데이터 시각화
데이터 쿼리의 결과를 분석하는 가장 직관적인 방법은 차트로 시각화하는 것입니다. Azure Databricks의 Notebook은 사용자 인터페이스에서 차트 기능을 제공하며, 해당 기능이 필요한 기능을 제공하지 않는 경우 여러 Python 그래픽 라이브러리 중 하나를 사용하여 Notebook에서 데이터 시각화를 만들고 표시할 수 있습니다.
기본 제공 Notebook 차트 사용
Azure Databricks의 Spark Notebook에서 데이터 프레임을 표시하거나 SQL 쿼리를 실행하면 결과가 코드 셀 아래에 표시됩니다. 기본적으로 결과는 테이블로 렌더링되지만, 다음과 같이 결과를 시각화로 보고 차트에서 데이터를 표시하는 방법을 사용자 지정할 수도 있습니다.
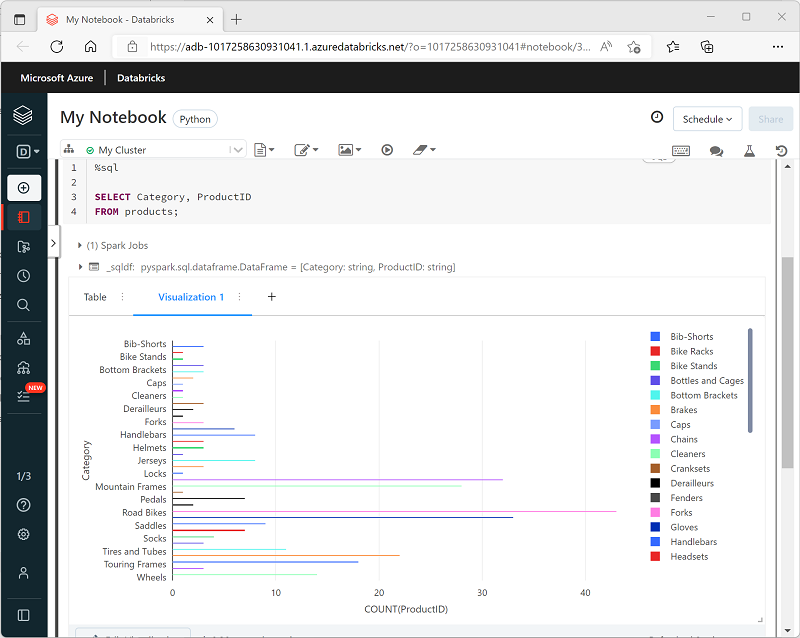
시각화 형식
이러한 시각화는 Databricks에서 만들 수 있는 다양한 종류의 시각화이며, 각 시각화는 특정 종류의 데이터 인사이트에 적합합니다. 주요 정보:
가로 막대형 차트/꺾은선형 차트/영역형 차트: 시간에 따른 추세, 범주 비교 또는 둘 다를 표시합니다. 메트릭이 어떻게 진화하는지 확인하는 데 유용합니다.
원형 차트: 전체의 비례 부분을 표시하는 데 적합합니다(시계열에는 표시되지 않음).
히스토그램: 숫자 데이터의 분포를 확인합니다(값이 분산되고 클러스터되는 방식).
열 지도: 두 범주 축을 시각화하고 숫자 값으로 색을 지정하는 데 유용하므로 그룹 전체에서 패턴을 볼 수 있습니다.
분산형/거품형 차트: 두 개 이상의 숫자 변수 간의 관계를 표시합니다. 거품을 사용하면 크기 또는 색을 세 번째 차원으로 사용할 수 있습니다.
상자 그림: 범주 간 분포(분산, 사분위수, 이상값)를 비교합니다.
콤보 차트: 동일한 차트에 선과 막대가 혼합되어 서로 다른 메트릭을 다른 눈금과 비교하려는 경우에 유용합니다.
피벗 테이블: 탭 간 분석에 유용한 테이블 형식(예: SQL PIVOT/GROUP BY)에서 데이터를 재구성하고 집계할 수 있습니다.
