회귀란 무엇일까요?
회귀는 관찰되는 항목의 특징을 나타내는 데이터의 변수(‘기능’이라고 함)와 예측하려는 변수(‘레이블’이라고 함) 사이의 관계를 설정하여 작동합니다.
회사는 자전거를 대여하고 주어진 날짜에 예상되는 대여 횟수를 예측하려고 합니다. 이 경우 특징에는 요일, 월 등의 항목이 포함되며 레이블은 자전거 대여 횟수입니다.
모델을 교육하기 위해 레이블에 대해 알려진 값뿐만 아니라 기능이 포함된 데이터 샘플로 시작합니다. 따라서 이 경우 날짜, 기상 조건 및 자전거 대여 횟수를 포함하는 과거 데이터가 필요합니다.
그런 다음 이 데이터 샘플을 다음과 같은 두 개의 하위 세트로 분할합니다.
- 기능 값과 알려진 레이블 값 사이의 관계를 캡슐화하는 함수를 결정하는 알고리즘을 적용할 학습 데이터 세트.
- 레이블의 예측을 생성하는 데 사용하고 실제 알려진 레이블 값과 비교하여 모델을 평가하는 데 사용할 수 있는 유효성 검사 또는 test 데이터 세트.
회귀는 기록 데이터와 알려진 레이블 값을 사용하여 모델을 학습시키므로 감독되는 기계 학습의 예가 됩니다.
간단한 예제
교육 및 평가 프로세스가 원칙적으로 어떻게 작동하는지 간단한 예를 들어 보겠습니다. 단일 기능인 평균 일일 기온을 사용하여 자전거 대여 레이블을 예측하도록 시나리오를 단순화한다고 가정합니다.
평균 일일 온도 기능 및 자전거 대여 레이블에 대한 알려진 값을 포함하는 데이터를 시작합니다.
| 온도 | 대여 |
|---|---|
| 56 | 115 |
| 61 | 126 |
| 67 | 137 |
| 72 | 140 |
| 76 | 152 |
| 82 | 156 |
| 54 | 114 |
| 62 | 129 |
이제 이러한 관찰 중 5개를 ‘임의로’ 선택하고 이를 사용하여 회귀 모델을 학습시킵니다. ‘모델 학습’에 대해 말할 때 의미하는 것은 온도 기능(x라고 함)을 사용하여 대여 수(y라고 함)를 계산할 수 있는 함수(수학 방정식, f라고 함)를 찾는 것입니다. 즉, f(x) = y 함수를 정의해야 합니다.
학습 데이터 세트는 다음과 같습니다.
| x | y |
|---|---|
| 56 | 115 |
| 61 | 126 |
| 67 | 137 |
| 72 | 140 |
| 76 | 152 |
먼저 차트에서 x 및 y의 학습 값을 살펴보겠습니다.
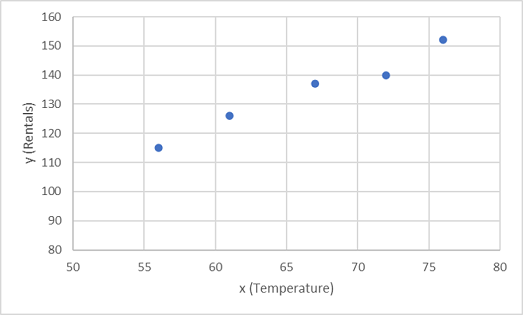
이제 임의 변형이 가능하도록 이 값을 함수에 맞게 조정해야 합니다. 표시된 점이 거의 직선인 대각선을 형성하는 것을 볼 수 있습니다. 즉, x와 y 사이에 명백한 선형 관계가 있으므로 다음을 찾아야 합니다. 데이터 샘플에 가장 적합한 선형 함수입니다. 이 함수를 결정하는 데 사용할 수 있는 알고리즘은 다양하며, 해당 알고리즘은 궁극적으로 다음과 같이 도표에 표시된 포인트에서 전체 분산이 최소인 직선을 찾습니다.
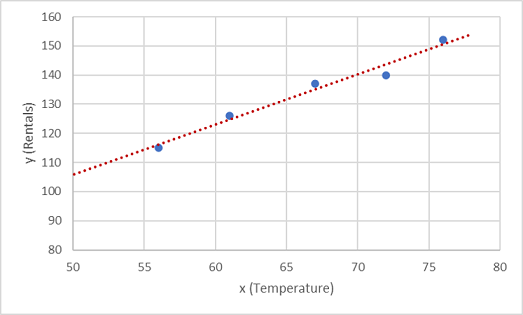
선은 x의 값과 함께 사용하여 선의 기울기와 절편(여기서 선은 x가 0일 때 y축을 교차함)을 적용하여 y를 계산하는 선형 함수를 나타냅니다. 이 경우 선을 왼쪽으로 확장하면 x가 0일 때 y가 약이라는 것을 알 수 있습니다. 20이고 선의 기울기는 x의 각 단위에 대해 오른쪽으로 이동하면 y가 다음과 같이 증가합니다. 약 1.7. 따라서 f 함수를 20 + 1.7x로 계산할 수 있습니다.
