LoRA(Low Rank 적응)를 활용하여 Phi Silica 모델을 미세 조정하여 특정 사용 사례에 대한 성능을 향상시킬 수 있습니다. LoRA를 사용하여 Microsoft Windows 로컬 언어 모델인 Phi Silica를 최적화하면 보다 정확한 결과를 얻을 수 있습니다. 이 프로세스에는 LoRA 어댑터를 학습한 다음 유추 중에 적용하여 모델의 정확도를 향상시키는 작업이 포함됩니다.
필수 조건
- Phi Silica의 응답을 향상시키기 위한 사용 사례를 확인했습니다.
- 평가 기준을 선택하여 '좋은 응답'이 무엇인지 결정했습니다.
- Phi Silica API를 시도했지만 평가 기준을 충족하지 않습니다.
당신의 어댑터를 훈련하세요
Windows 11에서 Phi Silica 모델을 미세 조정하기 위해 LoRA 어댑터를 학습하려면 먼저 학습 프로세스에서 사용할 데이터 세트를 생성해야 합니다.
LoRA 어댑터에 사용할 데이터 세트 생성
데이터 세트를 생성하려면 데이터를 두 개의 파일로 분할해야 합니다.
train.json– 어댑터를 학습하는 데 사용됩니다.test.json– 학습 중 및 학습 후에 어댑터의 성능을 평가하는 데 사용됩니다.
두 파일 모두 JSON 형식을 사용해야 합니다. 여기서 각 줄은 단일 샘플을 나타내는 별도의 JSON 개체입니다. 각 샘플에는 사용자와 도우미 간에 교환되는 메시지 목록이 포함되어야 합니다.
모든 메시지 개체에는 다음 두 개의 필드가 필요합니다.
content: 메시지의 텍스트입니다.role:"user"또는"assistant"로, 보낸 사람을 나타냅니다.
다음 예제를 참조하세요.
{"messages": [{"content": "Hello, how do I reset my password?", "role": "user"}, {"content": "To reset your password, go to the settings page and click 'Reset Password'.", "role": "assistant"}]}
{"messages": [{"content": "Can you help me find nearby restaurants?", "role": "user"}, {"content": "Sure! Here are some restaurants near your location: ...", "role": "assistant"}]}
{"messages": [{"content": "What is the weather like today?", "role": "user"}, {"content": "Today's forecast is sunny with a high of 25°C.", "role": "assistant"}]}
교육 팁:
각 샘플 줄의 끝에는 쉼표가 필요하지 않습니다.
가능한 한 많은 고품질 및 다양한 예제를 포함합니다. 최상의 결과를 얻으려면
train.json파일에서 몇 천 개 이상의 학습 샘플을 수집하십시오.파일은
test.json더 작을 수 있지만 모델이 처리할 것으로 예상되는 상호 작용 유형을 포함해야 합니다.train.json및test.json파일을 만들고 각 파일에는 한 줄당 하나의 JSON 객체가 포함되며, 각 객체에는 사용자와 도우미 간의 짧은 대화가 포함됩니다. 데이터의 품질과 수량은 LoRA 어댑터의 효과에 큰 영향을 줍니다.
AI 도구 키트에서 LoRA 어댑터 학습
Visual Studio Code용 AI 도구 키트를 사용하여 LoRA 어댑터를 학습하려면 먼저 다음과 같은 필수 구성 요소가 필요합니다.
AzureContainer Apps에서 사용 가능한 할당량이 있는 Azure 구독.
- 미세 조정 작업을 효율적으로 실행하려면 A100 GPU를 사용하는 것이 좋습니다.
- Azure Portal에서 사용 가능한 할당량이 있는지 확인합니다. 할당량을 찾는 데 도움이 되도록 할당량 보기를 참조하세요.
Visual Studio Code가 아직 없는 경우 설치해야 합니다.
Visual Studio Code용 AI 도구 키트를 설치하려면 다음을 수행합니다.
AI 도구 키트 확장이 다운로드되면 Visual Studio Code 내의 왼쪽 도구 모음 창에서 액세스할 수 있습니다.
