이 문서에서는 Microsoft SQL Server 쿼리가 종료하는 데 과도한 시간(시간 또는 일)이 걸리는 문제에 대한 문제 해결 지침을 제공합니다.
증상
이 문서에서는 끝없이 실행되거나 컴파일되는 것처럼 보이는 쿼리에 중점을 둡니다. 즉, CPU 사용량이 계속 증가하고 있습니다. 이 문서는 해제되지 않은 리소스에서 차단되거나 대기 중인 쿼리에는 적용되지 않습니다. 이러한 경우 CPU 사용량은 일정하게 유지되거나 약간만 변경됩니다.
Important
쿼리가 계속 실행되도록 남아 있으면 결국 완료될 수 있습니다. 이 프로세스는 몇 초 또는 며칠이 걸릴 수 있습니다. 일부 상황에서는 WHILE 루프가 종료되지 않는 경우와 같이 쿼리가 무한할 수 있습니다. 여기서는 "끝 없는" 용어가 완료되지 않는 쿼리의 인식을 설명하는 데 사용됩니다.
원인
장기 실행(종료되지 않는) 쿼리의 일반적인 원인은 다음과 같습니다.
-
NL(중첩 루프)은 매우 큰 테이블에 조인됩니다 . NL 조인의 특성상 행이 많은 테이블을 조인하는 쿼리는 오랫동안 실행될 수 있습니다. 자세한 내용은 조인을 참조하세요.
- NL 조인의 한 가지 예는
TOP,FAST또는EXISTS. 해시 또는 병합 조인이 더 빠를 수 있더라도 최적화 프로그램은 행 목표 때문에 두 연산자 중 하나를 사용할 수 없습니다. - NL 조인의 또 다른 예는 쿼리에서 같지 않음 조인 조건자를 사용하는 것입니다. 예:
SELECT .. FROM tab1 AS a JOIN tab 2 AS b ON a.id > b.id. 최적화 프로그램은 여기에서 병합 또는 해시 조인을 사용할 수 없습니다.
- NL 조인의 한 가지 예는
- 오래된 통계: 오래된 통계를 기반으로 계획을 선택하는 쿼리는 최적이 아닐 수 있으며 실행하는 데 시간이 오래 걸릴 수 있습니다.
- 무한 루프: WHILE 루프를 사용하는 T-SQL 쿼리가 잘못 작성되었을 수 있습니다. 결과 코드는 루프를 벗어나지 않고 끝없이 실행됩니다. 이러한 쿼리는 진정으로 끝이 없습니다. 그들은 수동으로 죽을 때까지 실행됩니다.
- 조인과 큰 테이블이 많은 복잡한 쿼리: 조인된 테이블이 많은 쿼리에는 일반적으로 실행하는 데 시간이 오래 걸릴 수 있는 복잡한 쿼리 계획이 있습니다. 이 시나리오는 행을 필터링하지 않고 많은 테이블을 포함하는 분석 쿼리에서 일반적입니다.
- 누락된 인덱스: 테이블에서 적절한 인덱스를 사용하는 경우 쿼리가 훨씬 더 빠르게 실행됩니다. 인덱스를 사용하면 데이터의 하위 집합을 선택하여 더 빠른 액세스를 제공할 수 있습니다.
해결 방법
1단계: 끝 없는 쿼리 검색
시스템에서 실행되는 끝 없는 쿼리를 찾습니다. 쿼리에 긴 실행 시간, 긴 대기 시간(병목 상태 중단) 또는 긴 컴파일 시간이 있는지 확인해야 합니다.
1.1 진단 실행
끝 없는 쿼리가 활성 상태인 SQL Server 인스턴스에서 다음 진단 쿼리를 실행합니다.
