Spark 클러스터 만들기
Azure Databricks 작업 영역 UI를 사용하여 Azure Databricks 작업 영역에서 하나 이상의 클러스터를 만들 수 있습니다.
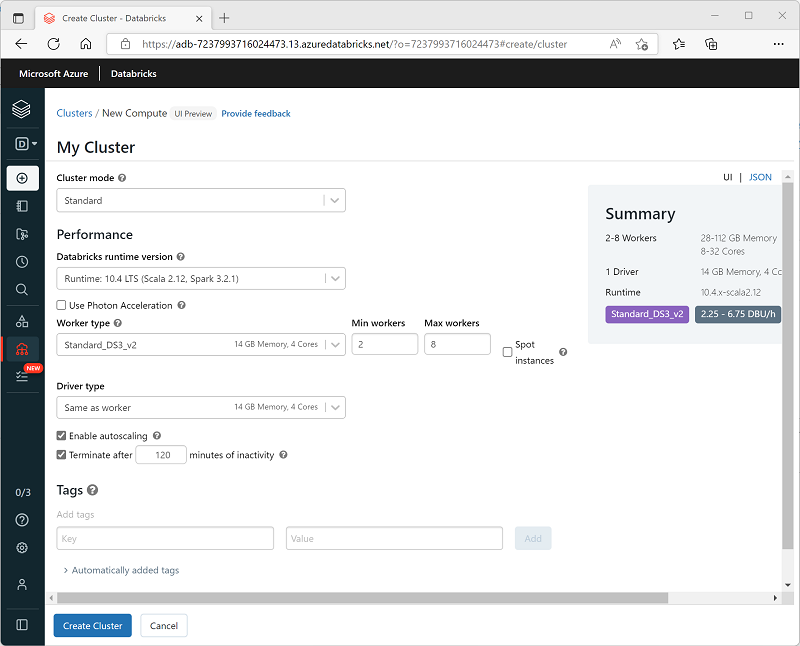
클러스터를 만들 때 다음을 비롯한 구성 설정을 지정할 수 있습니다.
- 클러스터의 이름입니다.
-
다음과 같은 클러스터 모드입니다.
- 표준: 여러 작업자 노드가 필요한 단일 사용자 워크로드에 적합합니다.
- 높은 동시성: 여러 사용자가 클러스터를 동시에 사용하는 워크로드에 적합합니다.
- 단일 노드: 단일 작업자 노드만 필요한 소규모 워크로드 또는 테스트에 적합합니다.
- 클러스터에서 사용할 Databricks 런타임 의 버전입니다. Spark의 버전과 Python, Scala 및 설치되는 다른 구성 요소와 같은 개별 구성 요소를 지정합니다.
- 클러스터의 작업자 노드에 사용되는 VM(가상 머신) 유형입니다.
- 클러스터에 있는 작업자 노드의 최소 및 최대 수입니다.
- 클러스터의 드라이버 노드에 사용되는 VM의 형식입니다.
- 클러스터가 클러스터 크기를 동적으로 조정하도록 자동 크기 조정을 지원하는지 여부입니다.
- 클러스터가 자동으로 종료되기 전에 유휴 상태를 유지할 수 있는 기간입니다.
Azure에서 클러스터 리소스를 관리하는 방법
Azure Databricks 작업 영역을 만들면 Databricks 어플라이언스가 구독에서 Azure 리소스로 배포됩니다. 작업 영역에서 클러스터를 만들 때 드라이버 및 작업자 노드와 다른 구성 옵션 모두에 사용할 VM(가상 머신)의 유형과 크기를 지정하지만 Azure Databricks는 클러스터의 다른 모든 측면을 관리합니다.
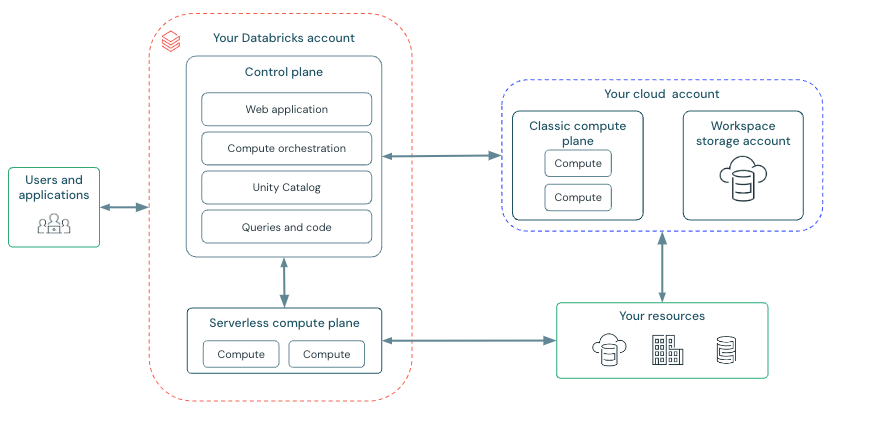
Databricks 어플라이언스는 구독 내에서 관리되는 리소스 그룹으로 Azure에 배포됩니다. 이 리소스 그룹에는 가상 네트워크, 보안 그룹 및 스토리지 계정을 비롯한 다른 필수 리소스와 함께 클러스터에 대한 드라이버 및 작업자 VM이 포함됩니다. 예약된 작업과 같은 클러스터에 대한 모든 메타데이터는 내결함성을 위해 지역에서 복제된 Azure Database에 저장됩니다.
Azure Databricks는 Microsoft에서 관리하는 백 엔드 서비스(예: 웹 UI)로 구성된 컨트롤 플레인과 데이터 워크로드가 실행되는 컴퓨팅 평면의 두 가지 기본 평면으로 분할됩니다. 컴퓨팅에는 고유한 Azure 구독 및 가상 네트워크를 사용하는 클래식 컴퓨팅(구독 내에서 격리 제공)과 Databricks의 관리되는 환경 내에서 실행되지만 여전히 작업 영역과 동일한 Azure 지역에 실행되는 서버리스 컴퓨팅의 두 가지 변형이 있으며, 고객 간에 격리할 네트워크 및 보안 컨트롤이 있습니다. 모든 작업 영역에는 시스템 데이터(Notebook, 로그, 작업 메타데이터), DBFS(분산 파일 시스템) 및 카탈로그 자산(Unity 카탈로그를 사용하도록 설정된 경우)을 보유하는 스토리지 계정이 구독에 있으며, 보안 및 적절한 격리를 보장하기 위해 네트워킹, 방화벽 및 액세스를 위한 추가 컨트롤이 있습니다.
비고
또한 클러스터 시작 시간을 줄이기 위해 유휴 노드의 풀에 클러스터를 연결하는 옵션도 있습니다. 자세한 내용은 Azure Databricks 설명서의 풀 을 참조하세요.