정확한 Direct3D API 호출 프로파일링(Direct3D 9)
기능적인 Microsoft Direct3D 애플리케이션이 있고 성능을 향상시키려면 일반적으로 기성 프로파일링 도구 또는 일부 사용자 지정 측정 기술을 사용하여 하나 이상의 API(애플리케이션 프로그래밍 인터페이스) 호출을 실행하는 데 걸리는 시간을 측정합니다. 이 작업을 수행했지만 렌더링 시퀀스마다 다른 타이밍 결과를 가져오거나 실제 실험 결과를 유지하지 않는 가설을 만드는 경우 다음 정보를 통해 이유를 이해하는 데 도움이 될 수 있습니다.
여기에 제공된 정보는 다음에 대한 지식과 경험이 있다는 가정을 기반으로 합니다.
- C/C++ 프로그래밍
- Direct3D API 프로그래밍
- API 타이밍 측정
- 비디오 카드 및 소프트웨어 드라이버
- 이전 프로파일링 환경에서 설명할 수 없는 결과 가능
Direct3D를 정확하게 프로파일링하기가 어렵습니다.
프로파일러가 각 API 호출에 소요된 시간을 보고합니다. 이는 핫 스폿을 찾아서 조정하여 성능을 향상시키기 위해 수행됩니다. 프로파일러 및 프로파일링 기술에는 다양한 종류가 있습니다.
- 샘플링 프로파일러가 실행 중인 함수를 샘플링하거나 기록하기 위해 특정 간격으로 각성하는 데 많은 시간이 유휴 상태입니다. 각 호출에 소요된 시간의 백분율을 반환합니다. 일반적으로 샘플링 프로파일러가 애플리케이션에 매우 침습적이지 않으며 애플리케이션의 오버헤드에 최소한의 영향을 미칩니다.
- 계측 프로파일러가 호출이 반환되는 데 걸리는 실제 시간을 측정합니다. 시작 및 중지 구분 기호를 애플리케이션으로 컴파일해야 합니다. 계측 프로파일러가 샘플링 프로파일러보다 애플리케이션에 비교적 더 침습적입니다.
- 고성능 타이머와 함께 사용자 지정 프로파일링 기술을 사용할 수도 있습니다. 이렇게 하면 계측 프로파일러와 매우 유사한 결과가 생성됩니다.
사용되는 프로파일러 또는 프로파일링 기술의 유형은 정확한 측정을 생성하는 과제의 일부일 뿐입니다.
프로파일링은 예산 성능에 도움이 되는 답변을 제공합니다. 예를 들어 API 호출이 실행할 평균 1,000 시계 주기를 알고 있다고 가정해 보겠습니다. 다음과 같은 성능에 대한 몇 가지 결론을 어설션할 수 있습니다.
- 2GHz CPU(렌더링 시간의 50%를 사용)는 이 API를 초당 100만 번 호출하는 것으로 제한됩니다.
- 초당 30개의 프레임을 달성하려면 이 API를 프레임당 33,000회 이상 호출할 수 없습니다.
- 프레임당 3.3K 개체만 렌더링할 수 있습니다(각 개체의 렌더링 시퀀스에 대해 이러한 API 호출 중 10개라고 가정).
즉, API 호출당 충분한 시간이 있는 경우 대화형으로 렌더링할 수 있는 기본 형식 수와 같은 예산 질문에 대답할 수 있습니다. 그러나 계측 프로파일러가 반환하는 원시 숫자는 예산 질문에 정확하게 대답하지 않습니다. 그래픽 파이프라인에는 작업을 수행해야 하는 구성 요소 수, 구성 요소 간의 작업 흐름을 제어하는 프로세서 수, 런타임 및 파이프라인의 효율성을 높이기 위해 설계된 드라이버에서 구현된 최적화 전략과 같은 복잡한 디자인 문제가 있기 때문입니다.
각 API 호출은 여러 구성 요소를 통과합니다.
각 호출은 애플리케이션에서 비디오 카드 가는 길에 여러 구성 요소에 의해 처리됩니다. 예를 들어 단일 삼각형을 그리기 위한 두 개의 호출이 포함된 다음 렌더링 시퀀스를 고려합니다.
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
다음 개념 다이어그램은 호출이 통과해야 하는 다양한 구성 요소를 보여 줍니다.

애플리케이션은 장면을 제어하고, 사용자 상호 작용을 처리하고, 렌더링을 수행하는 방법을 결정하는 Direct3D를 호출합니다. 이 모든 작업은 Direct3D API 호출을 사용하여 런타임으로 전송되는 렌더링 시퀀스에서 지정됩니다. 렌더링 시퀀스는 사실상 하드웨어 독립적입니다(즉, API 호출은 하드웨어 독립적이지만 애플리케이션은 비디오 카드 지원하는 기능에 대해 알아봅니다).
런타임은 이러한 호출을 디바이스 독립적 형식으로 변환합니다. 런타임은 애플리케이션과 드라이버 간의 모든 통신을 처리하므로 애플리케이션이 둘 이상의 호환되는 하드웨어에서 실행됩니다(필요한 기능에 따라 다름). 함수 호출을 측정할 때 계측 프로파일러가 함수에 소요된 시간과 함수가 반환되는 시간을 측정합니다. 계측 프로파일러의 한 가지 제한 사항은 드라이버가 결과 작업을 비디오 카드 보내는 데 걸리는 시간이나 비디오 카드 작업을 처리하는 데 걸리는 시간을 포함하지 않을 수 있다는 것입니다. 즉, 기성 계측 프로파일러가 각 함수 호출과 연결된 모든 작업의 특성을 지정하지 못합니다.
소프트웨어 드라이버는 비디오 카드 대한 하드웨어 관련 지식을 사용하여 디바이스 독립적 명령을 비디오 카드 명령 시퀀스로 변환합니다. 또한 드라이버는 비디오 카드 전송되는 명령 시퀀스를 최적화하여 비디오 카드 렌더링을 효율적으로 수행할 수 있습니다. 이러한 최적화로 인해 프로파일링 문제가 발생할 수 있습니다. 이는 수행된 작업의 양이 표시되는 작업이 아니기 때문입니다(이를 고려하기 위해 최적화를 이해해야 할 수도 있음). 드라이버는 일반적으로 비디오 카드 모든 명령 처리를 완료하기 전에 런타임에 컨트롤을 반환합니다.
비디오 카드 꼭짓점 및 인덱스 버퍼, 텍스처, 렌더링 상태 정보 및 그래픽 명령의 데이터를 결합하여 대부분의 렌더링을 수행합니다. 비디오 카드 렌더링이 완료되면 렌더링 시퀀스에서 만든 작업이 완료됩니다.
모든 항목을 렌더링하려면 각 Direct3D API 호출을 각 구성 요소(런타임, 드라이버 및 비디오 카드)에서 처리해야 합니다.
구성 요소를 제어하는 프로세서가 둘 이상 있습니다.
