이 자습서의 이전 단계에서는 컴퓨터에 PyTorch를 설치했습니다. 이제 모델을 만드는 데 사용할 데이터로 코드를 설정하는 데 사용합니다.
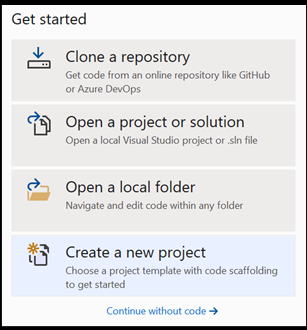
Visual Studio 내에서 새 프로젝트를 엽니다.
- Visual Studio를 열고 을 선택합니다
create a new project.
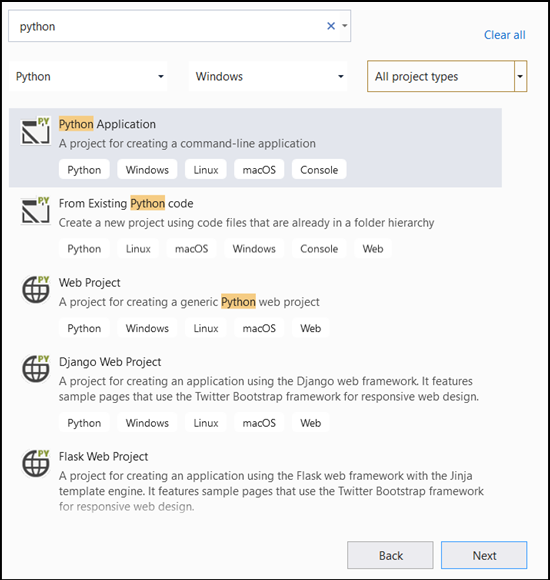
- 검색 창에서 프로젝트 템플릿으로 입력
Python하고 선택합니다Python Application.
- 구성 창에서 다음을 수행합니다.
- 프로젝트 이름을 지정합니다. 여기서는 DataClassifier라고 합니다.
- 프로젝트의 위치를 선택합니다.
- VS2019를 사용하는 경우,
Create directory for solution이(가) 선택되어 있는지 확인하세요. - VS2017을 사용하는 경우
Place solution and project in the same directory이(가) 선택 취소되어 있는지 확인하십시오.
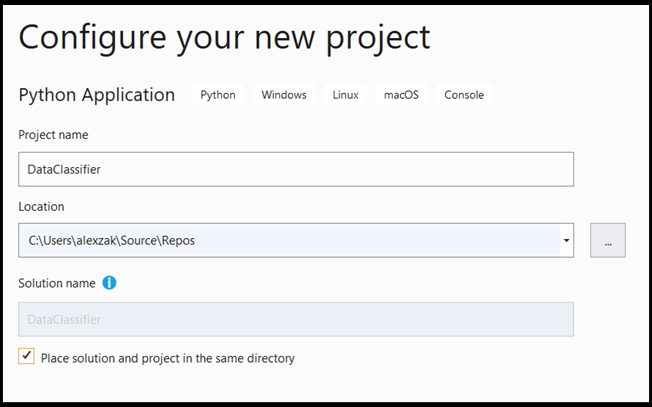
프로젝트를 생성하려면 create를 누르십시오.
Python 인터프리터 만들기
이제 새 Python 인터프리터를 정의해야 합니다. 여기에는 최근에 설치한 PyTorch 패키지가 포함되어야 합니다.
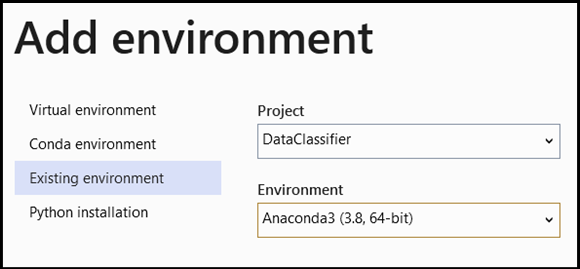
- 인터프리터 선택 영역으로 이동하고 다음을 선택합니다
Add Environment.

- 창에서 을
Add Environment선택하고Existing environmentAnaconda3 (3.6, 64-bit)선택합니다. 여기에는 PyTorch 패키지가 포함됩니다.
새 Python 인터프리터 및 PyTorch 패키지를 테스트하려면 파일에 다음 코드를 DataClassifier.py 입력합니다.
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
출력은 아래와 유사한 임의의 5x3 텐서여야 합니다.
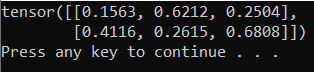
비고
자세히 알아보고 싶나요? PyTorch 공식 웹 사이트를 방문하십시오.
데이터 이해
피셔의 아이리스 꽃 데이터 세트에서 모델을 학습시킬 것입니다. 이 유명한 데이터 세트에는 아이리스 세토사, 아이리스 버진카, 아이리스 베르시콜러 등 3종의 붓꽃 종 각각에 대한 50개의 레코드가 포함되어 있습니다.
여러 버전의 데이터 세트가 게시되었습니다. UCI Machine Learning 리포지토리에서 아이리스 데이터 세트를 찾거나 Python Scikit-learn 라이브러리에서 직접 데이터 세트를 가져오거나 이전에 게시된 다른 버전을 사용할 수 있습니다. 아이리스 꽃 데이터 세트에 대해 알아보려면 위키백과 페이지를 방문하세요.
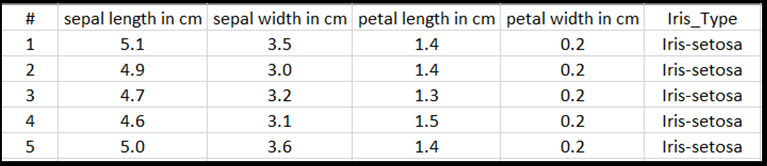
이 자습서에서는 테이블 형식의 입력으로 모델을 학습시키는 방법을 보여 주려면 Excel 파일로 내보낸 아이리스 데이터 세트를 사용합니다.
