분류란 무엇일까요?
이진 분류는 두 가지 범주로 분류됩니다. 예를 들어 환자에게 당뇨병 아님 레이블 또는 당뇨병 레이블을 지정할 수 있습니다.
클래스 예측은 가능한 각 클래스의 확률을 0(불가능)과 1(확실) 사이의 값으로 결정하여 수행합니다. 모든 클래스의 확률 합계는 항상 1입니다. 환자가 당뇨병이거나 아니거나 둘 중 하나이기 때문입니다. 따라서 환자가 당뇨병일 예측 확률이 0.3이면 당뇨병이 아닐 확률은 0.7입니다.
임계값(주로 0.5)은 예측 클래스를 결정하는 데 사용됩니다. 양성 클래스(이 경우 당뇨 있음)의 예측 확률이 임계값보다 큰 경우 당뇨병이 있다는 분류가 예측됩니다.
분류 모델 학습 및 평가
분류는 지도 기계 학습 기술의 한 예입니다. 즉, 알려진 기능 값과 알려진 레이블 값을 포함하는 데이터를 사용합니다. 이 예제에서 기능 값은 환자의 진단 측정값이며 레이블 값은 당뇨병 아님 또는 당뇨병임이라는 분류입니다. 분류 알고리즘은 기능 값에서 각 클래스 레이블의 확률을 계산할 수 있는 함수에 데이터의 하위 집합을 맞추는 데 사용됩니다. 나머지 데이터는 기능에서 생성하는 예측을 알려진 클래스 레이블로 비교하여 모델을 평가하는 데 사용됩니다.
간단한 예
주요 원칙을 설명하는 데 도움이 되는 예를 살펴보겠습니다. 단일 기능(혈당 수준)과 클래스 레이블(당뇨병 아님 0, 당뇨병임 1)로 구성된 다음과 같은 환자 데이터가 있다고 가정하겠습니다.
| Blood-Glucose | 당뇨병 환자 |
|---|---|
| 82 | 0 |
| 92 | 0 |
| 112 | 1 |
| 102 | 0 |
| 115 | 1 |
| 107 | 1 |
| 87 | 0 |
| 120 | 1 |
| 83 | 0 |
| 119 | 1 |
| 104 | 1 |
| 105 | 0 |
| 86 | 0 |
| 109 | 1 |
처음 8개의 관측값을 사용하여 분류 모델을 학습시키고 먼저 혈당 특성(x)과 예측 당뇨병 레이블(y)을 그래프로 나타냅니다.
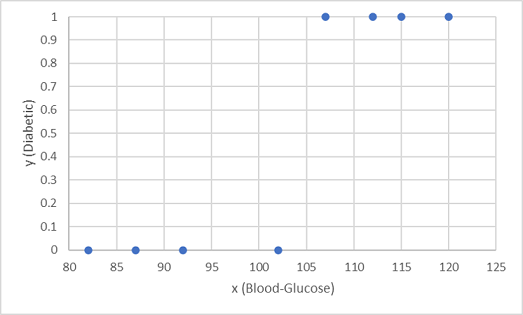
x에 따라 y의 확률을 계산하는 함수가 필요합니다(즉, f(x) = y 함수가 필요). 차트에서 혈당 수치가 낮은 환자는 모두 당뇨병이 없는 반면, 혈당 수치가 높은 환자는 당뇨병 환자임을 알 수 있습니다. 혈당 수치가 높을수록 환자가 당뇨병 환자일 가능성이 높으며 굴곡점은 100에서 110 사이입니다. y에 대해 0과 1 사이의 값을 계산하는 함수를 이 값에 맞춰야 합니다.
해당 함수 중 하나는 logistic 함수로, S자 형태의 곡선을 형성합니다.
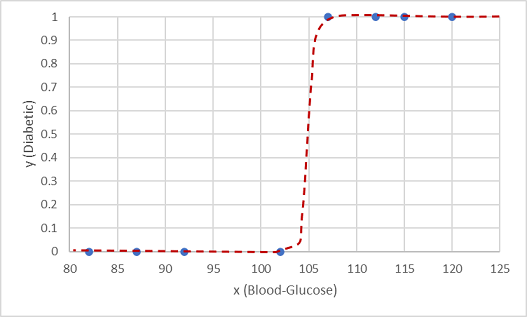
이제 함수를 사용하여 x에 대한 함수 선에서 점을 찾아 x의 값에서 y가 양수(즉, 환자가 당뇨병 환자임)일 확률 값을 계산할 수 있습니다. 임계값 0.5를 클래스 레이블 예측의 컷오프 점으로 설정할 수 있습니다.
이전에 저장한 두 개의 데이터 값으로 테스트해 보겠습니다.
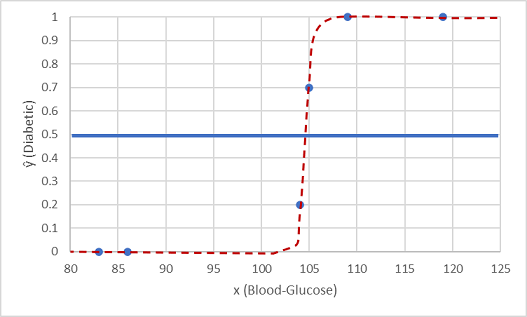
임계값 선 아래에 표시된 점은 예측 클래스 0(당뇨병 아님)을 산출하고 선 위의 점은 1(당뇨병)로 예측됩니다.
이제 모델에 캡슐화된 로지스틱 함수를 기반으로 레이블 예측(ŷ 또는 "y-hat"이라고 함)을 실제 클래스 레이블(y)과 비교할 수 있습니다.
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |