이 문서에서는 파일 시스템, 복원력 유형 및 크기 선택을 포함하여 워크로드의 성능 및 용량 요구 사항을 충족하도록 클러스터 볼륨을 계획하는 방법에 대한 지침을 제공합니다.
Note
저장소 공간 다이렉트 일반적으로 사용할 파일 서버를 지원하지 않습니다. 스토리지 공간 다이렉트에서 파일 서버 또는 기타 일반 서비스를 실행해야 하는 경우 가상 머신에서 구성합니다.
검토: 볼륨이란?
볼륨은 워크로드에 필요한 파일(예: Hyper-V 가상 머신용 VHD 또는 VHDX 파일)을 배치하는 위치입니다. 볼륨은 스토리지 풀의 드라이브를 결합하여 Azure 로컬 및 Windows Server 소프트웨어 정의 스토리지 기술인 저장소 공간 다이렉트의 내결함성, 확장성 및 성능 이점을 도입합니다.
Note
"볼륨"이라는 용어를 사용하여 CSV(클러스터 공유 볼륨) 및 ReFS와 같은 다른 기본 제공 Windows 기능에서 제공하는 기능을 포함하여 볼륨과 그 아래의 가상 디스크를 공동으로 참조합니다. 저장소 공간 다이렉트 성공적으로 계획하고 배포하기 위해서는 이러한 구현 수준 구분을 이해할 필요가 없습니다.
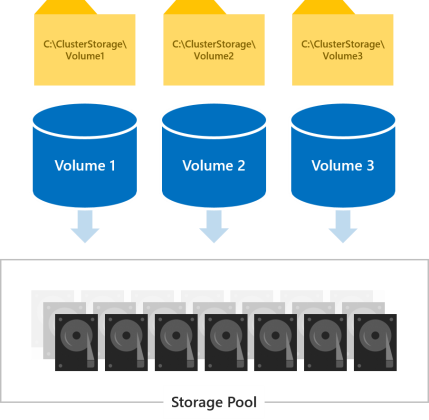
모든 볼륨은 클러스터의 모든 서버에서 동시에 액세스할 수 있습니다. 만든 후에는 모든 서버의 C:\ClusterStorage\ 에 표시됩니다.

만들 볼륨 수 선택
만드는 볼륨 수는 풀의 크기와 지원되는 최대 볼륨 크기에 따라 달라지며 노드당 최소 하나의 볼륨이 있습니다. 이 구성을 사용하면 클러스터가 서버 간에 볼륨 "소유권"(한 서버가 각 볼륨에 대한 메타데이터 오케스트레이션을 처리)을 균등하게 분산할 수 있습니다.
총 볼륨 수를 클러스터당 64개 볼륨으로 제한하는 것이 좋습니다.
파일 시스템 선택
저장소 공간 다이렉트 새 ReFS(Resilient File System) 사용하는 것이 좋습니다. ReFS는 가상화를 위해 특별히 빌드된 최고의 파일 시스템이며, 극적인 성능 가속 및 데이터 손상에 대한 기본 제공 보호를 포함하여 많은 이점을 제공합니다. Windows Server 버전 1709 이상의 데이터 중복 제거를 포함하여 거의 모든 주요 NTFS 기능을 지원합니다. 자세한 내용은 ReFS 기능 비교 테이블을 참조하세요.
워크로드에 ReFS가 아직 지원하지 않는 기능이 필요한 경우 대신 NTFS를 사용할 수 있습니다.
Tip
파일 시스템이 서로 다른 볼륨은 동일한 클러스터에 공존할 수 있습니다.
복원력 유형 선택
저장소 공간 다이렉트의 볼륨은 드라이브나 서버 장애와 같은 하드웨어 문제로부터 시스템을 보호합니다. 또한, 소프트웨어 업데이트와 같은 서버 유지 관리 작업 중에도 지속적인 가용성을 제공하여 서비스를 중단 없이 유지할 수 있도록 합니다.
Note
선택할 수 있는 복원력 유형은 가지고 있는 드라이브 유형과 독립적입니다.
두 개의 서버가 있는 경우
클러스터에 두 개의 서버가 있는 경우 양방향 미러링을 사용하거나 중첩된 복원력을 사용할 수 있습니다.
양방향 미러링에서는 모든 데이터의 복사본 2개( 각 서버의 드라이브에 복사본 1개)를 유지합니다. 스토리지 효율성은 50%입니다. 1TB의 데이터를 쓰려면 스토리지 풀에 2TB 이상의 물리적 스토리지 용량이 필요합니다. 양방향 미러링을 사용하면 한 번에 하나의 하드웨어 오류(서버 또는 드라이브 하나)를 안전하게 허용할 수 있습니다.
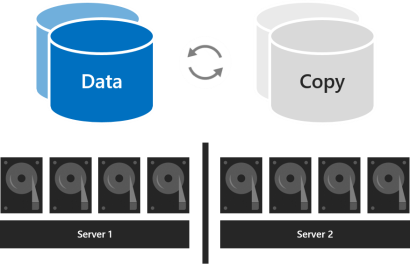
중첩 복원력은 양방향 미러링이 있는 서버 간에 데이터 복원력을 제공한 다음 양방향 미러링 또는 미러 가속 패리티가 있는 서버 내에서 복원력을 추가합니다. 중첩은 한 서버가 다시 시작되거나 사용할 수 없는 경우에도 데이터 복원력을 제공합니다. 스토리지 효율성은 중첩된 양방향 미러링의 경우 25%, 중첩된 미러 가속 패리티의 경우 약 35-40%입니다. 중첩된 복원력은 한 번에 두 개의 하드웨어 오류(드라이브 2개 또는 나머지 서버의 서버와 드라이브)를 안전하게 허용할 수 있습니다. 이 추가된 데이터 복원력으로 인해 두 서버 클러스터의 프로덕션 배포에 중첩된 복원력을 사용하는 것이 좋습니다. 자세한 내용은 중첩 회복력을 참조하세요.

