HBase에서 벤치마킹 수행
YCSB(Yahoo! Cloud Serving Benchmark)는 NoSQL 데이터베이스 관리 시스템의 상대적 성능을 평가하는 데 사용되는 오픈 소스 사양 및 프로그램 모음입니다. 이 연습에서는 두 HBase 클러스터의 성능에 대한 벤치마크를 실행합니다. 두 클러스터 중 하나에서는 가속화된 쓰기 기능을 사용하고 있습니다. 두 옵션 간 성능 차이를 이해하기 위한 작업입니다. 연습 필수 구성 요소
이 연습의 단계를 수행하려면 아래 요소가 있어야 합니다.
- HDInsight HBase 클러스터를 만들 수 있는 권한이 부여된 Azure 구독.
- Putty(Windows)/Terminal(Mac 서적) 같은 SSH 클라이언트에 대한 액세스 권한
Azure 관리 포털을 사용하여 HDInsight HBase 클러스터 프로비저닝
Azure 관리 포털의 새로운 환경으로 HDInsight HBase를 프로비저닝하려면 다음 단계를 수행합니다.
Azure 포털로 이동합니다. Azure 계정 자격 증명을 사용하여 로그인합니다.
프리미엄 블록 Blob Storage 계정 생성로 시작합니다. 새로 생성 페이지에서 스토리지 계정을 클릭합니다.
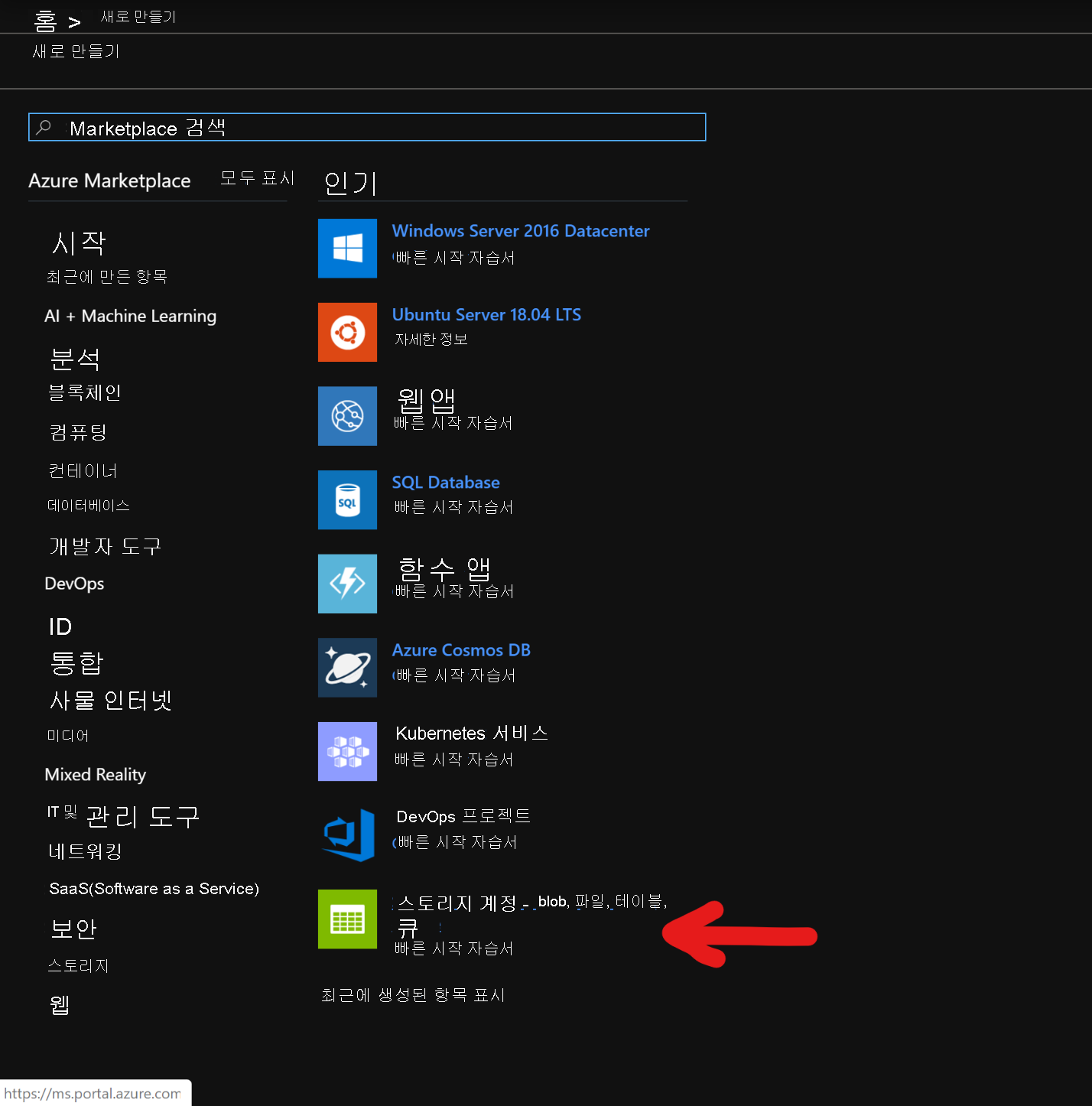
스토리지 계정 생성 페이지에서 아래 필드를 채웁니다.
구독: 구독 세부 정보가 자동으로 채워져야 함
리소스 그룹: HDInsight HBase 배포를 포함하는 리소스 그룹 입력
스토리지 계정 이름: 프리미엄 클러스터에서 사용할 스토리지 계정의 이름 입력
지역: 배포 지역의 이름 입력(클러스터 및 스토리지 계정이 동일한 지역에 있는지 확인)
성능: 프리미엄
계정 종류: BlockBlobStorage
복제: LRS(로컬 중복 스토리지)
클러스터 로그인 사용자 이름: 클러스터 관리자의 사용자 이름 입력(기본값: admin)
다른 모든 탭은 기본값으로 그대로 두고 검토 + 생성를 클릭하여 스토리지 계정을 생성합니다.