DECLARE @cntr INT = 0
WHILE (@cntr < 3)
BEGIN
SELECT TOP 10 s.session_id,
r.status,
CAST(r.cpu_time / (1000 * 60.0) AS DECIMAL(10,2)) AS cpu_time_minutes,
CAST(r.total_elapsed_time / (1000 * 60.0) AS DECIMAL(10,2)) AS elapsed_minutes,
r.logical_reads,
r.wait_time,
r.wait_type,
r.wait_resource,
r.reads,
r.writes,
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count,
atrn.name as transaction_name,
atrn.transaction_id,
atrn.transaction_state
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id
CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
LEFT JOIN (sys.dm_tran_session_transactions AS stran
JOIN sys.dm_tran_active_transactions AS atrn
ON stran.transaction_id = atrn.transaction_id)
ON stran.session_id =s.session_id
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
SET @cntr = @cntr + 1
WAITFOR DELAY '00:00:05'
END
1.2 출력 검사
긴 실행, 긴 대기 및 긴 컴파일과 같이 쿼리가 오랫동안 실행되도록 할 수 있는 몇 가지 시나리오가 있습니다. 쿼리가 느리게 실행되는 이유에 대한 자세한 내용은 실행 및 대기 중: 쿼리 속도가 느린 이유는 무엇인가요?
긴 실행 시간
이 문서의 문제 해결 단계는 CPU 시간이 상당한 대기 시간 없이 경과된 시간에 비례하여 증가하는 다음과 유사한 출력을 받을 때 적용됩니다.
| session_id | status | cpu_time_minutes | elapsed_time_minutes | logical_reads | wait_time_minutes | wait_type |
|---|---|---|---|---|---|---|
| 56 | 실행 중 | 64.40 | 23.50 | 0 | 0.00 | NULL |
다음이 있는 경우 쿼리가 지속적으로 실행됩니다.
- CPU 시간 증가
- 또는
runningrunnable - 최소 또는 0 대기 시간
- wait_type 없음
이 경우 쿼리는 행 읽기, 조인, 결과 처리, 계산 또는 서식 지정입니다. 이러한 작업은 모두 CPU 바인딩된 작업입니다.
참고 항목
logical_reads 계산 또는 WHILE 루프 수행과 같은 일부 CPU 바인딩 T-SQL 요청이 논리적 읽기를 전혀 수행하지 않을 수 있으므로 이 경우 변경 내용은 관련이 없습니다.
느린 쿼리가 이러한 조건을 충족하는 경우 런타임을 줄이는 데 집중합니다. 일반적으로 런타임을 줄이려면 인덱스를 적용하거나 쿼리를 다시 작성하거나 통계를 업데이트하여 쿼리가 수명 내내 처리해야 하는 행 수를 줄입니다. 자세한 내용은 해결 섹션을 참조 하세요 .
긴 대기 시간
이 문서는 긴 대기 시나리오에는 적용되지 않습니다. 대기 시나리오에서는 세션이 리소스에서 대기 중이므로 CPU 사용량이 약간 변경되지 않거나 변경되지 않는 다음 예제와 유사한 출력을 받을 수 있습니다.
| session_id | status | cpu_time_minutes | elapsed_time_minutes | logical_reads | wait_time_minutes | wait_type |
|---|---|---|---|---|---|---|
| 56 | suspended | 0.03 | 4.20 | 50 | 4.10 | LCK_M_U |
대기 유형은 세션이 리소스에서 대기 중임을 나타냅니다. 경과 시간이 길고 대기 시간이 길면 세션이 이 리소스에 대한 대부분의 수명을 기다리고 있음을 나타냅니다. 짧은 CPU 시간은 쿼리를 실제로 처리하는 데 소요된 시간이 적다는 것을 나타냅니다.
대기로 인해 긴 쿼리 문제를 해결하려면 SQL Server에서 느리게 실행되는 쿼리 문제 해결을 참조하세요.
긴 컴파일 시간
드문 경우지만 시간이 지남에 따라 CPU 사용량이 지속적으로 증가하지만 쿼리 실행에 의해 구동되지 않는 것을 관찰할 수 있습니다. 대신 지나치게 긴 컴파일(쿼리의 구문 분석 및 컴파일)이 원인일 수 있습니다. 이러한 경우 출력 열에 transaction_name 값이 있는지 sqlsource_transform확인합니다. 이 트랜잭션 이름은 컴파일을 나타냅니다.
2단계: 진단 로그를 수동으로 수집
시스템에 끝 없는 쿼리가 있는지 확인한 후에는 쿼리의 계획 데이터를 수집하여 추가 문제를 해결할 수 있습니다. 데이터를 수집하려면 SQL Server 버전에 따라 다음 방법 중 하나를 사용합니다.
- SQL Server 2008 - SQL Server 2014(SP2 이전 버전)
- SQL Server 2014(SP2 이후) 및 SQL Server 2016(SP1 이전 버전)
- SQL Server 2016(SP1 이후) 및 SQL Server 2017
- SQL Server 2019 이상 버전
SSMS(SQL Server Management Studio)를 사용하여 진단 데이터를 수집하려면 다음 단계를 수행합니다.