도구>미세 조정으로 이동합니다.
프로젝트 이름 및 프로젝트 위치를 입력합니다.
모델 카탈로그에서 "microsoft/phi-silica"를 선택합니다.
"프로젝트 구성"을 선택합니다.
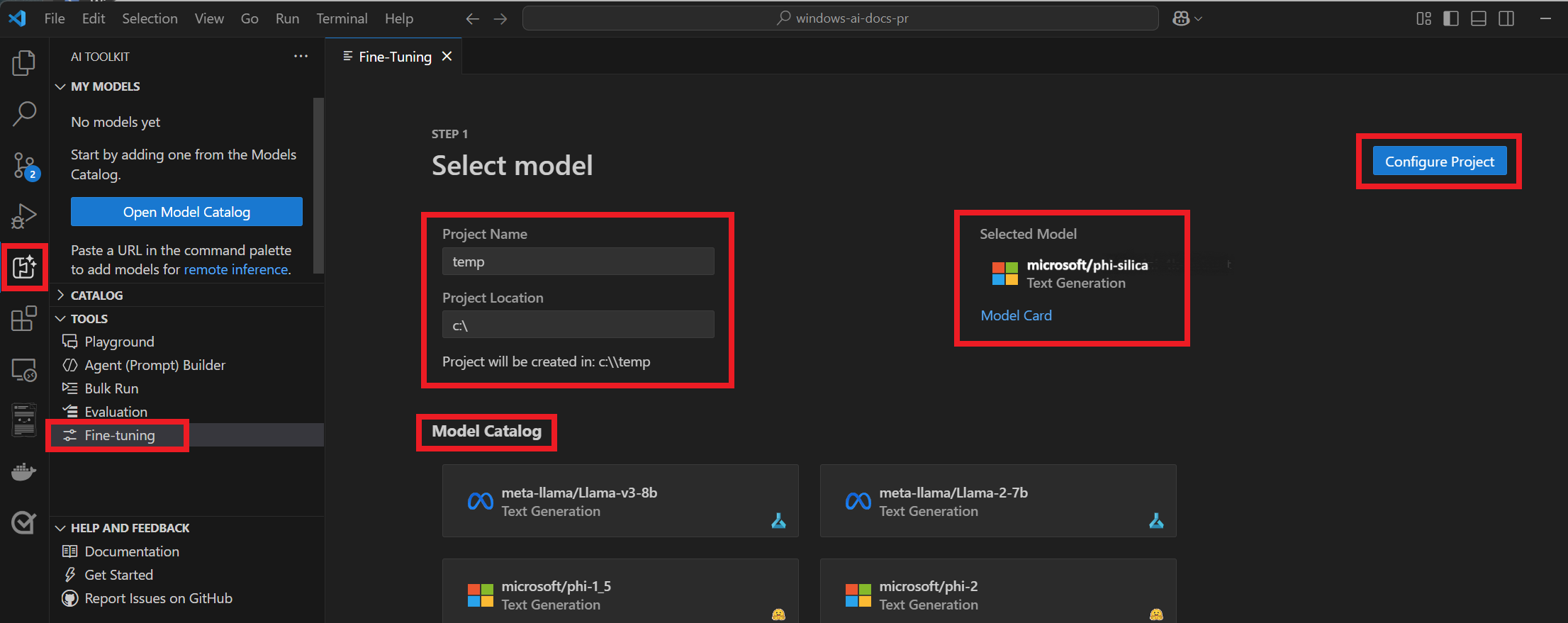
최신 버전의 피 실리카를 선택합니다.
데이터>학습 데이터 세트 이름 및 테스트 데이터 세트 이름 아래에서 사용자
train.json및test.json파일을 선택합니다."프로젝트 생성"을 선택합니다. 새 VS Code 창이 열립니다.
Azure 작업이 올바르게 배포되고 실행되도록 올바른 워크로드 프로필이 bicep 파일에서 선택되어 있는지 확인합니다. 아래에 다음을 추가합니다.
workloadProfiles{ workloadProfileType: 'Consumption-GPU-NC24-A100' name: 'GPU' }"새 미세 조정 작업"을 선택하고 작업의 이름을 입력합니다.