애플리케이션, 런타임 및 드라이버가 하나의 프로세서에 의해 제어되고 비디오 카드 별도의 프로세서에 의해 제어되기 때문에 이러한 구성 요소 간의 관계는 더욱 복잡합니다. 다음 다이어그램에서는 중앙 처리 장치(CPU) 및 GPU(그래픽 처리 장치)의 두 가지 종류의 프로세서를 보여 줍니다.
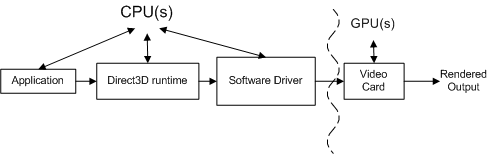
PC 시스템에는 하나 이상의 CPU와 하나의 GPU가 있지만 둘 중 하나 이상이 있을 수 있습니다. CPU는 마더보드에 있으며 GPU는 마더보드 또는 비디오 카드 있습니다. CPU 속도는 마더보드의 클록 칩에 의해 결정되며 GPU의 속도는 별도의 클록 칩에 의해 결정됩니다. CPU 클록은 애플리케이션, 런타임 및 드라이버에서 수행하는 작업의 속도를 제어합니다. 애플리케이션은 런타임 및 드라이버를 통해 GPU에 작업을 보냅니다.
CPU와 GPU는 일반적으로 서로 독립적으로 서로 다른 속도로 실행됩니다. GPU는 작업을 사용할 수 있는 즉시 작업에 응답할 수 있습니다(GPU가 이전 작업 처리를 완료한 것으로 가정). GPU 작업은 위 그림의 곡선으로 강조 표시된 CPU 작업과 병렬로 수행됩니다. 프로파일러가 일반적으로 GPU가 아닌 CPU의 성능을 측정합니다. 이렇게 하면 계측 프로파일러의 측정값에 CPU 시간이 포함되지만 GPU 시간이 포함되지 않을 수 있으므로 프로파일링이 어려워집니다.
GPU의 목적은 CPU에서 그래픽 작업을 위해 특별히 설계된 프로세서로 처리를 오프로드하는 것입니다. 최신 비디오 카드 GPU는 파이프라인의 변환 및 조명 작업의 대부분을 CPU에서 GPU로 대체합니다. 이렇게 하면 CPU 워크로드가 크게 줄어들고 다른 처리에 사용할 수 있는 CPU 주기가 늘어나게 됩니다. 최고 성능을 위해 그래픽 애플리케이션을 튜닝하려면 CPU와 GPU의 성능을 측정하고 두 가지 유형의 프로세서 간에 작업의 균형을 맞춰야 합니다.
이 문서에서는 GPU의 성능을 측정하거나 CPU와 GPU 간의 작업 분산과 관련된 항목을 다루지 않습니다. GPU(또는 특정 비디오 카드)의 성능을 더 잘 이해하려면 공급업체의 웹 사이트를 방문하여 GPU 성능에 대한 자세한 내용을 확인하세요. 대신, 이 문서에서는 GPU 작업을 무시할 수 있는 양으로 줄여 런타임 및 드라이버에서 수행하는 작업에 중점을 둡니다. 이는 부분적으로 성능 문제가 발생하는 애플리케이션이 일반적으로 CPU로 제한되는 환경을 기반으로 합니다.
런타임 및 드라이버 최적화는 API 측정을 마스킹할 수 있습니다.
런타임에는 개별 호출의 측정을 압도할 수 있는 성능 최적화가 기본 제공됩니다. 다음은 이 문제를 보여 주는 예제 시나리오입니다. 다음 렌더링 시퀀스를 고려합니다.
BeginScene();
...
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
...
EndScene();
Present();
예제 1: 단순 렌더링 시퀀스
렌더링 시퀀스에서 두 호출에 대한 결과를 살펴보면 계측 프로파일러가 다음과 유사한 결과를 반환할 수 있습니다.
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 950,500
프로파일러가 각 호출과 연결된 작업을 처리하는 데 필요한 CPU 주기 수를 반환합니다(GPU가 아직 이러한 명령에서 작업을 시작하지 않았기 때문에 GPU는 이러한 숫자에 포함되지 않음). IDirect3DDevice9::D rawPrimitive는 처리하는 데 거의 백만 개의 주기가 필요했기 때문에 매우 효율적이지 않다고 결론을 내릴 수 있습니다. 그러나 이 결론이 잘못된 이유와 예산에 사용할 수 있는 결과를 생성하는 방법을 곧 알게 될 것입니다.
상태 변경 내용을 측정하려면 신중한 렌더링 시퀀스가 필요합니다.
IDirect3DDevice9::D rawPrimitive, DrawIndexedPrimitive 또는 Clear(예: SetTexture, SetVertexDeclaration 및 SetRenderState)를 제외한 모든 호출은 상태 변경을 생성합니다. 각 상태 변경은 렌더링을 수행하는 방법을 제어하는 파이프라인 상태를 설정합니다.
런타임 및/또는 드라이버의 최적화는 필요한 작업량을 줄여 렌더링 속도를 향상하도록 설계되었습니다. 다음은 프로필 평균을 오염시킬 수 있는 몇 가지 상태 변경 최적화입니다.
- 드라이버(또는 런타임)는 상태 변경을 로컬 상태로 저장할 수 있습니다. 드라이버는 "지연" 알고리즘(절대적으로 필요할 때까지 작업 연기)에서 작동할 수 있으므로 일부 상태 변경과 관련된 작업이 지연될 수 있습니다.
- 런타임(또는 드라이버)은 최적화하여 상태 변경을 제거할 수 있습니다. 예를 들어 조명이 이전에 사용하지 않도록 설정되었으므로 조명을 사용하지 않도록 설정하는 중복 상태 변경을 제거할 수 있습니다.
렌더링 시퀀스를 보고 어떤 상태 변경 내용이 더티 비트를 설정하고 작업을 연기할지, 아니면 최적화에 의해 단순히 제거될 것인지 결론을 내릴 수 있는 확실한 방법은 없습니다. 오늘날의 런타임 또는 드라이버에서 최적화된 상태 변경을 식별할 수 있더라도 내일의 런타임 또는 드라이버가 업데이트될 가능성이 높습니다. 또한 이전 상태가 무엇인지 쉽게 알 수 없으므로 중복 상태 변경을 식별하기가 어렵습니다. 상태 변경 비용을 확인하는 유일한 방법은 상태 변경 내용을 포함하는 렌더링 시퀀스를 측정하는 것입니다.
볼 수 있듯이 여러 프로세서가 있고, 명령이 둘 이상의 구성 요소에서 처리되고, 구성 요소에 기본 제공된 최적화로 인해 프로파일링이 예측하기 어려워집니다. 다음 섹션에서는 이러한 각 프로파일링 문제를 해결합니다. 샘플 Direct3D 렌더링 시퀀스가 함께 제공되는 측정 기법과 함께 표시됩니다. 이 지식을 바탕으로 개별 호출에 대해 정확하고 반복 가능한 측정값을 생성할 수 있습니다.