스토리지 계정을 생성된 후 왼쪽에 있는 액세스 키를 클릭하고 key1을 복사합니다. 이 값은 나중에 클러스터 생성 프로세스에서 사용합니다.
이제 가속화된 쓰기를 사용하는 HDInsight HBase 클러스터 배포를 시작하겠습니다. 리소스 만들기 -> 분석 -> HDInsight를 선택합니다.
기본 탭에서 HBase 클러스터 생성를 위해 아래 필드를 채웁니다.
구독: 구독 세부 정보가 자동으로 채워져야 함
리소스 그룹: HDInsight HBase 배포를 포함하는 리소스 그룹 입력
클러스터 이름: 클러스터 이름 입력. 클러스터 이름을 사용할 수 있는 경우 녹색 확인 표시가 나타납니다.
지역: 배포 지역 이름 입력
클러스터 유형: 클러스터 유형 - HBase, 버전 - HBase 2.0.0(HDI 4.0)
클러스터 로그인 사용자 이름: 클러스터 관리자의 사용자 이름 입력(기본값: admin)
클러스터 로그인 암호: 클러스터 로그인 암호 입력(기본값: sshuser)
클러스터 로그인 암호 확인: 마지막 단계에서 입력한 암호 확인
SSH(Secure Shell) 사용자 이름: SSH 로그인 사용자 입력(기본값: sshuser)
SSH에 클러스터 로그인 암호 사용: SSH 로그인 및 Ambari 로그인 둘 다에 동일한 암호를 사용하려면 이 상자 선택

다음: 스토리지를 클릭하여 스토리지 탭을 시작하고 아래 필드를 채웁니다.
기본 스토리지 유형: Azure Storage
선택 방법: 액세스 키 사용 라디오 단추 선택
스토리지 계정 이름: 이전에 생성된 프리미엄 블록 Blob 스토리지 계정의 이름 입력
액세스 키: 앞에서 복사한 key1 액세스 키 입력
컨테이너: HDInsight에서 기본 컨테이너 이름을 제안해야 합니다. 해당 이름을 선택하거나 고유한 이름을 만들 수 있습니다.
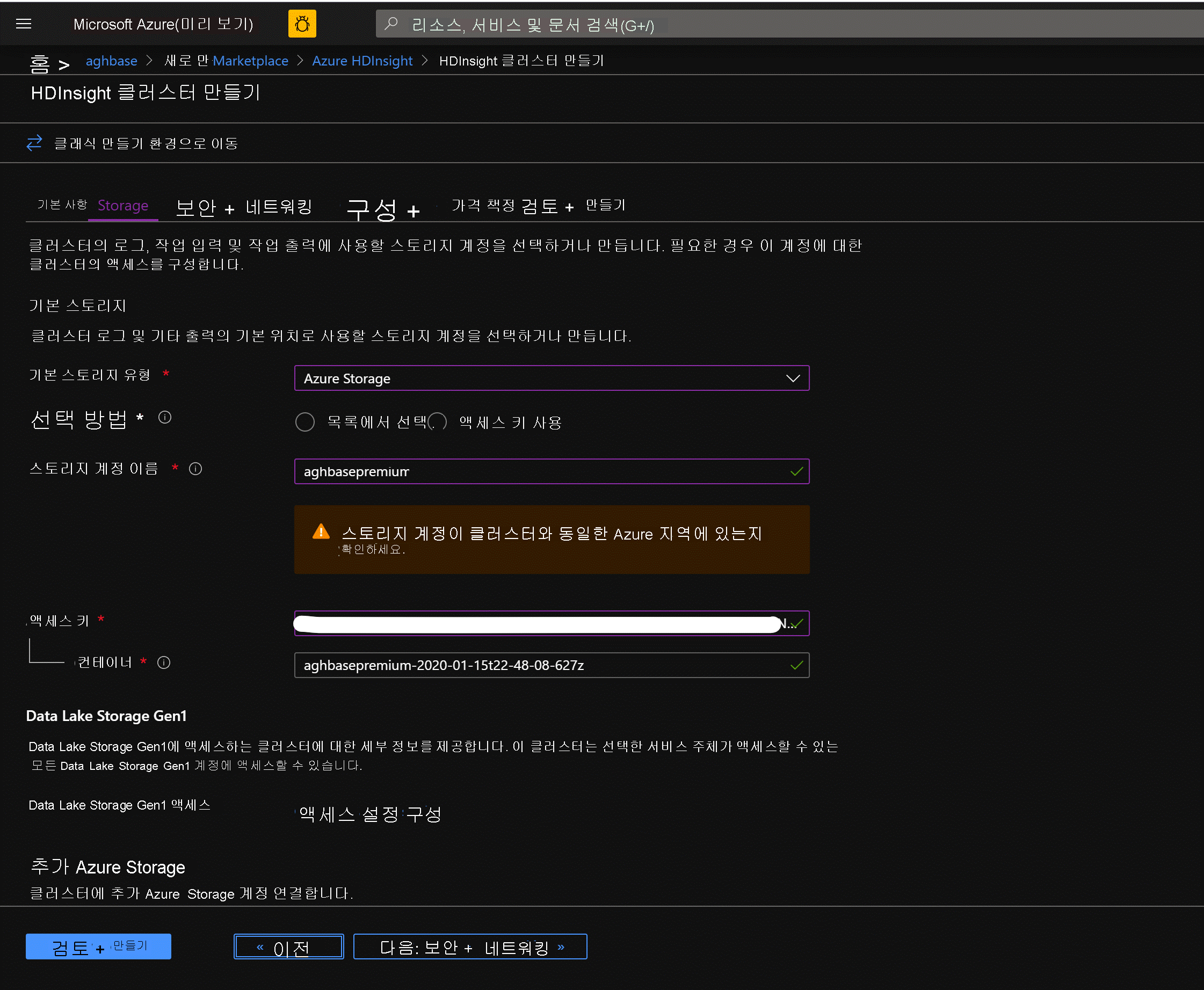
나머지 옵션은 그대로 유지하고 아래로 스크롤하여 HBase 가속화된 쓰기 사용 확인란을 선택합니다. 나중에 동일한 단계를 사용하되 이 확인란은 선택하지 않은 상태로 하여 가속화된 쓰기를 사용하지 않는 두 번째 클러스터를 만들 수 있습니다.