서버 3개
세 개의 서버를 사용하면 내결함성과 성능을 향상시키려면 3방향 미러링을 사용해야 합니다. 3방향 미러링에서는 모든 데이터의 복사본 3개가 각 서버의 드라이브에 하나씩 보관됩니다. 스토리지 효율성은 33.3%이며, 1TB의 데이터를 쓰려면 스토리지 풀에 3TB 이상의 물리적 스토리지 용량이 필요합니다. 3방향 미러링을 사용하면 한 번에 두 개 이상의 하드웨어 문제(드라이브 또는 서버)를 안전하게 허용할 수 있습니다. 2개의 노드를 사용할 수 없게 되면 디스크의 2/3을 사용할 수 없고 가상 디스크에 액세스할 수 없으므로 스토리지 풀에서 쿼럼이 손실됩니다. 그러나 노드가 다운되고 다른 노드의 하나 이상의 디스크가 실패할 수 있으며 가상 디스크는 온라인 상태로 유지됩니다. 예를 들어 갑자기 다른 드라이브 또는 서버가 실패할 때 한 서버를 다시 부팅하는 경우 모든 데이터는 안전하고 지속적으로 액세스할 수 있습니다.
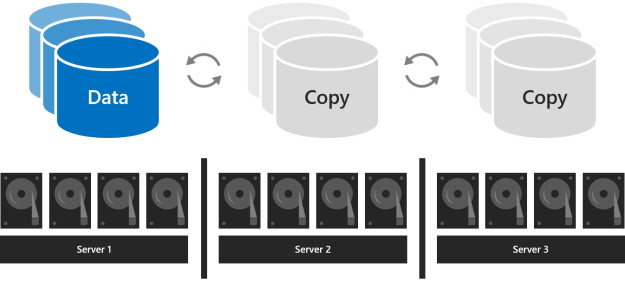
4개 이상의 서버가 있는 경우
서버가 4개 이상인 경우 각 볼륨에 대해 3방향 미러링, 이중 패리티("지우기 코딩"이라고도 함)를 사용할지 또는 미러 가속 패리티와 둘을 혼합할지 선택할 수 있습니다.
이중 패리티는 3방향 미러링과 동일한 내결함성을 제공하지만 스토리지 효율성은 향상됩니다. 서버가 4개인 경우 스토리지 효율성은 50.0%입니다. 2TB의 데이터를 저장하려면 스토리지 풀에 4TB의 물리적 스토리지 용량이 필요합니다. 이렇게 하면 서버 7개로 스토리지 효율성이 66.7%로 증가하고 스토리지 효율성은 최대 80.0%까지 증가합니다. 단점은 패리티 인코딩이 컴퓨팅 집약적이므로 성능을 제한할 수 있다는 것입니다.
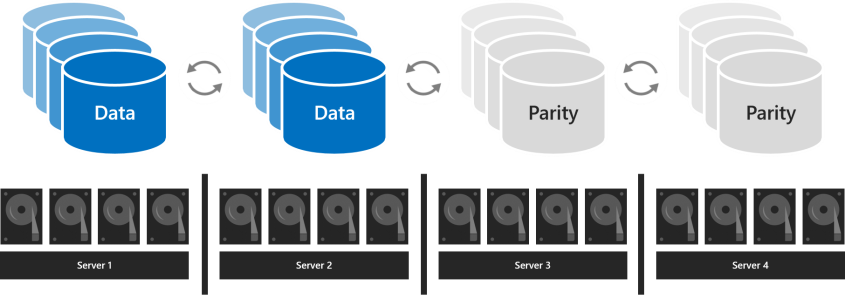
사용할 복원력 유형은 환경에 대한 성능 및 용량 요구 사항에 따라 달라집니다. 다음은 각 복원력 유형의 성능 및 스토리지 효율성을 요약한 표입니다.
| 복원력 유형 | 용량 효율성 | Speed |
|---|---|---|
| Mirror |