Direct3D 렌더링 시퀀스를 정확하게 프로파일링하는 방법
프로파일링 과제 중 일부가 강조 표시되었으므로 이 섹션에서는 예산 책정에 사용할 수 있는 프로필 측정값을 생성하는 데 도움이 되는 기술을 보여 줍니다. CPU에서 제어하는 구성 요소 간의 관계와 런타임과 드라이버에서 구현하는 성능 최적화를 방지하는 방법을 이해하면 정확하고 반복 가능한 프로파일링 측정이 가능합니다.
시작하려면 단일 API 호출의 실행 시간을 정확하게 측정할 수 있어야 합니다.
QueryPerformanceCounter와 같은 정확한 측정 도구 선택
Microsoft Windows 운영 체제에는 고해상도 경과 시간을 측정하는 데 사용할 수 있는 고해상도 타이머가 포함되어 있습니다. 이러한 타이머 중 하나의 현재 값은 QueryPerformanceCounter를 사용하여 반환할 수 있습니다. QueryPerformanceCounter를 호출하여 시작 및 중지 값을 반환한 후 QueryPerformanceCounter를 사용하여 두 값 간의 차이를 실제 경과 시간(초)으로 변환할 수 있습니다.
QueryPerformanceCounter를 사용할 경우의 장점은 Windows에서 사용할 수 있고 사용하기 쉽다는 것입니다. 단순히 QueryPerformanceCounter 호출로 호출을 둘러싸고 시작 및 중지 값을 저장합니다. 따라서 이 문서에서는 계측 프로파일러가 측정하는 방식과 유사하게 QueryPerformanceCounter를 사용하여 실행 시간을 프로파일링하는 방법을 보여 줍니다. 다음은 소스 코드에 QueryPerformanceCounter를 포함하는 방법을 보여 주는 예제입니다.
BeginScene();
...
// Start profiling
LARGE_INTEGER start, stop, freq;
QueryPerformanceCounter(&start);
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
QueryPerformanceCounter(&stop);
stop.QuadPart -= start.QuadPart;
QueryPerformanceFrequency(&freq);
// Stop profiling
...
EndScene();
Present();
예제 2: QPC를 사용하는 사용자 지정 프로파일링 구현
시작 및 중지는 고성능 타이머에서 반환된 시작 및 중지 값을 보유하는 두 개의 큰 정수입니다. QueryPerformanceCounter(&start)는 DrawPrimitive 직후 SetTexture 및 QueryPerformanceCounter(>)가 호출되기 직전에 호출됩니다. 중지 값을 가져오면 고해상도 타이머의 빈도인 freq를 반환하기 위해 QueryPerformanceFrequency가 호출됩니다. 이 가상 예제에서는 시작, 중지 및 freq에 대해 다음 결과를 얻을 수 있다고 가정합니다.
| 지역 변수 | 틱 수 |
|---|---|
| start | 1792998845094 |
| stop | 1792998845102 |
| 주파수 | 3579545 |
이러한 값을 다음과 같이 API 호출을 실행하는 데 걸리는 주기 수로 변환할 수 있습니다.
# ticks = (stop - start) = 1792998845102 - 1792998845094 = 8 ticks
# cycles = CPU speed * number of ticks / QPF
# 4568 = 2 GHz * 8 / 3,579,545
즉, 이 2GHz 컴퓨터에서 SetTexture 및 DrawPrimitive를 처리하는 데 약 4568클록 주기가 걸립니다. 이러한 값을 다음과 같은 모든 호출을 실행하는 데 걸린 실제 시간으로 변환할 수 있습니다.
(stop - start)/ freq = elapsed time
8 ticks / 3,579,545 = 2.2E-6 seconds or between 2 and 3 microseconds.
QueryPerformanceCounter를 사용하려면 렌더링 시퀀스에 시작 및 중지 측정값을 추가하고 QueryPerformanceFrequency를 사용하여 차이(틱 수)를 CPU 주기 수 또는 실제 시간으로 변환해야 합니다. 측정 기술을 식별하는 것은 사용자 지정 프로파일링 구현을 개발하기 위한 좋은 시작입니다. 그러나 점프하고 측정을 시작하기 전에 비디오 카드 처리하는 방법을 알아야합니다.
CPU 측정에 집중
앞에서 설명한 대로 CPU와 GPU는 병렬로 작동하여 API 호출에 의해 생성된 작업을 처리합니다. 실제 애플리케이션에서는 애플리케이션이 CPU 제한 또는 GPU 제한인지 확인하기 위해 두 가지 유형의 프로세서를 프로파일링해야 합니다. GPU 성능은 공급업체별이므로 이 문서에서 사용할 수 있는 다양한 비디오 카드 다루는 결과를 생성하는 것은 매우 어려울 것입니다.
대신, 이 문서에서는 런타임 및 드라이버 작업을 측정하기 위한 사용자 지정 기술을 사용하여 CPU에서 수행하는 작업을 프로파일링하는 데만 초점을 맞춥니다. CPU 결과가 더 잘 표시되도록 GPU 작업이 미미한 양으로 줄어듭니다. 이 방법의 한 가지 이점은 이 기술이 부록을 생성하여 측정값과 상관 관계를 지정할 수 있다는 것입니다. 비디오 카드 필요한 작업을 사소한 수준으로 줄이려면 렌더링 작업을 가능한 최소 크기로 줄이면 됩니다. 이 작업은 단일 삼각형을 렌더링하기 위해 그리기 호출을 제한하여 수행할 수 있으며 각 삼각형에 픽셀이 하나만 포함되도록 추가로 제한될 수 있습니다.
이 문서에서 CPU 작업 측정에 사용되는 측정 단위는 실제 시간이 아닌 CPU 클록 주기의 수입니다. CPU 클록 주기는 CPU 속도가 다른 컴퓨터에서 실제 경과된 시간보다 더 이식 가능(CPU 제한 애플리케이션의 경우)다는 장점이 있습니다. 원하는 경우 이를 실제 시간으로 쉽게 변환할 수 있습니다.
이 문서에서는 CPU와 GPU 간의 작업 부하 분산과 관련된 항목을 다루지 않습니다. 이 문서의 목표는 애플리케이션의 전반적인 성능을 측정하는 것이 아니라 런타임 및 드라이버가 API 호출을 처리하는 데 걸리는 시간을 정확하게 측정하는 방법을 보여 주는 것입니다. 이러한 정확한 측정을 통해 특정 성능 시나리오를 이해하기 위해 CPU 예산을 책정하는 작업을 수행할 수 있습니다.
런타임 및 드라이버 최적화 제어
측정 기법이 식별되고 GPU 작업을 줄이기 위한 전략을 사용하여 다음 단계는 프로파일링할 때 방해가 되는 런타임 및 드라이버 최적화를 이해하는 것입니다.