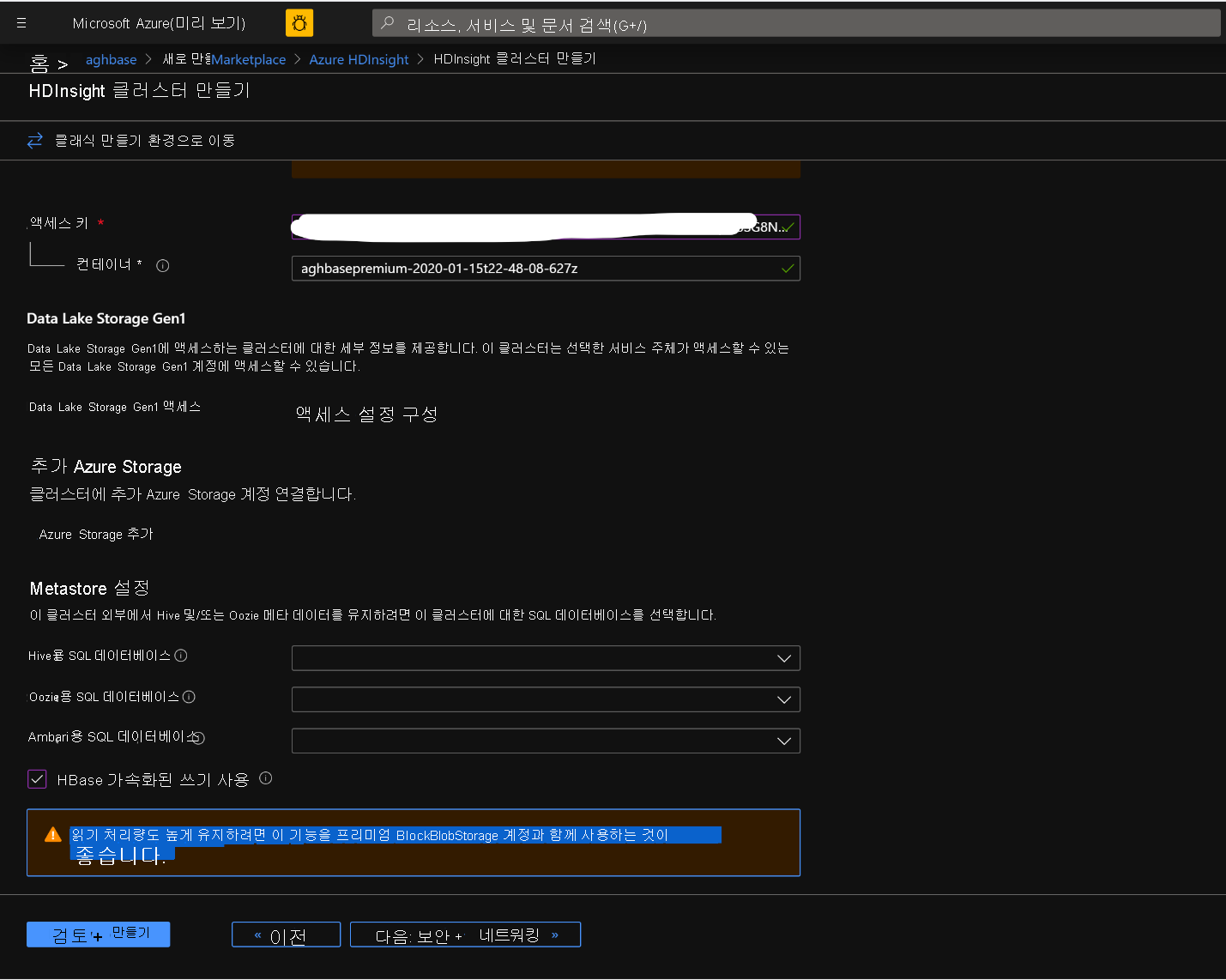
보안 + 네트워킹 블레이드를 변경하지 않고 기본 설정으로 그대로 두고 구성 + 가격 책정 탭으로 이동합니다.
구성 + 가격 책정 탭에서 노드 구성 섹션에 작업자 노드당 프리미엄 디스크라는 품목이 있는지 확인합니다.
지역 노드를 10으로 선택하고 노드 크기를 DS14v2로 선택합니다(더 작은 수의 VM 및 더 작은 크기의 VM SKU를 선택할 수 있지만 두 클러스터의 노드 수 및 VM SKU 크기를 같게 하여 비교 시 패리티를 유지해야 함).
