블록 복제
블록 복제 작업은 애플리케이션을 대신하여 파일 바이트 범위를 복사하도록 파일 시스템에 지시합니다. 대상 파일은 원본 파일과 같거나 다를 수 있습니다.
파일 시스템은 클러스터 및 익스텐트의 매핑을 관리하며, 기본 파일 데이터를 읽고 쓰는 대신 VCN(가상 클러스터 번호)을 LCN(논리 클러스터 번호) 매핑으로 변경하여 복사를 수행할 수 있습니다. 이렇게 하면 복사가 더 빠르게 완료되고 기본 스토리지에 대한 I/O가 더 적게 생성됩니다. 또한 이제 블록 복제 후 여러 파일이 논리 클러스터를 공유하여 동일한 클러스터를 디스크에 여러 번 저장하지 않음으로써 용량을 절약할 수 있습니다.
블록 복제 작업은 파일 간에 제공되는 격리를 중단하지 않습니다. 블록 복제가 완료되면 원본 파일에 대한 쓰기가 대상에 표시되며 그 반대의 경우도 마찬가지입니다.
블록 복제는 Windows Server 2016부터 ReFS 파일 시스템 형식에서만 사용할 수 있습니다. Windows 11 Moment 5 업데이트(KB5034848) 이상 릴리스부터는 지원되는 Windows 복사 작업에서 기본적으로 차단 복제가 발생합니다.
ReFS에서 블록 복제
Windows Server 2016에서 ReFS는 원본 영역에서 대상 영역으로 논리 클러스터(즉, 볼륨의 물리적 위치)를 다시 매핑하여 블록 복제를 구현합니다. 그런 다음, 쓰기 시 할당 메커니즘을 사용하여 해당 영역 간의 격리를 보장합니다. 원본 및 대상 영역은 동일하거나 다른 파일에 있을 수 있습니다.
이 구현에서는 시작 및 끝 파일 오프셋을 클러스터 경계에 맞춰야 합니다. Windows Server 2016의 ReFS에서 클러스터 크기는 기본적으로 4KB이지만 필요에 따라 64KB로 설정할 수 있습니다. 클러스터 크기는 포맷 시에 설정되는 볼륨 수준 매개 변수입니다.
제한 사항 및 설명
- 원본 및 대상 영역은 클러스터 경계에서 시작하고 끝나야 합니다.
- 복제된 영역의 길이는 4GB 미만이어야 합니다.
- 대상 영역은 파일의 끝을 지나 확장되면 안 됩니다. 애플리케이션이 복제된 데이터로 대상을 확장하려면 먼저 SetEndOfFile을 호출해야 합니다.
- 원본 및 대상 영역이 동일한 파일에 있는 경우 겹치지 않아야 합니다. 애플리케이션이 블록 복제 작업을 더 이상 겹치지 않는 여러 블록 복제로 분할하여 진행할 수 있습니다.
- 원본 및 대상 파일은 동일한 ReFS 볼륨에 있어야 합니다.
- 원본 및 대상 파일은 무결성 스트림 설정이 동일해야 합니다. 즉, 무결성 스트림을 두 파일 모두에서 사용하도록 설정하거나 두 파일 모두에서 사용하지 않도록 설정해야 합니다.
- 원본 파일이 스파스인 경우 대상 파일도 스파스여야 합니다.
- 블록 복제 작업은 수준 2 편의적 잠금이라고도 하는 공유 편의적 잠금을 중단합니다.
- ReFS 볼륨은 Windows Server 2016에서 포맷되어 있어야 하며 Windows 장애 조치(failover) 클러스터링을 사용하는 경우 포맷 시 클러스터링 기능 수준이 Windows Server 2016 이상이어야 합니다.
예
X와 Y라는 두 개의 파일이 있고 각 파일은 3개의 고유한 영역으로 구성되어 있다고 가정해 보겠습니다. 각 파일 영역은 볼륨의 고유한 영역에 저장됩니다. 파일 시스템은 각 볼륨 영역이 하나의 파일 영역에서 참조된다는 정보를 저장합니다.
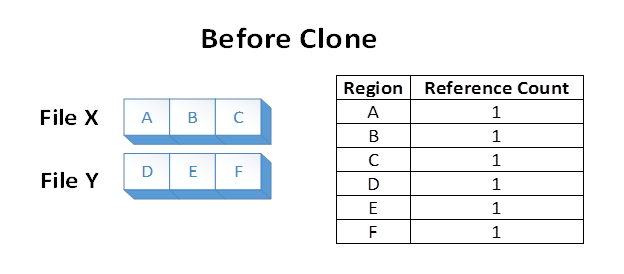
이제 애플리케이션이 파일 X에서 현재 E가 있는 오프셋의 파일 Y로 파일 영역 A 및 B에 대해 블록 복제 작업을 실행한다고 가정합니다. 다음과 같은 파일 시스템 상태가 생성됩니다.
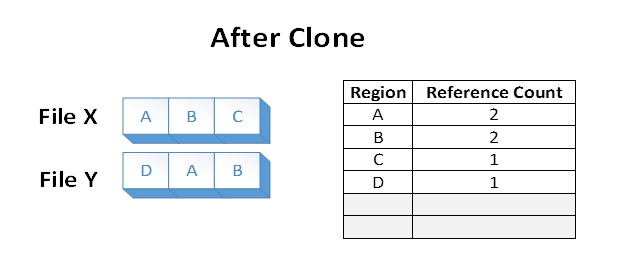
영역 A와 B의 데이터는 ReFS 볼륨 내에서 VCN을 LCN 매핑으로 변경하여 파일 X에서 파일 Y로 효과적으로 복제되었습니다. 영역 A와 B를 지원하는 디스크 익스텐트를 읽지 않았으며 작업 중에 이전 영역 E와 F를 지원하는 디스크 익스텐트를 덮어쓰지도 않았습니다.
파일 X 및 Y는 이제 디스크에서 논리 클러스터를 공유합니다. 이는 테이블에 표시된 참조 개수에 반영됩니다. 공유하면 영역 A와 B가 기본 볼륨에서 중복된 경우보다 볼륨 사용량이 줄어듭니다.
이제 애플리케이션이 파일 X의 영역 A를 덮어쓴다고 가정합니다. ReFS는 A의 복제본을 만드는데 이 복제본을 G라고 하겠습니다. 그런 다음, ReFS는 G를 파일 X에 매핑하고 수정 사항을 적용합니다. 이렇게 하면 파일 간의 격리가 유지되고 참조 개수가 적절하게 업데이트됩니다.
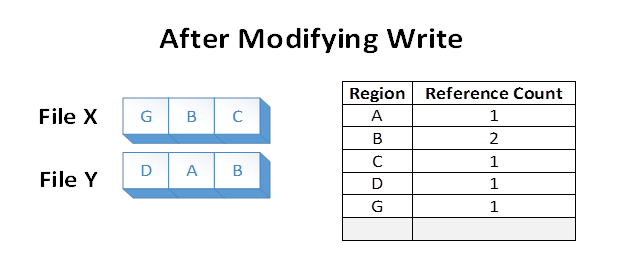
쓰기를 수정한 후에도 영역 B는 디스크에서 계속 공유됩니다. 영역 A가 클러스터보다 큰 경우 수정된 클러스터만 중복되고 나머지 부분은 공유된 상태로 유지됩니다.