예상 쿼리 실행 계획 XML을 캡처합니다.
쿼리 계획을 검토하여 데이터가 속도 저하의 원인에 대한 명백한 표시를 보여 주는지 여부를 알아봅니다. 일반적인 표시의 예는 다음과 같습니다.
- 테이블 또는 인덱스 검색(예상 행 보기)
- 거대한 외부 테이블 데이터 집합에 의해 구동되는 중첩된 루프
- 루프의 내부 쪽에 큰 분기가 있는 중첩된 루프
- 테이블 스풀
- 각 행을
SELECT처리하는 데 시간이 오래 걸리는 목록의 함수
쿼리가 언제든지 더 빠르게 실행되는 경우 "빠른" 실행(실제 XML 실행 계획)을 캡처하여 결과를 비교할 수 있습니다.
SQL LogScout을 사용하여 끝 없는 쿼리 캡처
끝 없는 쿼리가 실행되는 동안 SQL LogScout 을 사용하여 로그를 캡처할 수 있습니다. 다음 명령을 사용하여 종료되지 않는 쿼리 시나리오 를 사용합니다.
.\SQL_LogScout.ps1 -Scenario "NeverEndingQuery" -ServerName "SQLInstance"
참고 항목
이 로그 캡처 프로세스에서는 긴 쿼리가 최소 60초의 CPU 시간을 사용해야 합니다.
SQL LogScout은 CPU 사용량이 많은 각 쿼리에 대해 세 개 이상의 쿼리 계획을 캡처합니다. 과 유사한 servername_datetime_NeverEnding_statistics_QueryPlansXml_Startup_sessionId_#.sqlplan파일 이름을 찾을 수 있습니다. 장기 쿼리 실행 이유를 식별하기 위한 계획을 검토할 때 다음 단계에서 이러한 파일을 사용할 수 있습니다.
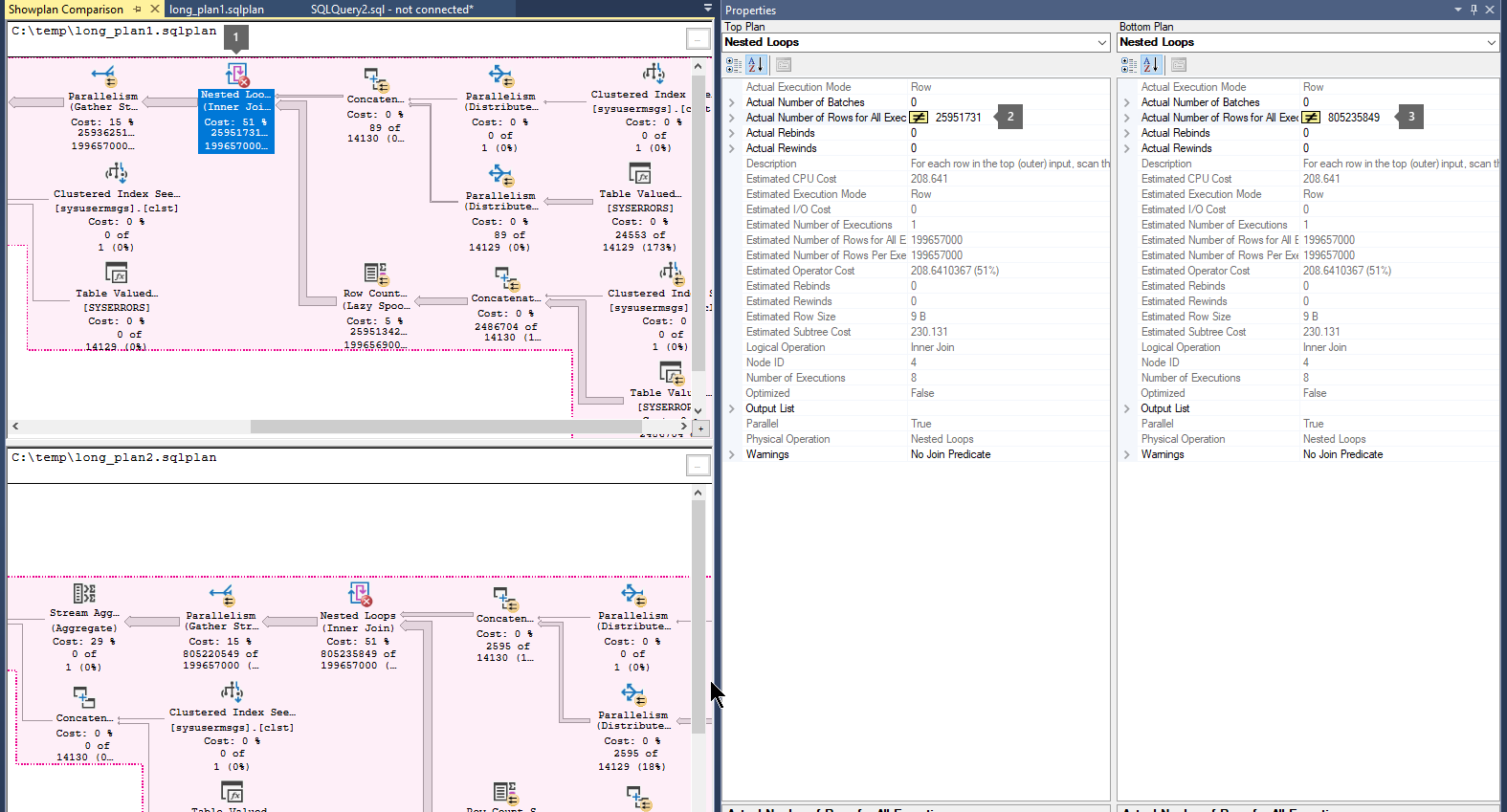
3단계: 수집된 계획 검토
이 섹션에서는 수집된 데이터를 검토하는 방법을 설명합니다. Microsoft SQL Server 2016 SP1 이상 빌드 및 버전에서 수집되는 여러 XML 쿼리 계획(확장 .sqlplan사용)을 사용합니다.