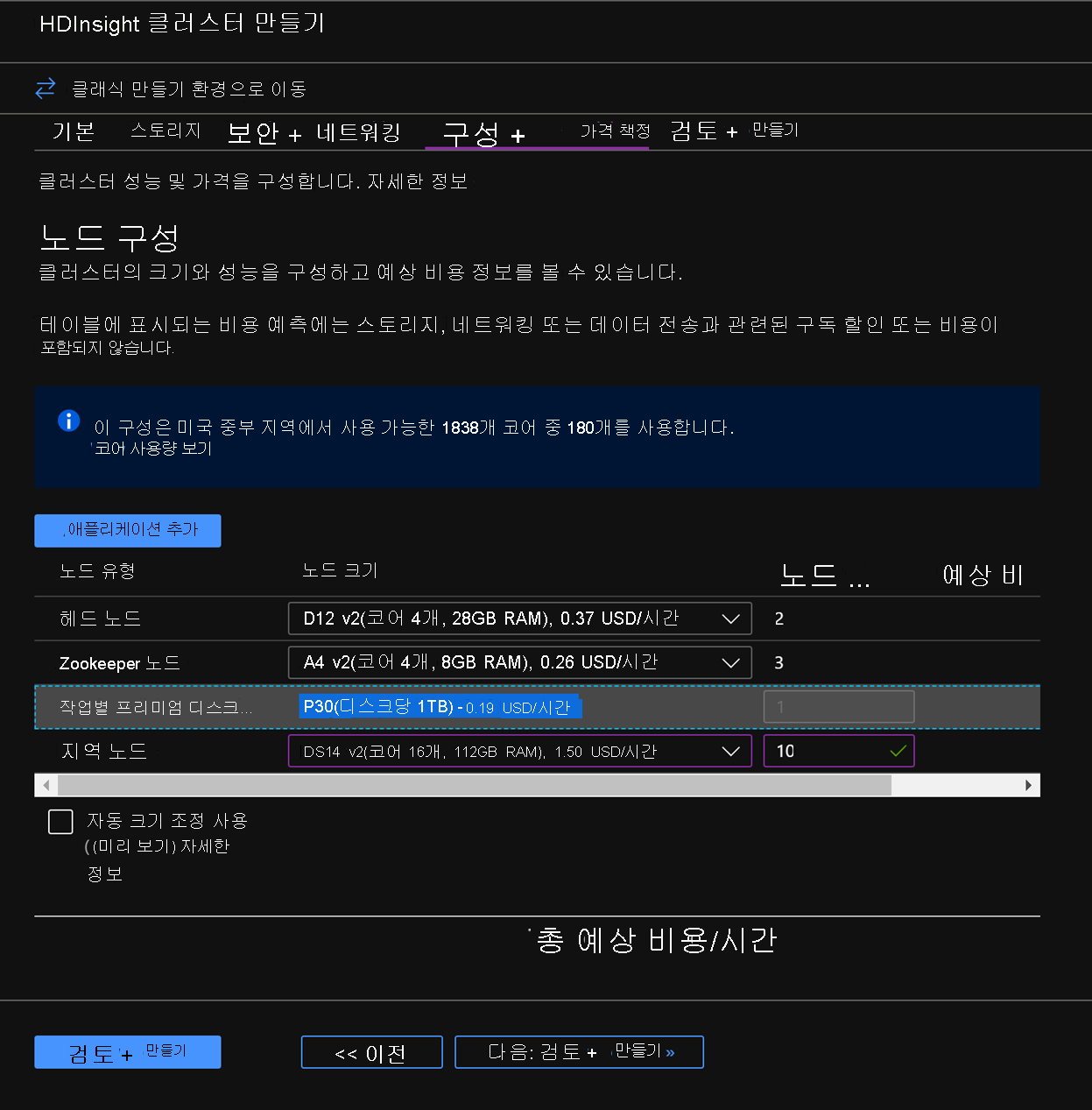
다음: 검토 + 생성를 클릭합니다.
검토 및 생성 탭의 스토리지 섹션에서 HBase 가속화된 쓰기가 사용하도록 설정되어 있는지 확인합니다.
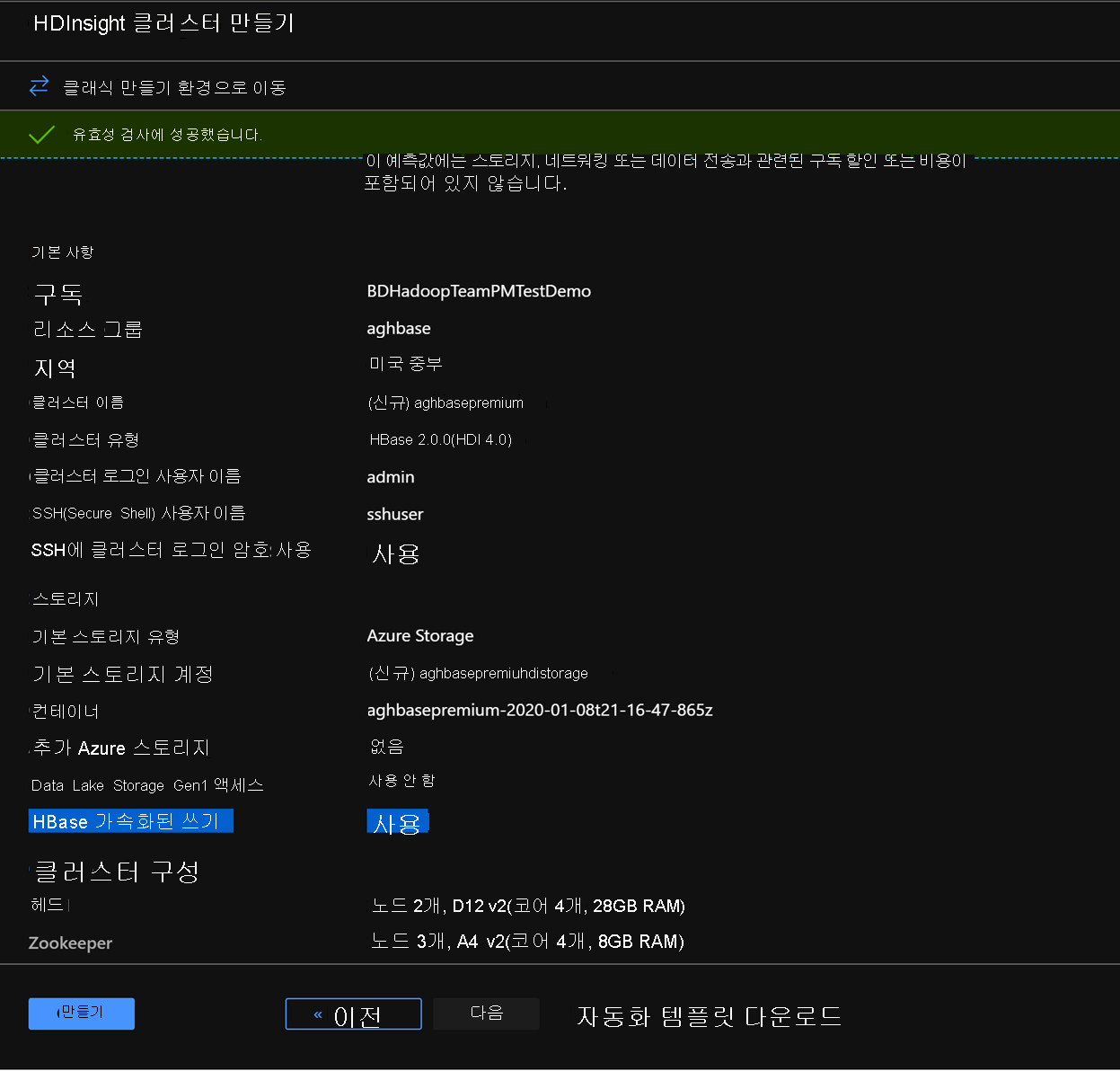
가속화된 쓰기를 사용하는 첫 번째 클러스터 배포를 시작하려면 생성를 클릭합니다.