3방향 거울: 33% 양방향 미러: 50% |

최고 성능 |
| 미러 가속 패리티 |

미러 및 패리티의 비율에 따라 다름 |

미러보다 훨씬 느리지만 이중 패리티보다 최대 2배 빠릅니다. 큰 순차 쓰기 및 읽기에 가장 적합합니다. |
| Dual-parity |

서버 4대: 50% 16개 서버: 최대 80개% |

쓰기 시 가장 높은 I/O 대기 시간 및 CPU 사용량 큰 순차 쓰기 및 읽기에 가장 적합합니다. |
성능이 가장 중요한 경우
엄격한 대기 시간 요구 사항이 있거나 SQL Server 데이터베이스 또는 성능에 민감한 Hyper-V 가상 머신과 같이 혼합된 임의 IOPS가 많이 필요한 워크로드는 미러링을 사용하여 성능을 최대화하는 볼륨에서 실행되어야 합니다.
Tip
미러링이 다른 복원력 유형보다 빠릅니다. 거의 모든 성능 예제에 미러링을 사용합니다.
용량이 가장 중요한 경우
데이터 웨어하우스 또는 "콜드" 스토리지와 같이 자주 쓰지 않는 워크로드는 이중 패리티를 사용하여 스토리지 효율성을 최대화하는 볼륨에서 실행되어야 합니다. SoFS(Scale-Out 파일 서버), VDI(가상 데스크톱 인프라) 또는 빠른 드리프트 임의 IO 트래픽을 많이 생성하지 않거나 최상의 성능이 필요하지 않은 다른 워크로드와 같은 특정 다른 워크로드는 재량에 따라 이중 패리티를 사용할 수도 있습니다. 패리티는 미러링에 비해 CPU 사용률 및 IO 대기 시간, 특히 쓰기에서 필연적으로 증가합니다.
데이터가 대량으로 기록되는 경우
보관 또는 백업 대상과 같은 대규모 순차적 패스로 작성하는 워크로드에는 또 다른 옵션이 있습니다. 한 볼륨은 미러링과 이중 패리티를 혼합할 수 있습니다. 미러 부분에 먼저 데이터를 기록하고, 나중에 패리티 부분으로 순차적으로 이동됩니다. 이렇게 하면 컴퓨팅 집약적 패리티 인코딩이 더 오랜 시간 동안 수행되도록 하여 대규모 쓰기가 도착할 때 수집이 가속화되고 리소스 사용률이 줄어듭니다. 부분 크기 조정 시, 한 번에 발생하는 쓰기 수량(예: 하루 백업 하나)이 미러 영역에 편안하게 맞는지 확인해야 합니다. 예를 들어, 매일 100GB를 입력하는 경우 150GB에서 200GB는 미러링을 사용하고, 나머지는 이중 패리티를 사용하는 것을 고려해 보세요.
결과 스토리지 효율성은 선택한 비율에 따라 달라집니다.
Tip
데이터 수집을 통해 쓰기 성능이 갑자기 감소하는 것을 관찰하는 경우 미러 부분이 충분히 크지 않거나 미러 가속 패리티가 사용 사례에 적합하지 않음을 나타낼 수 있습니다. 예를 들어 쓰기 성능이 400MB/s에서 40MB/s로 감소하는 경우 미러 부분을 확장하거나 3방향 미러로 전환하는 것이 좋습니다.