특수 형식: 코호트 분석(시간 경과에 따른 그룹 추적), 카운터 표시(단일 요약 메트릭 강조 표시, 대상 대비), 깔때기형, 맵 시각화(단계구분도, 마커), 단어 구름 등. 이는 보다 전문화되어 있습니다.
Notebook의 기본 제공 시각화 기능은 데이터를 시각적으로 빠르게 요약하려는 경우에 유용합니다. 데이터의 서식을 더 자세히 제어하거나 쿼리에서 이미 집계한 값을 표시하려면 그래픽 패키지를 사용하여 고유한 시각화를 만드는 것이 좋습니다.
코드에서 그래픽 패키지 사용
코드에서 데이터 시각화를 만드는 데 사용할 수 있는 그래픽 패키지가 많이 있습니다. 특히 Python은 다양한 패키지를 지원합니다. 대부분의 기본 Matplotlib 라이브러리를 기반으로 합니다. 그래픽 라이브러리의 출력은 Notebook에서 렌더링할 수 있으므로 코드를 결합하여 인라인 데이터 시각화 및 Markdown 셀을 사용하여 데이터를 수집하고 조작하여 설명을 제공할 수 있습니다.
예를 들어 다음 PySpark 코드를 사용하여 이 모듈에서 이전에 탐색한 가상 제품 데이터의 데이터를 집계하고 Matplotlib를 사용하여 집계된 데이터에서 차트를 만들 수 있습니다.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
Matplotlib 라이브러리를 사용하려면 데이터가 Spark 데이터 프레임이 아닌 Pandas 데이터 프레임에 있어야 하므로 toPandas 메서드를 사용하여 변환합니다. 그런 다음, 코드는 지정된 크기의 그림을 만들고 결과 플롯을 표시하기 전에 일부 사용자 지정 속성 구성이 있는 가로 막대형 차트를 표시합니다.
코드에서 생성된 차트는 다음 이미지와 유사합니다.
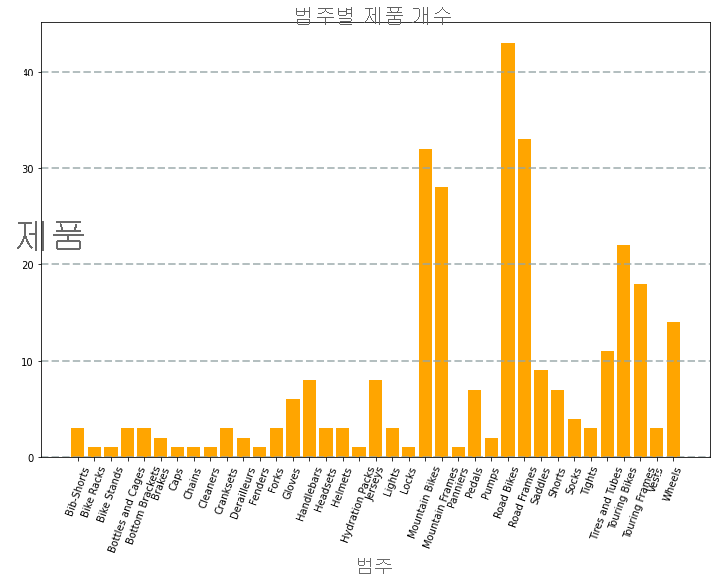
Matplotlib 라이브러리를 사용하여 다양한 종류의 차트를 만들 수 있습니다. 또는 선호하는 경우 Seaborn 과 같은 다른 라이브러리를 사용하여 고도로 사용자 지정된 차트를 만들 수 있습니다.
비고
Matplotlib 및 Seaborn 라이브러리는 클러스터의 Databricks 런타임에 따라 Databricks 클러스터에 이미 설치되어 있을 수 있습니다. 설치되지 않았거나 아직 설치되지 않은 다른 라이브러리를 사용하려는 경우 클러스터에 추가할 수 있습니다. 자세한 내용은 Azure Databricks 설명서의 클러스터 라이브러리 를 참조하세요.