다음 단계에 따라 실행 계획을 비교합니다.
이전에 저장된 쿼리 실행 계획 파일(
.sqlplan)을 엽니다.실행 계획의 빈 영역을 마우스 오른쪽 단추로 클릭하고 실행 계획 비교를 선택합니다.
비교할 두 번째 쿼리 계획 파일을 선택합니다.
연산자 간에 많은 수의 행이 흐르고 있음을 나타내는 두꺼운 화살표를 찾습니다. 그런 다음 화살표 앞이나 뒤에 있는 연산자를 선택하고 두 계획의 실제 행 수를 비교합니다.
두 번째 계획과 세 번째 계획을 비교하여 행의 가장 큰 흐름이 동일한 연산자에서 발생하는지 여부를 알아봅니다.
다음은 그 예입니다.

4단계: 해결 방법
쿼리에 사용되는 테이블에 대한 통계가 업데이트되었는지 확인합니다.
쿼리 계획에서 누락된 인덱스 권장 사항을 찾고 찾은 항목을 적용합니다.
쿼리를 간소화합니다.
- 더 많은 선택적
WHERE조건자를 사용하여 미리 처리되는 데이터를 줄입니다. - 그것을 분해.
- 일부 파트를 임시 테이블로 선택하고 나중에 조인합니다.
-
TOPEXISTSFAST때문에 오랫동안 실행되는 쿼리에서 (T-SQL) 및 (T-SQL)을 제거합니다.- 또는
DISABLE_OPTIMIZER_ROWGOAL를 사용합니다. 자세한 내용은 행 목표 사라 도적을 참조 하세요.
- 또는
- 이러한 경우에는 문을 단일 큰 쿼리로 결합하기 때문에 이러한 경우 CTE(Common Table Expression)를 사용하지 마세요.
- 더 많은 선택적
쿼리 힌트를 사용하여 더 나은 계획을 만들어 보세요.
-
HASH JOIN또는MERGE JOIN힌트 -
FORCE ORDER힌트 -
FORCESEEK힌트 RECOMPILE- USE
PLAN N'<xml_plan>'(강제 적용할 수 있는 빠른 쿼리 계획이 있는 경우)
-
이러한 계획이 있고 SQL Server 버전이 쿼리 저장소 지원하는 경우 QDS(쿼리 저장소)를 사용하여 잘 알려진 계획을 강제로 적용합니다.