CPU 작업은 애플리케이션 작업, 런타임 작업 및 드라이버 작업의 세 가지 버킷으로 나눌 수 있습니다. 프로그래머가 제어하고 있기 때문에 애플리케이션 작업을 무시합니다. 애플리케이션의 관점에서 런타임 및 드라이버는 블랙 박스와 같으며 애플리케이션은 구현되는 항목을 제어할 수 없습니다. 핵심은 런타임 및 드라이버에서 구현될 수 있는 최적화 기술을 이해하는 것입니다. 이러한 최적화를 이해하지 못하면 프로필 측정값에 따라 CPU가 수행하는 작업의 양에 대한 잘못된 결론으로 쉽게 이동할 수 있습니다. 특히 명령 버퍼라는 항목과 프로파일링을 난독 처리하기 위해 수행할 수 있는 작업과 관련된 두 가지 항목이 있습니다. 다음 항목은 다음과 같습니다.
- 명령 버퍼를 사용한 런타임 최적화 명령 버퍼는 모드 전환의 영향을 줄이는 런타임 최적화입니다. 모드 전환의 타이밍을 제어하려면 명령 버퍼 제어를 참조하세요.
- 명령 버퍼의 타이밍 효과를 부정합니다. 모드 전환의 경과 시간은 프로파일링 측정에 큰 영향을 미칠 수 있습니다. 이에 대한 전략은 모드 전환에 비해 렌더링 시퀀스를 크게 만드는 것입니다.
명령 버퍼 제어
애플리케이션이 API를 호출할 때 런타임은 API 호출을 디바이스 독립적 형식(명령을 호출)으로 변환하고 명령 버퍼에 저장합니다. 명령 버퍼는 다음 다이어그램에 추가됩니다.
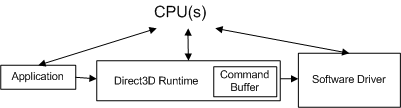
애플리케이션이 다른 API 호출을 수행할 때마다 런타임은 이 시퀀스를 반복하고 명령 버퍼에 다른 명령을 추가합니다. 어떤 시점에서 런타임은 버퍼를 비웁니다(드라이버에 명령 보내기). Windows XP에서 명령 버퍼를 비우면 다음 다이어그램과 같이 운영 체제가 런타임(사용자 모드에서 실행)에서 드라이버(커널 모드로 실행)로 전환됨에 따라 모드 전환이 발생합니다.
- 사용자 모드 - 애플리케이션 코드를 실행하는 권한이 없는 프로세서 모드입니다. 사용자 모드 애플리케이션은 시스템 서비스를 통해서만 시스템 데이터에 액세스할 수 없습니다.
- 커널 모드 - Windows 기반 임원 코드가 실행되는 권한 있는 프로세서 모드입니다. 커널 모드에서 실행되는 드라이버 또는 스레드는 모든 시스템 메모리에 액세스하고 하드웨어에 직접 액세스하며 하드웨어에서 I/O를 수행하는 CPU 지침을 제공합니다.
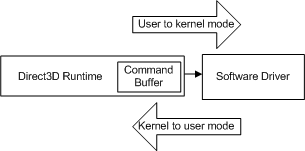
CPU가 사용자에서 커널 모드로 전환되고(그 반대의 경우도 마찬가지) 개별 API 호출에 비해 필요한 주기 수가 클 때마다 전환이 발생합니다. 런타임이 호출될 때 드라이버에 각 API 호출을 보내면 모든 API 호출에 모드 전환 비용이 발생합니다.
대신 명령 버퍼는 모드 전환의 효과적인 비용을 줄이기 위해 설계된 런타임 최적화입니다. 명령 버퍼는 단일 모드 전환을 준비하기 위해 많은 드라이버 명령을 큐에 대기합니다. 런타임이 명령 버퍼에 명령을 추가하면 컨트롤이 애플리케이션에 반환됩니다. 프로파일러가 드라이버 명령이 아직 드라이버로 전송되지 않았을 수도 있다는 것을 알 수 있는 방법이 없습니다. 결과적으로, 기성품 계측 프로파일러가 반환한 숫자는 런타임 작업을 측정하지만 연결된 드라이버 작업은 측정하지 않으므로 오해의 소지가 있습니다.
모드 전환이 없는 프로필 결과
예제 2의 렌더링 시퀀스를 사용하여 모드 전환의 크기를 보여 주는 몇 가지 일반적인 타이밍 측정값은 다음과 같습니다. SetTexture 및 DrawPrimitive 호출이 모드 전환을 유발하지 않는다고 가정하면, 기성 계측 프로파일러가 다음과 유사한 결과를 반환할 수 있습니다.
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
이러한 각 숫자는 런타임에서 명령 버퍼에 이러한 호출을 추가하는 데 걸리는 시간입니다. 모드 전환이 없으므로 드라이버는 아직 작업을 수행하지 않았습니다. 프로파일러 결과는 정확하지만 렌더링 시퀀스로 인해 결국 CPU가 수행되는 모든 작업을 측정하지는 않습니다.
모드 전환을 사용하여 프로필 결과
이제 모드 전환이 발생할 때 동일한 예제에 대해 어떻게 되는지 살펴봅니다. 이번에는 SetTexture 및 DrawPrimitive가 모드 전환을 일으킨다고 가정합니다. 다시 한번, 기성품 계측 프로파일러가 다음과 유사한 결과를 반환할 수 있습니다.
Number of cycles for SetTexture : 98
Number of cycles for DrawPrimitive : 946,900
SetTexture에 대해 측정된 시간은 거의 동일하며, DrawPrimitive에서 소요되는 시간의 급격한 증가는 모드 전환 때문입니다. 무슨 일이 일어나고 있는지는 다음과 같습니다.
- 렌더링 시퀀스가 시작되기 전에 명령 버퍼에 하나의 명령에 대한 공간이 있다고 가정합니다.
- SetTexture 는 디바이스 독립적 형식으로 변환되고 명령 버퍼에 추가됩니다. 이 시나리오에서 이 호출은 명령 버퍼를 채웁니다.
- 런타임은 명령 버퍼에 DrawPrimitive를 추가하려고 하지만 가득 찼기 때문에 추가할 수 없습니다. 대신 런타임은 명령 버퍼를 비웁니다. 이로 인해 커널 모드 전환이 발생합니다. 전환에 약 5,000회 주기가 소요된다고 가정합니다. 이 시간은 DrawPrimitive에서 소요된 시간에 기여합니다.
- 그런 다음 드라이버는 명령 버퍼에서 비운 모든 명령과 연결된 작업을 처리합니다. 명령 버퍼를 거의 채운 명령을 처리하는 드라이버 시간이 약 935,000주기라고 가정합니다. SetTexture와 연결된 드라이버 작업이 약 2750주기라고 가정합니다. 이 시간은 DrawPrimitive에서 소요된 시간에 기여합니다.
- 드라이버가 작업을 완료하면 사용자 모드 전환이 런타임에 컨트롤을 반환합니다. 이제 명령 버퍼가 비어 있습니다. 전환에 약 5,000회 주기가 소요된다고 가정합니다.
- 렌더링 시퀀스는 DrawPrimitive를 변환하고 명령 버퍼에 추가하여 완료됩니다. 약 900 주기가 소요된다고 가정합니다. 이 시간은 DrawPrimitive에서 소요된 시간에 기여합니다.