이제 예측 함수를 정의했으므로, 잠시 보류한 유효성 검사 데이터의 레이블을 예측하고, 예측 값(일반적으로 ŷ 기호 또는 “y-hat”으로 표시)을 실제 알려진 y 값과 비교하는 데 사용합니다.
| x | y | ŷ |
|---|---|---|
| 82 | 156 | 159.4 |
| 54 | 114 | 111.8 |
| 62 | 129 | 125.4 |
y와 ŷ 값을 도표에서 비교하는 방식을 살펴보겠습니다.
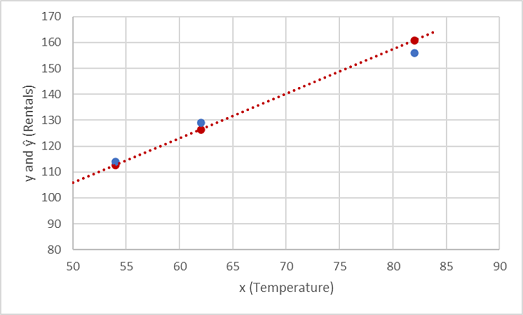
함수 줄에 있는 도표로 작성된 포인트는 함수를 사용하여 계산한 예측된 ŷ 값이고 도표로 작성된 다른 포인트는 실제 y 값입니다.
예측값과 실제값 사이의 차이를 측정할 수 있는 다양한 방법이 있으며, 이 메트릭을 사용하여 모델이 얼마나 잘 예측되는지 평가할 수 있습니다.
참고
기계 학습은 통계 및 수학을 기반으로 하므로 통계학자와 수학자(따라서 데이터 과학자)가 사용하는 특정 용어를 알고 있어야 합니다. 예측된 레이블 값과 실제 레이블 값의 차이를 오차 측정값으로 간주할 수 있습니다. 그러나 실제로 "실제" 값은 샘플 관찰을 기반으로 합니다(그 자체가 일부 임의 변동의 영향을 받을 수 있음). 예측 값(ŷ)과 관측 값(y)을 명확히 비교하기 위해 두 값 사이의 차이를 잔차라고 합니다. 모든 유효성 검사 데이터 예측의 잔차를 요약하여 모델의 전반적인 손실을 예측 성능 측정값으로 계산할 수 있습니다.
손실을 측정하는 가장 일반적인 방법 중 하나는 개별 잔차를 제곱하고 제곱의 합계를 계산한 다음 평균을 계산하는 것입니다. 잔차를 제곱하면 ‘절대값’을 기준으로 계산(차이가 음수인지 아니면 정수인지 무시)하고 더 큰 차이에 더 큰 가중치를 부여하는 효과가 있습니다. 이 메트릭은 평균 제곱 오차라고 합니다.
유효성 검사 데이터의 경우 계산은 다음과 같습니다.
| y | ŷ | y - ŷ | (y - ŷ)2 |
|---|---|---|---|
| 156 | 159.4 | -3.4 | 11.56 |
| 114 | 111.8 | 2.2 | 4.84 |
| 129 | 125.4 | 3.6 | 12.96 |
| 합계 | ∑ | 29.36 | |
| 평균값 | x̄ | 9.79 |
따라서 MSE 메트릭을 기반으로 한 모델의 손실은 9.79입니다.
이것이 도움이 되나요? MSE 값은 의미 있는 측정 단위로 표현되지 않기 때문에 구분하기 어렵습니다. 값이 낮을수록 모델의 손실이 적고 따라서 더 잘 예측한다는 것을 알고 있습니다. 따라서 이 메트릭은 두 모델을 비교하는 데 유용하며 최고로 작동하는 모델을 찾을 수 있습니다.
예측된 레이블 값 자체(이 경우 대여 수)와 동일한 측정 단위로 손실을 표시하는 것이 더 유용한 경우가 있습니다. 이 작업은 MSE의 제곱근을 계산해서도 수행할 수 있습니다. 그러면 RMSE(제곱 평균 오차)라는 메트릭이 생성됩니다.
√9.79 = 3.13
따라서 우리 모델의 RMSE는 손실이 3을 조금 넘는다는 것을 나타냅니다. 이는 평균적으로 약 3개의 임대에서 잘못된 예측이 틀렸다는 의미로 느슨하게 해석할 수 있습니다.
회귀에서 손실을 측정하는 데 사용할 수 있는 기타 메트릭은 여러 가지가 있습니다. 예를 들어 R2(R 제곱)(결정 계수라고도 함)는 x와 y 제곱 간의 상관 관계입니다. 이에 따라 모델에서 설명할 수 있는 분산의 양을 측정하는 0과 1 사이의 값이 생성됩니다. 일반적으로 이 값이 1에 가까울수록 모델의 예측 성능이 향상됩니다.