동일한 단계를 다시 반복하여 두 번째 HDInsight HBase 클러스터를 생성합니다. 이번에는 가속화된 쓰기를 사용하지 않습니다. 아래 변경 내용에 유의하세요.
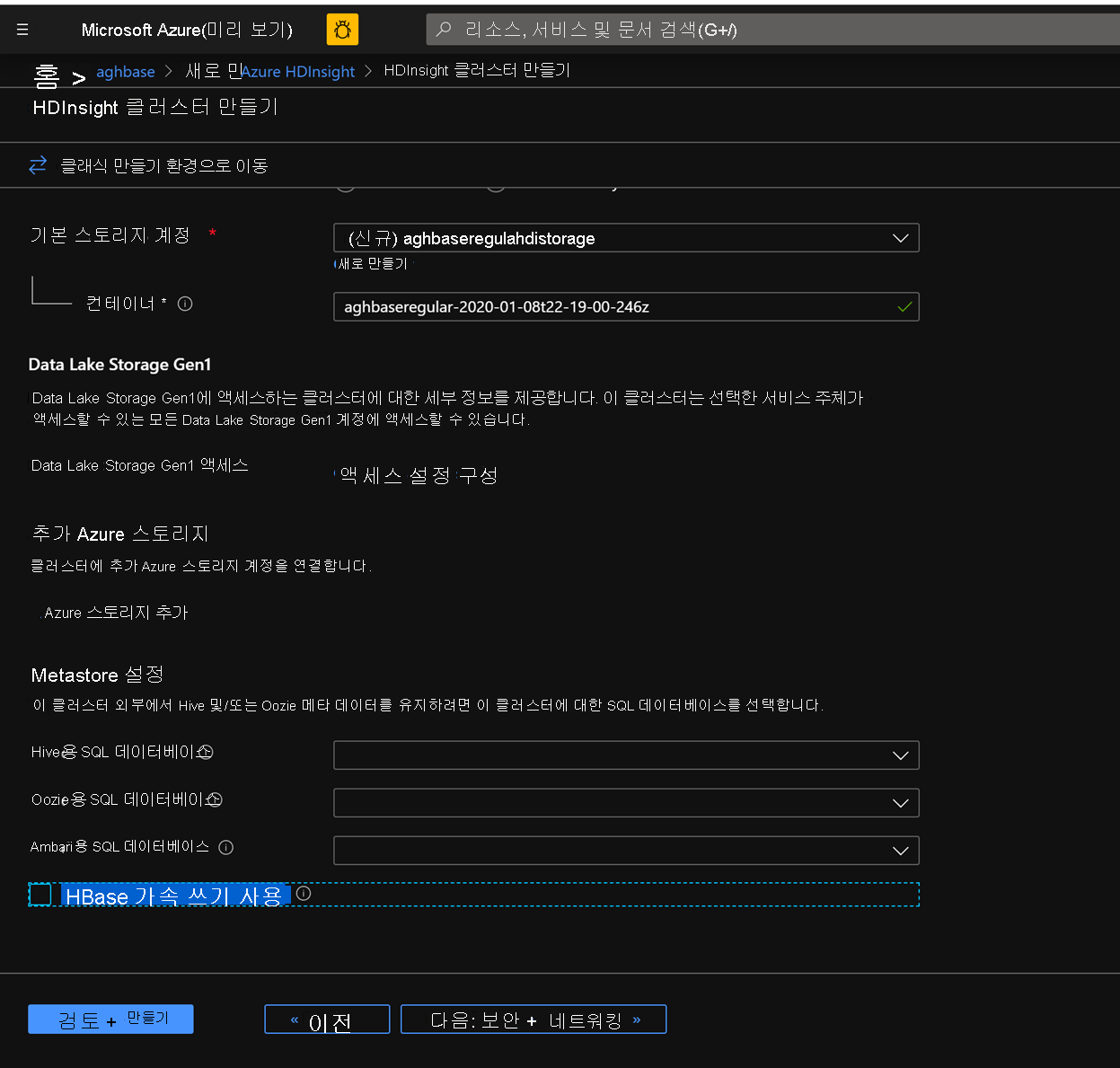
기본적으로 권장되는 일반 blob 스토리지 계정을 사용합니다.
스토리지 탭에서 가속화된 쓰기 사용 확인란을 선택하지 않은 상태로 유지합니다.
이 클러스터의 구성 + 가격 책정 탭에서는 노드 구성 섹션에 작업자 노드당 프리미엄 디스크 품목이 없습니다.
지역 노드를 10으로 선택하고 노드 크기를 D14v2로 선택합니다. 이전처럼 DS 시리즈 VM 유형도 없다는 점에 유의하세요. 더 작은 수의 VM 및 더 작은 크기의 VM SKU를 선택할 수 있지만 두 클러스터의 노드 수 및 VM SKU 크기를 같게 하여 비교 시 패리티를 유지해야 합니다.
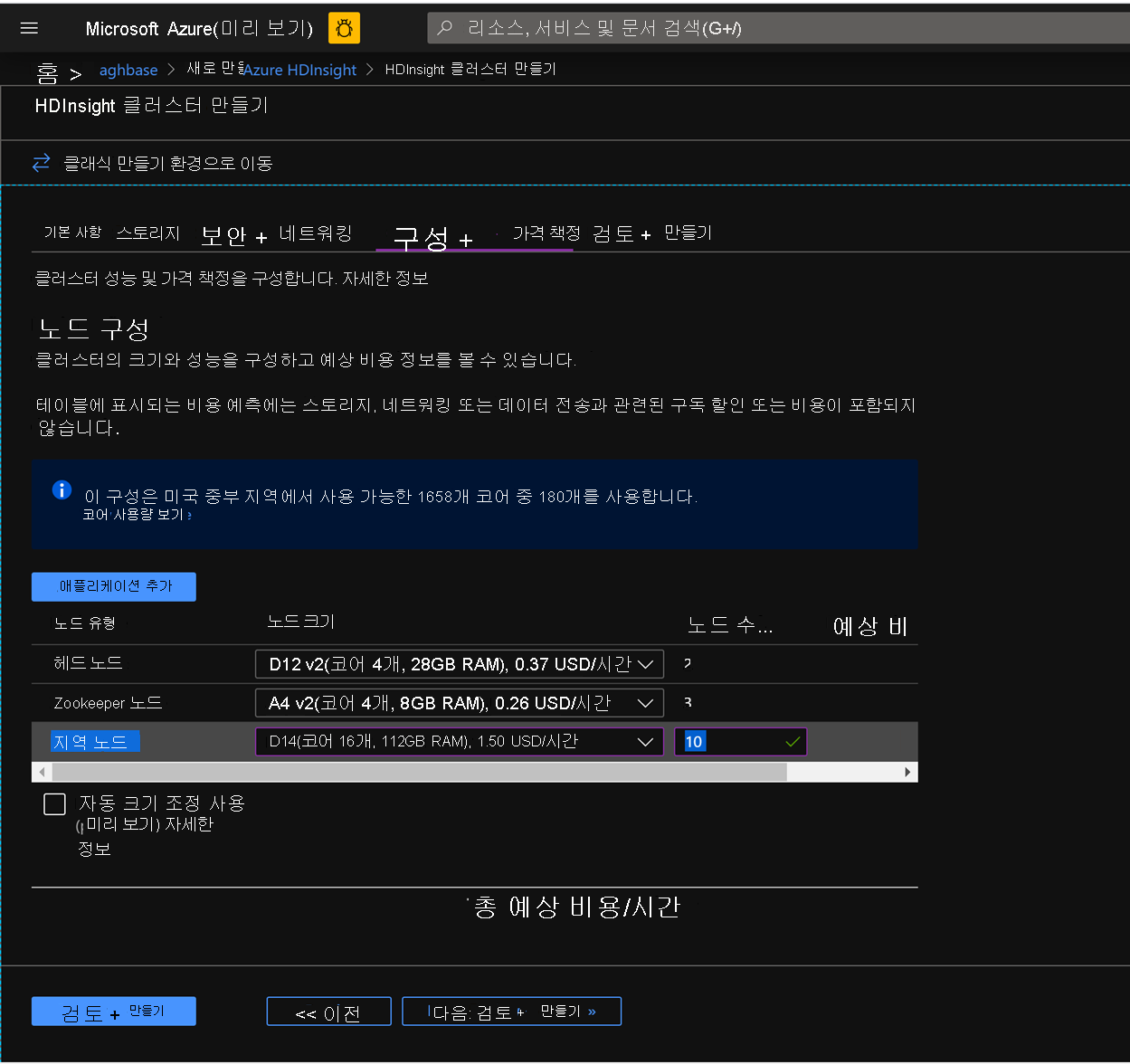
생성를 클릭하여 가속화된 쓰기를 사용하지 않는 두 번째 클러스터 배포를 시작합니다.
이제 클러스터 배포를 완료했으므로 다음 섹션에서는 이러한 두 클러스터에 대해 YCSB 테스트를 설정하고 실행하겠습니다.

YCSB 테스트 실행
HDInsight 셸에 로그인합니다.
두 클러스터에서 YCSB 테스트를 설정하고 실행하는 단계는 동일합니다.
