리지를 제공합니다.
다음은 HDInsight에서 HBase를 사용하는 주요 시나리오입니다.
키-값 저장소
HBase는 일반적으로 키-값 저장소로 사용되며 메시지 시스템 관리에 적합합니다.
센서 데이터
HBase는 소셜 분석, 시계열, 추세 및 카운터를 통한 대화형 대시보드 최신 상태 유지, 감사 로그 시스템 관리를 비롯하여 다양한 원본에서 증분 수집된 데이터를 캡처하는 데 유용합니다.
실시간 쿼리
Apache Phoenix는 Apache HBase용 SQL 쿼리 엔진입니다. JDBC 드라이버로 액세스되며 SQL을 사용하여 HBase 테이블을 쿼리하고 관리할 수 있도록 합니다.
HBase를 플랫폼으로 사용
HBase를 데이터 저장소로 사용하여 HBase 위에서 애플리케이션을 실행할 수 있습니다. 예를 들어 Phoenix, OpenTSDB, Kiji, Titan 등이 있습니다. 애플리케이션이 HBase와 통합될 수도 있습니다. Apache Hive, Apache Pig, Solr, Apache Flume, Apache Impala, Apache Spark, Ganglia, Apache Drill 등을 예로 들 수 있습니다.
HDInsight에서는 HBase를 독립 실행형 애플리케이션으로 사용할 수도 있고 Spark, Hadoop, Hive, Kafka 같은 다른 빅 데이터 분석 애플리케이션과 함께 배포할 수도 있습니다.
HBase 데이터 모델은 데이터 형식이 다르고 열 크기 및 필드 크기가 다양한 반정형 데이터를 저장합니다. HBase 데이터 모델 레이아웃은 클러스터에서 데이터 분할 및 배포를 용이하게 합니다. HBase 데이터 모델은 행 키, 열 패밀리, 테이블 이름, 타임스탬프 등 여러 논리적 구성 요소로 이루어집니다.
행 키는 HBase 테이블에서 행을 고유하게 식별하는 데 사용됩니다. HDInsight에서는 HBase REST, HBase RPC, Phoenix Query Server, HBase 대량 로드 같은 여러 사용 가능한 API를 사용하여 HBase에 직접 데이터를 기록하거나 Apache Spark, Hive 같은 여러 빅 데이터 프레임워크와의 통합을 사용할 수 있습니다.
HBase의 가속화된 쓰기 기능을 활용하여 높은 쓰기 처리량을 지원할 수 있습니다. HBase 아키텍처 및 모범 사례에 관해 자세히 알아보려면 HBase Book(HBase 설명서)을 참조하세요.