결과를 요약하면 다음이 표시됩니다.
DrawPrimitive = kernel-transition + driver work + user-transition + runtime work
DrawPrimitive = 5000 + 935,000 + 2750 + 5000 + 900
DrawPrimitive = 947,950
모드 전환(900주기)이 없는 DrawPrimitive의 측정값과 마찬가지로, 모드 전환(947,950주기)을 사용하는 DrawPrimitive의 측정값은 정확하지만 CPU 작업 예산 측면에서는 쓸모가 없습니다. 결과에는 올바른 런타임 작업, SetTexture에 대한 드라이버 작업, SetTexture 이전의 모든 명령에 대한 드라이버 작업 및 두 가지 모드 전환이 포함됩니다. 그러나 측정값에 DrawPrimitive 드라이버 작업이 없습니다.
모든 호출에 대한 응답으로 모드 전환이 발생할 수 있습니다. 명령 버퍼의 이전 내용에 따라 달라집니다. 각 호출과 연결된 CPU 작업량(런타임 및 드라이버)을 이해하려면 모드 전환을 제어해야 합니다. 이렇게 하려면 명령 버퍼 및 모드 전환 타이밍을 제어하는 메커니즘이 필요합니다.
쿼리 메커니즘
Microsoft Direct3D 9의 쿼리 메커니즘은 런타임이 GPU에서 진행률을 쿼리하고 GPU에서 특정 데이터를 반환할 수 있도록 설계되었습니다. 프로파일링하는 동안 GPU 작업이 최소화되어 성능에 미미한 영향을 주는 경우 GPU에서 상태 반환하여 드라이버 작업을 측정할 수 있습니다. 결국 GPU에서 드라이버 명령을 보았을 때 드라이버 작업이 완료됩니다. 또한 쿼리 메커니즘은 프로파일링에 중요한 두 가지 명령 버퍼 특성, 즉 명령 버퍼가 비워질 때와 버퍼의 작업 양을 제어하도록 동축될 수 있습니다.
쿼리 메커니즘을 사용하는 동일한 렌더링 시퀀스는 다음과 같습니다.
// 1. Create an event query from the current device
IDirect3DQuery9* pEvent;
m_pD3DDevice->CreateQuery(D3DQUERYTYPE_EVENT, &pEvent);
// 2. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 3. Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 4. Start profiling
LARGE_INTEGER start, stop;
QueryPerformanceCounter(&start);
// 5. Invoke the API calls to be profiled.
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
// 6. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 7. Force the driver to execute the commands from the command buffer.
// Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 8. End profiling
QueryPerformanceCounter(&stop);
예제 3: 쿼리를 사용하여 명령 버퍼 제어
다음은 이러한 각 코드 줄에 대한 자세한 설명입니다.
- D3DQUERYTYPE_EVENT 사용하여 쿼리 개체를 만들어 이벤트 쿼리를 만듭니다.
- issue(D3DISSUE_END)를 호출하여 명령 버퍼에 쿼리 이벤트 마커를 추가합니다. 이 표식은 GPU가 마커 앞에 오는 명령 실행을 완료하는 시기를 추적하도록 드라이버에 지시합니다.
- D3DGETDATA_FLUSH GetData를 호출하면 명령 버퍼가 비워지므로 첫 번째 호출은 명령 버퍼를 비웁니다. 각 후속 호출은 GPU를 검사 모든 명령 버퍼 작업 처리를 완료하는 시기를 확인합니다. 이 루프는 GPU가 유휴 상태가 될 때까지 S_OK 반환하지 않습니다.
- 시작 시간을 샘플링합니다.
- 프로파일되는 API 호출을 호출합니다.
- 명령 버퍼에 두 번째 쿼리 이벤트 마커를 추가합니다. 이 표식은 호출 완료를 추적하는 데 사용됩니다.
- D3DGETDATA_FLUSH GetData를 호출하면 명령 버퍼가 비워지므로 첫 번째 호출은 명령 버퍼를 비웁니다. GPU가 모든 명령 버퍼 작업 처리를 마치면 GetData 는 S_OK 반환하고 GPU가 유휴 상태이므로 루프가 종료됩니다.
- 중지 시간을 샘플링합니다.
QueryPerformanceCounter 및 QueryPerformanceFrequency로 측정된 결과는 다음과 같습니다.
| 지역 변수 | 틱 수 |
|---|---|
| start | 1792998845060 |
| stop | 1792998845090 |
| 주파수 | 3579545 |
틱을 다시 한 번 주기로 변환(2GHz 컴퓨터에서):
# ticks = (stop - start) = 1792998845090 - 1792998845060 = 30 ticks
# cycles = CPU speed * number of ticks / QPF
# 16,450 = 2 GHz * 30 / 3,579,545
다음은 호출당 주기 수의 분석입니다.
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Number of cycles for Issue : 200
Number of cycles for GetData : 16,450
쿼리 메커니즘을 통해 측정되는 런타임 및 드라이버 작업을 제어할 수 있습니다. 이러한 각 숫자를 이해하기 위해 예상 타이밍과 함께 각 API 호출에 대한 응답으로 발생하는 일은 다음과 같습니다.
첫 번째 호출은 D3DGETDATA_FLUSH GetData를 호출하여 명령 버퍼를 비웁니다. GPU가 모든 명령 버퍼 작업 처리를 마치면 GetData 는 S_OK 반환하고 GPU가 유휴 상태이므로 루프가 종료됩니다.
렌더링 시퀀스는 SetTexture를 디바이스 독립적 형식으로 변환하고 명령 버퍼에 추가하여 시작합니다. 약 100회 주기가 소요된다고 가정합니다.
DrawPrimitive 가 변환되어 명령 버퍼에 추가됩니다. 약 900 주기가 소요된다고 가정합니다.
문제는 명령 버퍼에 쿼리 표식을 추가합니다. 이 작업은 약 200주기를 소요된다고 가정합니다.
GetData 를 사용하면 커널 모드 전환을 강제하는 명령 버퍼가 비워지게 됩니다. 약 5,000회 주기가 소요된다고 가정합니다.
그런 다음 드라이버는 네 번의 호출과 관련된 작업을 처리합니다. SetTexture를 처리하는 드라이버 시간이 약 2964주기, DrawPrimitive는 약 3600주기, 문제는 약 200주기라고 가정합니다. 따라서 네 명령 모두에 대한 총 드라이버 시간은 약 6450주기입니다.
참고 항목
또한 드라이버는 GPU의 상태 무엇인지 확인하는 데 약간의 시간이 걸립니다. GPU 작업은 간단하기 때문에 GPU는 이미 수행되어야 합니다. GetData 는 GPU가 완료될 가능성에 따라 S_OK 반환합니다.
드라이버가 작업을 완료하면 사용자 모드 전환이 런타임에 컨트롤을 반환합니다. 이제 명령 버퍼가 비어 있습니다. 약 5,000회 주기가 소요된다고 가정합니다.
GetData의 숫자는 다음과 같습니다.