NVMe, SSD 및 HDD를 사용하는 배포 정보
두 가지 유형의 드라이브가 있는 배포에서 더 빠른 드라이브는 캐싱을 제공하고 느린 드라이브는 용량을 제공합니다. 이 작업은 자동으로 발생합니다. 자세한 내용은 저장소 공간 다이렉트의 캐시 이해하기를 참조하세요. 이러한 배포에서 모든 볼륨은 궁극적으로 동일한 유형의 드라이브인 용량 드라이브에 상주합니다.
세 가지 유형의 드라이브를 모두 사용하는 배포에서는 가장 빠른 드라이브(NVMe)만 캐싱을 제공하여 용량을 제공하기 위해 두 가지 유형의 드라이브(SSD 및 HDD)를 남깁니다. 각 볼륨에 대해 SSD 계층에 전적으로 상주할지, 전적으로 HDD 계층에 있는지 또는 둘에 걸쳐 있는지 여부를 선택할 수 있습니다.
Important
SSD 계층을 사용하여 성능에 가장 중요한 워크로드를 올 플래시에 배치하는 것이 좋습니다.
볼륨 크기 선택
Azure 로컬 각 볼륨의 크기를 64TB로 제한하는 것이 좋습니다.
Tip
파일 서버 워크로드와 마찬가지로 VSS(볼륨 섀도 복사본 서비스) 및 Volsnap 소프트웨어 공급자를 사용하는 백업 솔루션을 사용하는 경우 볼륨 크기를 10TB로 제한하면 성능과 안정성이 향상됩니다. 최신 Hyper-V RCT API 및/또는 ReFS 블록 복제 및/또는 네이티브 SQL 백업 API를 사용하는 백업 솔루션은 최대 32TB 이상의 성능을 제공합니다.
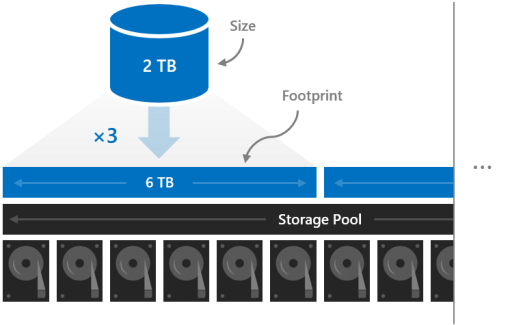
Footprint
볼륨의 크기는 사용할 수 있는 용량, 저장할 수 있는 데이터의 양을 나타냅니다. 이는 New-Volume cmdlet의 -Size 매개 변수에 의해 제공된 다음 Get-Volume cmdlet을 실행할 때 Size 속성에 나타납니다.
크기는 스토리지 풀에서 차지하는 총 물리적 스토리지 용량인 볼륨의 공간과 다릅니다. 발자국은 복원력 유형에 따라 달라집니다. 예를 들어, 3방향 미러링을 사용하는 볼륨은 차지하는 공간이 3배 큽니다.
볼륨의 자취는 스토리지 풀에 맞아야 합니다.
여유 용량 확보
할당되지 않은 스토리지 풀에 일부 용량을 남겨 두면 드라이브가 실패한 후 "현재 위치"를 복구할 수 있는 볼륨 공간이 제공되어 데이터 안전성과 성능이 향상됩니다. 충분한 용량이 있는 경우 즉시 병렬 복구를 통해 실패한 드라이브를 교체하기 전에도 볼륨을 전체 복원력으로 복원할 수 있습니다. 자동으로 진행됩니다.
서버당 최대 4개의 드라이브에 해당하는 용량 드라이브를 예약하는 것이 좋습니다. 재량에 따라 더 많은 것을 예약할 수 있지만, 이 최소 권장 사항은 드라이브가 고장 나면 즉시 병렬 복구가 성공할 수 있음을 보장합니다.