Azure 구독에 액세스할 Microsoft 계정을 선택하라는 대화 상자가 나타납니다.
계정이 선택되면 구독 드롭다운 메뉴에서 리소스 그룹을 선택해야 합니다.
이제 미세 조정 작업이 성공적으로 시작되었으며, 작업 상태를 확인할 수 있습니다. 작업이 완료되면 "다운로드" 단추를 선택하여 새로 학습된 LoRA 어댑터를 다운로드할 수 있습니다. 일반적으로 미세 조정 작업을 완료하는 데 평균 45~60분이 걸립니다.
유추
학습은 AI 모델이 큰 데이터 세트에서 학습하여 패턴과 상관 관계를 인식하는 초기 단계입니다. 반면 유추는 학습된 모델(이 경우 Phi Silica)이 새 데이터(LoRA 어댑터)를 사용하여 더 많은 사용자 지정 출력을 생성할 예측 또는 결정을 내리는 애플리케이션 단계입니다.
학습된 LoRA 어댑터를 적용하려면:
AI 개발자 갤러리 앱을 사용합니다. AI 개발자 갤러리는 샘플 코드를 보고 내보내는 것 외에도 로컬 AI 모델 및 API를 실험할 수 있는 앱입니다. AI 개발자 갤러리에 대해 자세히 알아봅니다.
AI 개발자 갤러리를 설치한 후 앱을 열고 "AI API" 탭을 선택한 다음, "Phi Silica LoRA"를 선택합니다.
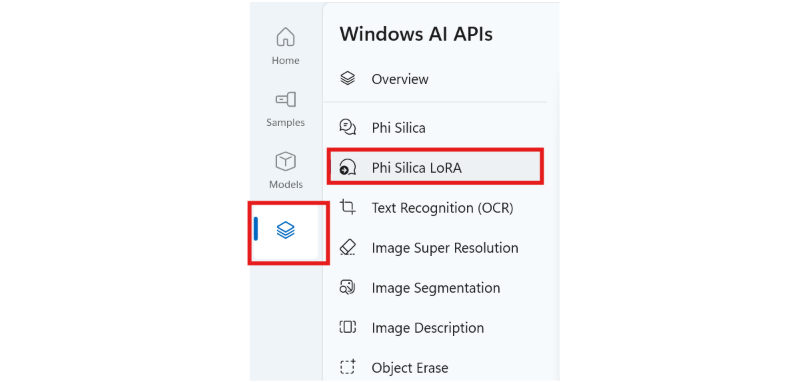
어댑터 파일을 선택합니다. 저장할 기본 위치는 다음과
Desktop/lora_lab/trainedLora같습니다."시스템 프롬프트"와 "프롬프트" 필드를 완성하세요. 그런 다음, "생성"을 선택하여 LoRA 어댑터를 사용 또는 사용하지 않는 Phi Silica의 차이를 확인합니다.
프롬프트 및 시스템 프롬프트를 실험하여 출력에 어떻게 차이가 있는지 확인합니다.
"샘플 내보내기"를 선택하여 이 샘플 코드만 포함된 독립 실행형 Visual Studio 솔루션을 다운로드합니다.
응답 생성
AI 개발자 갤러리를 사용하여 새 LoRA 어댑터를 테스트한 후에는 아래 코드 샘플을 사용하여 Windows 앱에 어댑터를 추가할 수 있습니다.