GetData = kernel-transition + driver work + user-transition
GetData = 5000 + 6450 + 5000
GetData = 16,450
driver work = SetTexture + DrawPrimitive + Issue =
driver work = 2964 + 3600 + 200 = 6450 cycles
QueryPerformanceCounter와 함께 사용되는 쿼리 메커니즘은 모든 CPU 작업을 측정합니다. 이 작업은 쿼리 표식과 쿼리 상태 비교의 조합으로 수행됩니다. 명령 버퍼에 추가된 쿼리 마커 시작 및 중지는 버퍼에 있는 작업의 양을 제어하는 데 사용됩니다. 오른쪽 반환 코드가 반환될 때까지 기다리면 클린 렌더링 시퀀스가 시작되기 직전에 시작 측정이 수행되고 드라이버가 명령 버퍼 내용과 관련된 작업을 완료한 직후 중지 측정이 수행됩니다. 이렇게 하면 드라이버뿐만 아니라 런타임에서 수행하는 CPU 작업이 효과적으로 캡처됩니다.
이제 명령 버퍼 및 프로파일링에 미칠 수 있는 영향에 대해 알고 있으므로 런타임이 명령 버퍼를 비울 수 있는 몇 가지 다른 조건이 있음을 알아야 합니다. 렌더링 시퀀스에서 주의해야 합니다. 이러한 조건 중 일부는 API 호출에 대한 응답이며, 다른 조건은 런타임의 리소스 변경에 대응합니다. 다음 조건 중 어느 것이든 모드 전환이 발생합니다.
- 특정 플래그가 있는 특정 조건에서 꼭짓점 버퍼, 인덱스 버퍼 또는 텍스처에서 잠금 메서드(Lock) 중 하나가 호출되는 경우
- 디바이스 또는 꼭짓점 버퍼, 인덱스 버퍼 또는 텍스처가 만들어지는 경우
- 디바이스 또는 꼭짓점 버퍼, 인덱스 버퍼 또는 텍스처가 마지막 릴리스에 의해 제거되는 경우
- ValidateDevice가 호출되는 경우
- Present가 호출되는 경우
- 명령 버퍼가 채워지면
- GetData가 D3DGETDATA_FLUSH 사용하여 호출되는 경우
렌더링 시퀀스에서 이러한 조건을 주의해야 합니다. 모드 전환이 추가될 때마다 10,000 주기의 드라이버 작업이 프로파일링 측정값에 추가됩니다. 또한 명령 버퍼의 크기는 정적으로 조정되지 않습니다. 런타임은 애플리케이션에서 생성되는 작업의 양에 따라 버퍼의 크기를 변경할 수 있습니다. 이는 렌더링 시퀀스에 종속된 또 다른 최적화입니다.
따라서 프로파일링 중에 모드 전환을 제어해야 합니다. 쿼리 메커니즘은 명령 버퍼를 비우는 강력한 방법을 제공하므로 버퍼에 포함된 작업량뿐만 아니라 모드 전환의 타이밍을 제어할 수 있습니다. 그러나 이 기술조차도 측정된 결과와 관련하여 중요하지 않게 하기 위해 모드 전환 시간을 줄임으로써 개선할 수 있습니다.
모드 전환과 비교하여 렌더링 시퀀스를 크게 만듭니다.
이전 예제에서 커널 모드 스위치와 사용자 모드 스위치는 런타임 및 드라이버 작업과는 아무런 관련이 없는 약 10,000회 주기를 사용합니다. 모드 전환은 운영 체제에 기본 제공되므로 0으로 줄일 수 없습니다. 모드 전환을 중요하지 않게 하려면 드라이버 및 런타임 작업이 모드 스위치보다 큰 순서가 되도록 렌더링 시퀀스를 조정해야 합니다. 전환을 제거하기 위해 빼기를 시도할 수 있지만 훨씬 더 큰 렌더링 시퀀스 비용을 상각하는 것이 더 안정적입니다.
중요하지 않게 될 때까지 모드 전환을 줄이는 전략은 렌더링 시퀀스에 루프를 추가하는 것입니다. 예를 들어 렌더링 시퀀스를 1500번 반복하는 루프가 추가된 경우 프로파일링 결과를 살펴보겠습니다.
// Initialize the array with two textures, same size, same format
IDirect3DTexture* texArray[2];
CreateQuery(D3DQUERYTYPE_EVENT, pEvent);
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
LARGE_INTEGER start, stop;
// Now start counting because the video card is ready
QueryPerformanceCounter(&start);
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
SetTexture(taxArray[i%2]);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
QueryPerformanceCounter(&stop);
예제 4: 렌더링 시퀀스에 루프 추가
QueryPerformanceCounter 및 QueryPerformanceFrequency로 측정된 결과는 다음과 같습니다.
| 지역 변수 | Tics 수 |
|---|---|
| start | 1792998845000 |
| stop | 1792998847084 |
| 주파수 | 3579545 |
QueryPerformanceCounter를 사용하면 현재 2,840개의 틱을 측정합니다. 틱을 주기로 변환하는 것은 이미 표시된 것과 동일합니다.
# ticks = (stop - start) = 1792998847084 - 1792998845000 = 2840 ticks
# cycles = machine speed * number of ticks / QPF
# 6,900,000 = 2 GHz * 2840 / 3,579,545
즉, 렌더링 루프에서 1500개 호출을 처리하는 데 이 2GHz 컴퓨터에서 약 690만 주기가 걸립니다. 690만 주기 중 모드 전환의 시간은 약 10k이므로 이제 프로필 결과는 SetTexture 및 DrawPrimitive와 관련된 작업을 거의 전적으로 측정합니다.
코드 샘플에는 두 개의 텍스처 배열이 필요합니다. SetTexture가 호출될 때마다 동일한 텍스처 포인터를 설정하는 경우 SetTexture를 제거하는 런타임 최적화를 방지하려면 두 텍스처 배열을 사용하면 됩니다. 이렇게 하면 루프를 통해 매번 텍스처 포인터가 변경되고 SetTexture와 연결된 전체 작업이 수행됩니다. 두 텍스처가 모두 크기 및 형식이 같으므로 텍스처가 변경될 때 다른 상태가 변경되지 않도록 해야 합니다.
이제 Direct3D를 프로파일링하는 기술이 있습니다. 고성능 카운터(QueryPerformanceCounter)를 사용하여 CPU가 작업을 처리하는 데 걸리는 틱 수를 기록합니다. 이 작업은 쿼리 메커니즘을 사용하여 API 호출과 연결된 런타임 및 드라이버 작업으로 신중하게 제어됩니다. 쿼리는 두 가지 제어 수단을 제공합니다. 먼저 렌더링 시퀀스가 시작되기 전에 명령 버퍼를 비우고, 두 번째로 GPU 작업이 완료되면 반환합니다.
지금까지 이 문서에서는 렌더링 시퀀스를 프로파일링하는 방법을 보여 했습니다. 각 렌더링 시퀀스는 단일 DrawPrimitive 호출 및 SetTexture 호출을 포함하는 매우 간단합니다. 이 작업은 명령 버퍼와 쿼리 메커니즘을 사용하여 제어하는 데 집중하기 위해 수행되었습니다. 다음은 임의 렌더링 시퀀스를 프로파일링하는 방법에 대한 간략한 요약입니다.