예를 들어 서버가 2개이고 1TB 용량 드라이브를 사용하는 경우 2 x 1 = 2TB의 풀을 예약으로 따로 둡니다. 3개의 서버와 1TB 용량 드라이브가 있는 경우 3 x 1 = 3TB를 예약으로 따로 둡니다. 4개 이상의 서버와 1TB 용량 드라이브가 있는 경우 4 x 1 = 4TB를 예약으로 따로 둡니다.
Note
세 가지 유형(NVMe + SSD + HDD)의 드라이브가 있는 클러스터에서는 서버당 하나의 SSD와 최대 4개의 드라이브에 해당하는 SSD를 예약하는 것이 좋습니다.
예: 용량 계획
하나의 4 서버 클러스터를 고려합니다. 각 서버에는 용량을 위해 일부 캐시 드라이브와 16개의 2TB 드라이브가 있습니다.
4 servers x 16 drives each x 2 TB each = 128 TB
스토리지 풀의 이 128TB에서 4개의 드라이브 또는 8TB를 따로 설정하여 오류가 발생한 후 드라이브를 교체하기 위해 서두르지 않고 현재 위치 복구를 수행할 수 있습니다. 이렇게 하면 볼륨을 만들 수 있는 풀에 120TB의 물리적 스토리지 용량이 남습니다.
128 TB – (4 x 2 TB) = 120 TB
매우 활발한 Hyper-V 가상 머신을 호스트하기 위해 배포가 필요하지만 보존해야 하는 오래된 파일 및 백업과 같은 콜드 스토리지도 많이 있다고 가정해 보겠습니다. 4개의 서버가 있으므로 4개의 볼륨을 만들어 보겠습니다.
처음 두 볼륨인 Volume1 및 Volume2에 가상 머신을 배치해 보겠습니다. ReFS를 파일 시스템(더 빠른 생성 및 검사점)으로 선택하고 복원력을 위해 3방향 미러링을 선택하여 성능을 극대화합니다. 다른 두 볼륨인 볼륨 3 및 볼륨 4에 콜드 스토리지를 배치해 보겠습니다. NTFS를 파일 시스템(데이터 중복 제거용)으로 선택하고 복원력을 위한 이중 패리티를 선택하여 용량을 최대화합니다.
모든 볼륨을 동일한 크기로 만들 필요는 없지만 간단히 하기 위해 12TB를 모두 만들 수 있습니다.
Volume1 및 Volume2 는 각각 12TB x 33.3% 효율성 = 36TB의 물리적 스토리지 용량을 차지합니다.
Volume3 및 Volume4 는 각각 12TB x 50.0% 효율성 = 24TB의 물리적 스토리지 용량을 차지합니다.
36 TB + 36 TB + 24 TB + 24 TB = 120 TB
4개의 볼륨은 풀에서 사용할 수 있는 실제 스토리지 용량에 정확히 맞습니다. Perfect!

Tip
모든 볼륨을 즉시 만들 필요는 없습니다. 언제든지 볼륨을 확장하거나 나중에 새 볼륨을 만들 수 있습니다.
간단히 하기 위해 이 예제에서는 전체 10진수(base-10) 단위를 사용합니다. 즉, 1TB = 1,000,000,000,000바이트입니다. 그러나 Windows 스토리지 수량은 이진(base-2) 단위로 표시됩니다. 예를 들어 각 2TB 드라이브는 Windows 1.82TiB로 표시됩니다. 마찬가지로 128TB 스토리지 풀은 116.41TiB로 표시됩니다. 예상된 일입니다.
Usage
다음 단계
자세한 내용은 다음을 참조하세요.