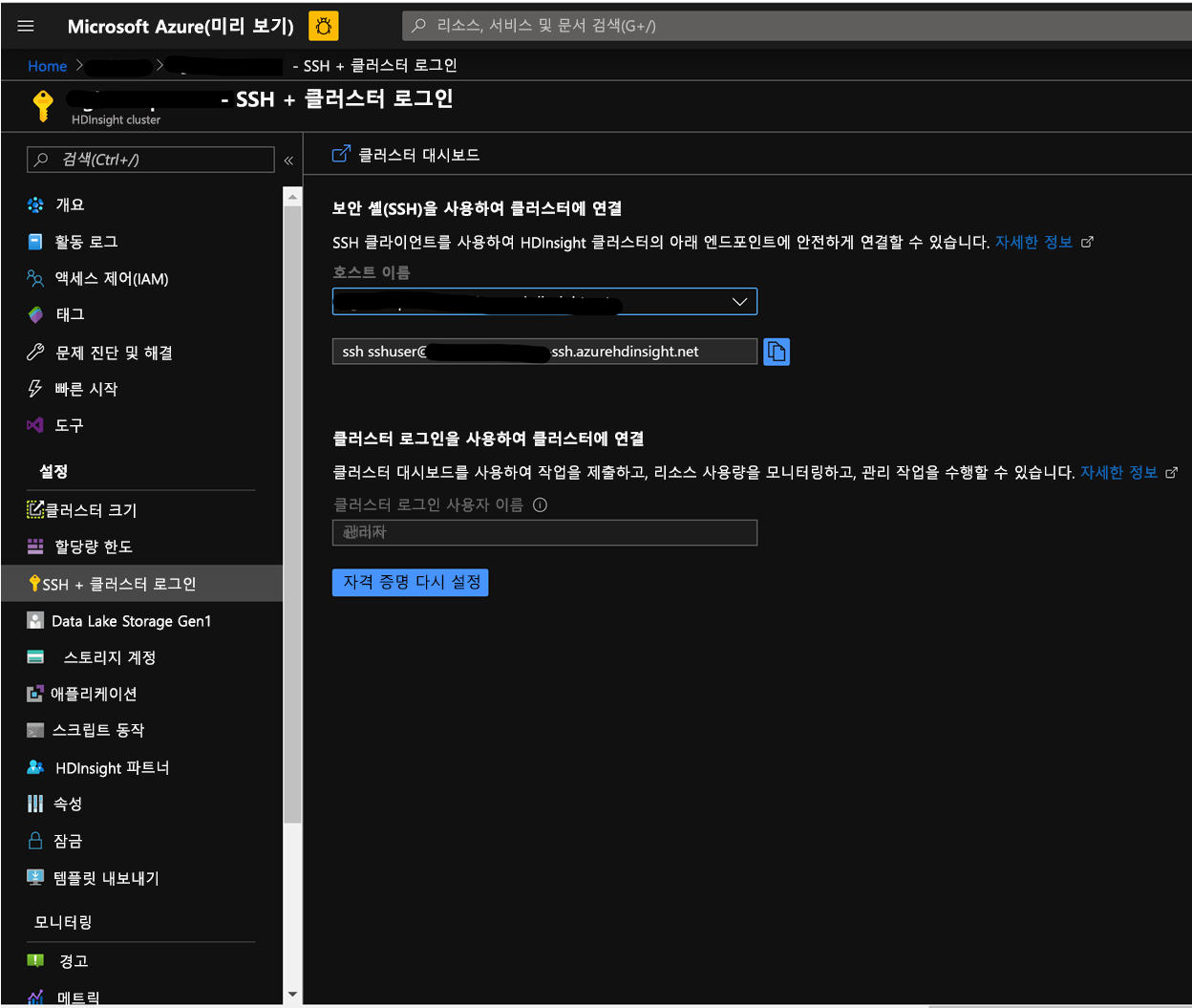
Azure Portal의 클러스터 페이지에서 SSH + 클러스터 로그인으로 이동한 후 호스트 이름 및 클러스터에 대한 ssh의 SSH 경로를 사용합니다. 경로의 형식은 다음과 같아야 합니다.
ssh <sshuser>@<clustername>.azurehdinsight.net
테이블을 생성합니다.
다음 단계를 실행하여 데이터 세트를 로드하는 데 사용되는 HBase 테이블을 생성합니다.
HBase 셸을 시작하고 테이블 분할 수에 대한 매개 변수를 설정합니다. 테이블 분할을 설정합니다(10 * 지역 서버 수).
테스트를 실행하는 데 사용되는 HBase 테이블을 생성합니다.
HBase 셸을 끝냅니다.
hbase(main):018:0> n_splits = 100 hbase(main):019:0> create 'usertable', 'cf', {SPLITS => (1..n_splits).map {|i| "user#{1000+i*(9999-1000)/n_splits}"}} hbase(main):020:0> exit
YSCB 리포지토리를 다운로드합니다.
아래 대상에서 YCSB 리포지토리를 다운로드합니다.
$ curl -O --location https://github.com/brianfrankcooper/YCSB/releases/download/0.17.0/ycsb-0.17.0.tar.gz폴더의 압축을 풀어 콘텐츠에 액세스합니다.
$ tar xfvz ycsb-0.17.0.tar.gz그러면 ycsb-0.17.0 폴더가 만들어집니다. 이 폴더로 이동합니다.
두 클러스터에서 쓰기가 많은 워크로드를 실행합니다.
아래 명령에서 아래 매개 변수를 사용하여 쓰기가 많은 워크로드를 시작합니다.
workloads/workloada: append workload/workloada가 실행되어야 함을 나타냅니다.
table: 이전에 생성된 HBase 테이블의 이름을 채웁니다.
columnfamily: 생성된 테이블에서 HBase columfamily 이름 값을 채웁니다.
recordcount: 삽입될 레코드 수입니다(여기서는 100만을 사용).
threadcount: 스레드 수입니다(수가 달라질 수 있지만, 실험 간에 일정하게 유지되어야 함).
-cp /etc/hbase/conf: HBase 구성 설정에 대한 포인터입니다.
-s | tee -a: 출력을 쓸 파일 이름을 제공합니다.
bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.dat
쓰기가 많은 워크로드를 실행하여 이전에 생성된 HBase 테이블로 100만 개 행을 로드합니다.
참고
명령을 제출한 후 표시될 수 있는 경고를 무시합니다.
가속화된 쓰기를 사용하는 HDInsight HBase 결과 예
다음 명령 실행:
```CMD $ bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.dat ```결과를 읽습니다.