- QueryPerformanceCounter와 같은 고성능 카운터를 사용하여 각 API 호출을 처리하는 데 걸리는 시간을 측정합니다. QueryPerformanceFrequency 및 CPU 클록 속도를 사용하여 이를 API 호출당 CPU 주기 수로 변환합니다.
- 각 삼각형에 1픽셀이 포함된 삼각형 목록을 렌더링하여 GPU 작업의 양을 최소화합니다.
- 쿼리 메커니즘을 사용하여 렌더링 시퀀스 전에 명령 버퍼를 비우세요. 이렇게 하면 프로파일링이 렌더링 시퀀스와 연결된 올바른 양의 런타임 및 드라이버 작업을 캡처할 수 있습니다.
- 쿼리 이벤트 마커를 사용하여 명령 버퍼에 추가된 작업의 양을 제어합니다. 이 동일한 쿼리는 GPU가 작업을 완료할 때를 검색합니다. GPU 작업은 간단하기 때문에 드라이버 작업이 완료된 시기를 측정하는 것과 거의 동일합니다.
이러한 모든 기술은 상태 변경 내용을 프로파일하는 데 사용됩니다. 명령 버퍼를 제어하는 방법을 읽고 이해했으며 DrawPrimitive에서 기준 측정을 성공적으로 완료한 경우 렌더링 시퀀스에 상태 변경 내용을 추가할 준비가 된 것입니다. 렌더링 시퀀스에 상태 변경 내용을 추가할 때 몇 가지 추가 프로파일링 문제가 있습니다. 렌더링 시퀀스에 상태 변경 내용을 추가하려면 다음 섹션으로 계속 진행해야 합니다.
Direct3D 상태 변경 프로파일링
Direct3D는 많은 렌더링 상태를 사용하여 파이프라인의 거의 모든 측면을 제어합니다. 상태 변경을 일으키는 API에는 Draw*Primitive 호출 이외의 함수 또는 메서드가 포함됩니다.
상태 변경은 렌더링하지 않고 상태 변경 비용을 볼 수 없기 때문에 까다롭습니다. 이는 드라이버와 GPU가 작업을 절대적으로 수행해야 할 때까지 지연하는 데 사용하는 지연 알고리즘의 결과입니다. 일반적으로 단일 상태 변경을 측정하려면 다음 단계를 수행해야 합니다.
- 먼저 DrawPrimitive 프로파일 을 지정합니다 .
- 렌더링 시퀀스에 하나의 상태 변경 사항을 추가하고 새 시퀀스를 프로파일링합니다.
- 두 시퀀스의 차이를 빼서 상태 변경 비용을 가져옵니다.
당연히 쿼리 메커니즘을 사용하고 모드 전환 비용을 부정하기 위해 렌더링 시퀀스를 루프에 배치하는 방법에 대해 배운 모든 것이 여전히 적용됩니다.
단순 상태 변경 프로파일링
DrawPrimitive가 포함된 렌더링 시퀀스부터 SetTexture 추가 비용을 측정하기 위한 코드 시퀀스는 다음과 같습니다.
// Get the start counter value as shown in Example 4
// Initialize a texture array as shown in Example 4
IDirect3DTexture* texArray[2];
// Render sequence loop
for(int i = 0; i < 1500; i++)
{
SetTexture(0, texArray[i%2];
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
// Get the stop counter value as shown in Example 4
예제 5: 하나의 상태 변경 API 호출 측정
루프에는 SetTexture 및 DrawPrimitive라는 두 개의 호출이 포함됩니다. 렌더링 시퀀스는 1500회 반복되며 다음과 유사한 결과를 생성합니다.
| 지역 변수 | Tics 수 |
|---|---|
| start | 1792998860000 |
| stop | 1792998870260 |
| 주파수 | 3579545 |
틱을 주기로 변환하면 다시 한 번 다음이 생성됩니다.
# ticks = (stop - start) = 1792998870260 - 1792998860000 = 10,260 ticks
# cycles = machine speed * number of ticks / QPF
5,775,000 = 2 GHz * 10,260 / 3,579,545
루프의 반복 횟수로 나눈 값은 다음과 같습니다.
5,775,000 cycles / 1500 iterations = 3850 cycles for one iteration
루프의 각 반복에는 상태 변경 및 그리기 호출이 포함됩니다. DrawPrimitive 렌더링 시퀀스의 결과를 뺍니다.
3850 - 1100 = 2750 cycles for SetTexture
이 렌더링 시퀀스에 SetTexture를 추가하는 평균 주기 수입니다. 이 동일한 기술을 다른 상태 변경에 적용할 수 있습니다.
SetTexture를 간단한 상태 변경이라고 하는 이유는 무엇인가요? 설정되는 상태는 파이프라인이 상태가 변경될 때마다 동일한 양의 작업을 수행하도록 제한되기 때문입니다. 두 텍스처를 동일한 크기와 형식으로 제한하면 각 SetTexture 호출에 대해 동일한 양의 작업이 보장됩니다.
토글해야 하는 상태 변경 프로파일링
렌더링 루프의 모든 반복에 대해 그래픽 파이프라인에서 수행하는 작업의 양이 변경되는 다른 상태 변경이 있습니다. 예를 들어 z-testing을 사용하는 경우 각 픽셀 색은 새 픽셀의 z 값이 기존 픽셀의 z 값에 대해 테스트된 후에만 렌더링 대상을 업데이트합니다. z-testing을 사용하지 않도록 설정하면 이 픽셀별 테스트가 수행되지 않고 출력이 훨씬 빠르게 작성됩니다. z-test 상태를 사용하거나 사용하지 않도록 설정하면 렌더링 중에 수행된 작업량(CPU 및 GPU)이 크게 변경됩니다.
SetRenderState 를 사용하거나 사용하지 않도록 설정하려면 특정 렌더링 상태와 상태 값이 필요합니다. 특정 상태 값은 런타임에 평가되어 필요한 작업의 양을 결정합니다. 렌더링 루프에서 이 상태 변경을 측정하고 파이프라인 상태가 전환되도록 전제 조건을 적용하기는 어렵습니다. 유일한 해결 방법은 렌더링 시퀀스 중에 상태 변경을 토글하는 것입니다.
예를 들어 프로파일링 기술은 다음과 같이 두 번 반복해야 합니다.
- DrawPrimitive 렌더링 시퀀스를 프로파일링하여 시작합니다. 이것을 기준선이라고 합니다.
- 상태 변경을 토글하는 두 번째 렌더링 시퀀스를 프로파일링합니다. 렌더링 시퀀스 루프에는 다음이 포함됩니다.
- 상태를 "false" 조건으로 설정하기 위한 상태 변경입니다.
- 원래 시퀀스처럼 DrawPrimitive 입니다.
- 상태를 "true" 조건으로 설정하기 위한 상태 변경입니다.