using Microsoft.Windows.AI.Text;
using Microsoft.Windows.AI.Text.Experimental;
// Path to the LoRA adapter file
string adapterFilePath = "C:/path/to/adapter/file.safetensors";
// Prompt to be sent to the LanguageModel
string prompt = "How do I add a new project to my Visual Studio solution?";
// Wait for LanguageModel to be ready
if (LanguageModel.GetReadyState() == AIFeatureReadyState.NotReady)
{
var languageModelDeploymentOperation = LanguageModel.EnsureReadyAsync();
await languageModelDeploymentOperation;
}
// Create the LanguageModel session
var session = LanguageModel.CreateAsync();
// Create the LanguageModelExperimental
var languageModelExperimental = new LanguageModelExperimental(session);
// Load the LoRA adapter
LowRankAdaptation loraAdapter = languageModelExperimental.LoadAdapter(adapterFilePath);
// Set the adapter in LanguageModelOptionsExperimental
LanguageModelOptionsExperimental options = new LanguageModelOptionsExperimental
{
LoraAdapter = loraAdapter
};
// Generate a response with the LoRA adapter provided in the options
var response = await languageModelExperimental.GenerateResponseAsync(prompt, options);
책임 있는 AI - 미세 조정의 위험 및 제한 사항
고객이 Phi Silica를 미세 조정하면 특정 작업 및 도메인에 대한 모델 성능 및 정확도를 향상시킬 수 있지만 고객이 알아야 할 새로운 위험과 제한 사항을 도입할 수도 있습니다. 이러한 위험 및 제한 사항 중 일부는 다음과 같습니다.
데이터 품질 및 표현: 미세 조정에 사용되는 데이터의 품질과 대표성은 모델의 동작 및 출력에 영향을 줄 수 있습니다. 데이터가 시끄럽거나 불완전하거나 오래되거나 스테레오타입과 같은 유해한 콘텐츠가 포함된 경우 모델은 이러한 문제를 상속하고 부정확하거나 유해한 결과를 생성할 수 있습니다. 예를 들어 데이터에 성별 고정관념이 포함된 경우 모델은 이를 증폭하고 성차별적인 언어를 생성할 수 있습니다. 고객은 데이터를 신중하게 선택하고 사전 처리하여 의도한 작업 및 도메인에 대해 관련성이 있고 다양하며 균형을 유지해야 합니다.
모델 견고성 및 일반화: 특히 데이터가 너무 좁거나 특정한 경우 미세 조정 후 다양하고 복잡한 입력 및 시나리오를 처리하는 모델의 기능이 감소할 수 있습니다. 모델은 데이터에 과잉 맞춤되고 일반적인 지식과 기능 중 일부를 잃을 수 있습니다. 예를 들어 데이터가 스포츠에만 해당되는 경우 모델은 질문에 대답하거나 다른 항목에 대한 텍스트를 생성하는 데 어려움을 겪을 수 있습니다. 고객은 다양한 입력 및 시나리오에서 모델의 성능과 견고성을 평가하고 해당 범위를 벗어난 작업 또는 도메인에 모델을 사용하지 않도록 해야 합니다.
Regurgitation: Microsoft 또는 타사 고객이 학습 데이터를 사용할 수 없지만 제대로 조정되지 않은 모델은 학습 데이터를 역류하거나 직접 반복할 수 있습니다. 고객은 교육 데이터에서 PII 또는 기타 보호된 정보를 제거할 책임이 있으며, 과잉 맞춤 또는 저품질 응답에 대해 미세 조정된 모델을 평가해야 합니다. 역류를 방지하기 위해 고객은 크고 다양한 데이터 세트를 제공하는 것이 좋습니다.
모델 투명성 및 설명 가능성: 특히 데이터가 복잡하거나 추상적인 경우 모델의 논리와 추론은 미세 조정 후 더 불투명하고 이해하기 어려울 수 있습니다. 미세 조정된 모델은 예기치 않거나 일관되지 않거나 모순되는 출력을 생성할 수 있으며 고객은 모델이 해당 출력에 도착한 방법 또는 이유를 설명하지 못할 수 있습니다. 예를 들어 데이터가 법적 또는 의료 조건에 관한 경우 모델은 부정확하거나 오해의 소지가 있는 출력을 생성할 수 있으며 고객은 이를 확인하거나 정당화하지 못할 수 있습니다. 고객은 모델의 출력과 동작을 모니터링하고 감사하며 모델의 최종 사용자에게 명확하고 정확한 정보와 지침을 제공해야 합니다.