Excel 표의 각 줄에는 붓꽃의 네 가지 특징인 cm의 세팔 길이, cm의 세팔 너비, cm의 꽃잎 길이 및 꽃잎 너비(cm)가 표시됩니다. 이러한 기능은 입력으로 제공됩니다. 마지막 열에는 이러한 매개 변수와 관련된 아이리스 형식이 포함되며 회귀 출력을 나타냅니다. 데이터 세트에는 총 4개의 기능 중 150개의 입력이 포함되며, 각 입력은 관련 아이리스 형식과 일치합니다.
회귀 분석은 입력 변수와 결과 간의 관계를 확인합니다. 입력에 따라 모델은 붓꽃 세토사, 아이리스-베르시콜러, 아이리스-버진카의 세 가지 붓꽃 유형 중 하나인 올바른 유형의 출력을 예측하는 방법을 배웁니다.
중요합니다
다른 데이터 세트를 사용하여 고유한 모델을 만들려는 경우 시나리오에 따라 모델 입력 변수 및 출력을 지정해야 합니다.
데이터 세트를 로드합니다.
Excel 형식으로 아이리스 데이터 세트를 다운로드합니다. 여기에서 찾을 수 있습니다.
DataClassifier.py폴더의 파일에서 다음 import 문을 추가하여 필요한 모든 패키지에 액세스할 수 있습니다.
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
볼 수 있듯이 pandas(Python 데이터 분석) 패키지를 사용하여 신경망을 빌드하기 위한 모듈 및 확장 가능한 클래스가 포함된 데이터 및 torch.nn 패키지를 로드하고 조작합니다.
- 메모리에 데이터를 로드하고 클래스 수를 확인합니다. 각 아이리스 유형의 항목이 50개씩 있을 것으로 예상합니다. PC에서 데이터 세트의 위치를 지정해야 합니다.
DataClassifier.py 파일에 다음 코드를 추가합니다.
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
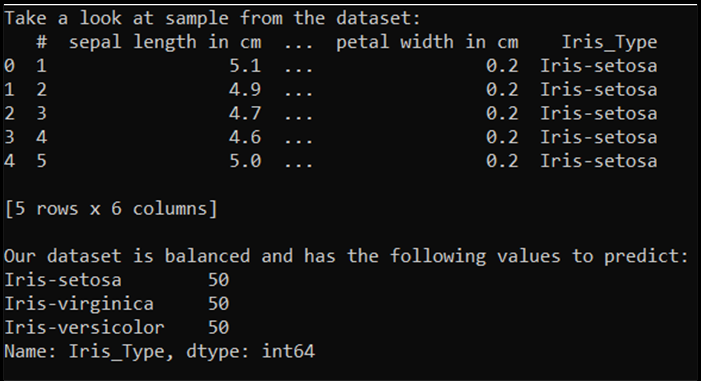
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
이 코드를 실행하면 예상 출력은 다음과 같습니다.
데이터 세트를 사용하고 모델을 학습하려면 입력 및 출력을 정의해야 합니다. 입력에는 150줄의 기능이 포함되며 출력은 아이리스 형식 열입니다. 사용할 신경망에는 숫자 변수가 필요하므로 출력 변수를 숫자 형식으로 변환합니다.
- 데이터 세트에 출력을 숫자 형식으로 나타내고 회귀 입력 및 출력을 정의하는 새 열을 만듭니다.
DataClassifier.py 파일에 다음 코드를 추가합니다.
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
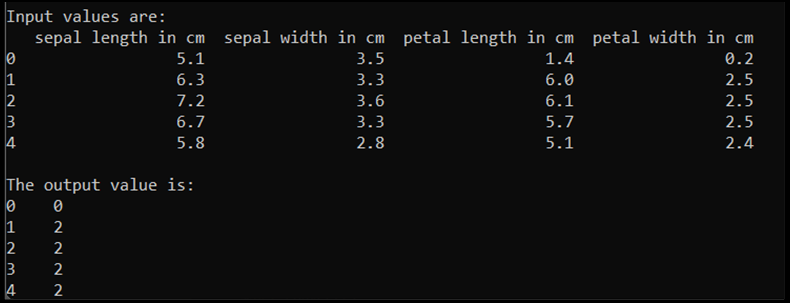
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
이 코드를 실행하면 예상 출력은 다음과 같습니다.
모델을 학습하려면 모델 입력 및 출력을 Tensor 형식으로 변환해야 합니다.
- Tensor로 변환:
DataClassifier.py 파일에 다음 코드를 추가합니다.
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
코드를 실행하면 다음과 같이 예상 출력에 입력 및 출력 형식이 표시됩니다.

입력 값은 150개입니다. 약 60개%는 모델 학습 데이터가 될 것입니다. 유효성 검사를 위해 20개%, 테스트에 대해 30개% 유지합니다.
이 자습서에서는 학습 데이터 세트의 일괄 처리 크기가 10으로 정의됩니다. 학습 집합에는 95개의 항목이 있습니다. 즉, 평균적으로 학습 집합을 한 번 순회하는 데 9개의 전체 배치가 필요합니다(하나의 epoch). 유효성 검사 및 테스트 집합의 일괄 처리 크기를 1로 유지합니다.
- 데이터를 분할하여 집합을 학습, 유효성 검사 및 테스트합니다.
DataClassifier.py 파일에 다음 코드를 추가합니다.
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
다음 단계
데이터가 준비되면 PyTorch 모델을 학습할 차례입니다.