```CMD 2020-01-10 16:21:40:213 10 sec: 15451 operations; 1545.1 current ops/sec; est completion in 10 minutes [INSERT: Count=15452, Max=120319, Min=1249, Avg=2312.21, 90=2625, 99=7915, 99.9=19551, 99.99=113855] 2020-01-10 16:21:50:213 20 sec: 34012 operations; 1856.1 current ops/sec; est completion in 9 minutes [INSERT: Count=18560, Max=305663, Min=1230, Avg=2146.57, 90=2341, 99=5975, 99.9=11151, 99.99=296703] .... 2020-01-10 16:30:10:213 520 sec: 972048 operations; 1866.7 current ops/sec; est completion in 15 seconds [INSERT: Count=18667, Max=91199, Min=1209, Avg=2140.52, 90=2469, 99=7091, 99.9=22591, 99.99=66239] 2020-01-10 16:30:20:214 530 sec: 988005 operations; 1595.7 current ops/sec; est completion in 7 second [INSERT: Count=15957, Max=38847, Min=1257, Avg=2502.91, 90=3707, 99=8303, 99.9=21711, 99.99=38015] ... ... 2020-01-11 00:22:06:192 564 sec: 1000000 operations; 1792.97 current ops/sec; [CLEANUP: Count=8, Max=80447, Min=5, Avg=10105.12, 90=268, 99=80447, 99.9=80447, 99.99=80447] [INSERT: Count=8512, Max=16639, Min=1200, Avg=2042.62, 90=2323, 99=6743, 99.9=11487, 99.99=16495] [OVERALL], RunTime(ms), 564748 [OVERALL], Throughput(ops/sec), 1770.7012685303887 [TOTAL_GCS_PS_Scavenge], Count, 871 [TOTAL_GC_TIME_PS_Scavenge], Time(ms), 3116 [TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.5517505152740692 [TOTAL_GCS_PS_MarkSweep], Count, 0 [TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0 [TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0 [TOTAL_GCs], Count, 871 [TOTAL_GC_TIME], Time(ms), 3116 [TOTAL_GC_TIME_%], Time(%), 0.5517505152740692 [CLEANUP], Operations, 8 [CLEANUP], AverageLatency(us), 10105.125 [CLEANUP], MinLatency(us), 5 [CLEANUP], MaxLatency(us), 80447 [CLEANUP], 95thPercentileLatency(us), 80447 [CLEANUP], 99thPercentileLatency(us), 80447 [INSERT], Operations, 1000000 [INSERT], AverageLatency(us), 2248.752362 [INSERT], MinLatency(us), 1120 [INSERT], MaxLatency(us), 498687 [INSERT], 95thPercentileLatency(us), 3623 [INSERT], 99thPercentileLatency(us), 7375 [INSERT], Return=OK, 1000000 ```테스트 결과를 살펴봅니다. 위 결과에서 볼 수 있는 몇 가지 관찰 예는 다음과 같습니다.
- 테스트를 실행하는 데 538663밀리초(8.97분)가 걸렸습니다.
- Return=OK, 1000000은 100만 개 입력이 모두 성공적으로 기록되었음을 나타냅니다. **
- 쓰기 처리량은 초당 1,856개 작업입니다.
- insert의 95%에서 대기 시간은 3389밀리초입니다.
- 소수의 insert에서는 더 많은 시간이 걸렸습니다. 많은 워크로드로 인해 지역 서버에서 차단했기 때문일 수 있습니다.
가속화된 쓰기를 사용하지 않는 HDInsight HBase의 결과 예
다음 명령 실행:
$ bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.dat결과를 읽습니다.
2020-01-10 23:58:20:475 2574 sec: 1000000 operations; 333.72 current ops/sec; [CLEANUP: Count=8, Max=79679, Min=4, Avg=9996.38, 90=239, 99=79679, 99.9 =79679, 99.99=79679] [INSERT: Count=1426, Max=39839, Min=6136, Avg=9289.47, 90=13071, 99=27535, 99.9=38655, 99.99=39839] [OVERALL], RunTime(ms), 2574273 [OVERALL], Throughput(ops/sec), 388.45918828344935 [TOTAL_GCS_PS_Scavenge], Count, 908 [TOTAL_GC_TIME_PS_Scavenge], Time(ms), 3208 [TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.12461770760133055 [TOTAL_GCS_PS_MarkSweep], Count, 0 [TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0 [TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0 [TOTAL_GCs], Count, 908 [TOTAL_GC_TIME], Time(ms), 3208 [TOTAL_GC_TIME_%], Time(%), 0.12461770760133055 [CLEANUP], Operations, 8 [CLEANUP], AverageLatency(us), 9996.375 [CLEANUP], MinLatency(us), 4 [CLEANUP], MaxLatency(us), 79679 [CLEANUP], 95thPercentileLatency(us), 79679 [CLEANUP], 99thPercentileLatency(us), 79679 [INSERT], Operations, 1000000 [INSERT], AverageLatency(us), 10285.497832 [INSERT], MinLatency(us), 5568 [INSERT], MaxLatency(us), 1307647 [INSERT], 95thPercentileLatency(us), 18751 [INSERT], 99thPercentileLatency(us), 33759 [INSERT], Return=OK, 1000000결과를 비교합니다.
매개 변수 단위 가속화된 쓰기 사용 가속화된 쓰기 사용 안 함 [OVERALL], RunTime(ms) 밀리초 567478 2574273 [OVERALL], Throughput(ops/sec) 연산/초 1770 388 [INSERT], Operations 작업 수 1000000 1000000 [INSERT], 95thPercentileLatency(us) 마이크로초 3623 18751 [INSERT], 99thPercentileLatency(us) 마이크로초 7375 33759 [INSERT], Return=OK 레코드 수 1000000 1000000 비교를 수행할 수 있는 몇 가지 관찰 예는 다음과 같습니다.
- [OVERALL], RunTime(ms): 총 실행 시간(밀리초)
- [OVERALL], Throughput(ops/sec): 모든 스레드의 작업 수/초
- [INSERT], Operations: 관련 평균, 최소, 최대, 값 미만인 95번째 및 99번째 백분위 수 대기 시간이 있는 총 insert 작업 수
- [INSERT], 95thPercentileLatency(us): INSERT 작업의 95%에 이 값 미만의 데이터 포인트가 있습니다.
- [INSERT], 99thPercentileLatency(us): INSERT 작업의 99%에 이 값 미만의 데이터 포인트가 있습니다.
- [INSERT], Return = OK: Record OK는 모든 INSERT 작업이 포함된 개수와 함께 성공적임을 나타냅니다.
다른 워크로드 범위에서 비교하는 것을 고려해 보세요. 예를 들면 다음과 같습니다.
대부분 읽기(95% 읽기 및 5% 쓰기): workloadb
bin/ycsb run hbase12 -P workloads/workloadb -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p operationcount=100000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloadb.dat읽기 전용(100% 읽기 및 0% 쓰기): workloadc
bin/ycsb run hbase12 -P workloads/workloadc -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p operationcount=100000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloadc.dat