- 두 번째 상태 변경을 강제로 실현하는 두 번째 DrawPrimitive 입니다.
- 두 렌더링 시퀀스의 차이점을 찾습니다. 이 작업은 다음을 통해 수행됩니다.
- 새 시퀀스에 두 개의 DrawPrimitive 호출이 있으므로 기준 DrawPrimitive 시퀀스를 2로 곱합니다.
- 원래 시퀀스에서 새 시퀀스의 결과를 뺍니다.
- 결과를 2로 나누어 "false" 및 "true" 상태 변경의 평균 비용을 가져옵니다.
렌더링 시퀀스에 사용되는 루핑 기술을 사용하면 렌더링 시퀀스의 각 반복에 대해 상태를 "true"에서 "false" 조건으로 전환하여 파이프라인 상태를 변경하는 비용을 측정해야 합니다. 여기서 "true"와 "false"의 의미는 리터럴이 아니며, 이는 단순히 국가가 반대 조건으로 설정되어야 한다는 것을 의미합니다. 이렇게 하면 프로파일링 중에 두 상태 변경 내용이 모두 측정됩니다. 물론 쿼리 메커니즘을 사용하고 모드 전환 비용을 부정하기 위해 렌더링 시퀀스를 루프에 배치하는 방법에 대해 배운 모든 것이 여전히 적용됩니다.
예를 들어 z-testing 켜기 또는 끄기 토글 비용을 측정하기 위한 코드 시퀀스는 다음과 같습니다.
// Get the start counter value as shown in Example 4
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the "false" condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Set the pipeline state to the "true" condition
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
// Get the stop counter value as shown in Example 4
예제 5: 토글 상태 변경 측정
루프는 두 개의 SetRenderState 호출을 실행하여 상태를 전환합니다. 첫 번째 SetRenderState 호출은 z-testing을 사용하지 않도록 설정하고 두 번째 SetRenderState 는 z-testing을 사용하도록 설정합니다. 각 SetRenderState 뒤에 DrawPrimitive가 추가되므로 드라이버에서 더티 비트만 설정하는 대신 드라이버에서 상태 변경과 관련된 작업을 처리합니다.
이러한 숫자는 이 렌더링 시퀀스에 적합합니다.
| 지역 변수 | 틱 수 |
|---|---|
| start | 1792998845000 |
| stop | 1792998861740 |
| 주파수 | 3579545 |
틱을 주기로 변환하면 다시 한 번 다음이 생성됩니다.
# ticks = (stop - start) = 1792998861740 - 1792998845000 = 15,120 ticks
# cycles = machine speed * number of ticks / QPF
9,300,000 = 2 GHz * 16,740 / 3,579,545
루프의 반복 횟수로 나눈 값은 다음과 같습니다.
9,300,000 cycles / 1500 iterations = 6200 cycles for one iteration
루프의 각 반복에는 두 가지 상태 변경 내용과 두 개의 그리기 호출이 포함됩니다. 그리기 호출을 뺍니다(1100주기 가정).
6200 - 1100 - 1100 = 4000 cycles for both state changes
이는 두 상태 변경의 평균 주기 수이므로 각 상태 변경의 평균 시간은 다음과 같습니다.
4000 / 2 = 2000 cycles for each state change
따라서 z-testing을 사용하거나 사용하지 않도록 설정하는 평균 주기 수는 2000주기입니다. QueryPerformanceCounter는 z 사용 시간의 절반을 측정하고, z-disable는 시간의 절반을 측정하고 있다는 다는 점을 주목할 가치가 있습니다. 이 기술은 실제로 두 상태 변경의 평균을 측정합니다. 즉, 상태를 토글하는 시간을 측정하고 있습니다. 이 기술을 사용하면 두 시간의 평균을 측정했으므로 사용 및 사용 안 함 시간이 동일한지 알 수 없습니다. 그럼에도 불구하고 이 상태 변경을 유발하는 애플리케이션으로 토글 상태를 예산을 책정할 때는 이 상태를 전환해야만 사용할 수 있습니다.
그래서 지금 당신은 이러한 기술을 적용하고 바로, 당신이 원하는 모든 상태 변경을 프로파일 할 수 있습니다? 그렇지 않습니다. 수행해야 하는 작업의 양을 줄이기 위해 설계된 최적화에 주의를 기울여야 합니다. 렌더링 시퀀스를 디자인할 때 알아야 할 두 가지 유형의 최적화가 있습니다.
상태 변경 최적화에 주의
이전 섹션에서는 두 종류의 상태 변경을 프로파일링하는 방법을 보여 줍니다. 즉, 각 반복에 대해 동일한 양의 작업을 생성하도록 제한되는 간단한 상태 변경 및 완료된 작업의 양을 크게 변경하는 토글 상태 변경입니다. 이전 렌더링 시퀀스를 사용하고 다른 상태 변경을 추가하면 어떻게 되나요? 예를 들어 이 예제에서는 z-enable> 렌더링 시퀀스를 사용하고 z-func 비교를 추가합니다.
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZFUNC, D3DCMP_NEVER);
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZFUNC, D3DCMP_ALWAYS);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
z-func 상태는 z 버퍼에 쓸 때 비교 수준을 설정합니다(깊이 버퍼에서 픽셀의 z 값이 있는 현재 픽셀의 z 값 사이). D3DCMP_NEVER z-testing 비교를 해제하는 반면 D3DCMP_ALWAYS z 테스트가 완료 될 때마다 수행되도록 비교를 설정합니다.
DrawPrimitive를 사용하여 렌더링 시퀀스에서 이러한 상태 변경 중 하나를 프로파일링하면 다음과 유사한 결과가 생성됩니다.
| 단일 상태 변경 | 평균 주기 수 |
|---|---|
| D3DRS_ZENABLE 전용 | 2000 |
또는
| 단일 상태 변경 | 평균 주기 수 |
|---|---|
| D3DRS_ZFUNC 전용 | 600 |
그러나 동일한 렌더링 시퀀스에서 D3DRS_ZENABLE 및 D3DRS_ZFUNC 프로파일링하는 경우 다음과 같은 결과를 볼 수 있습니다.
| 두 상태 변경 | 평균 주기 수 |
|---|---|
| D3DRS_ZENABLE + D3DRS_ZFUNC | 2000 |
드라이버가 두 렌더링 상태 설정과 관련된 모든 작업을 수행하므로 결과는 2000 및 600(또는 2600) 주기의 합계가 될 것으로 예상할 수 있습니다. 대신 평균은 2000주기입니다.
이 결과는 런타임, 드라이버 또는 GPU에서 구현된 상태 변경 최적화를 반영합니다. 이 경우 드라이버는 첫 번째 SetRenderState를 보고 나중에 작업을 연기할 더티 상태를 설정할 수 있습니다. 드라이버가 두 번째 SetRenderState를 볼 때 동일한 더티 상태를 중복으로 설정할 수 있으며 동일한 작업이 다시 연기됩니다. DrawPrimitive가 호출되면 더티 상태와 연결된 작업이 마침내 처리됩니다. 드라이버는 작업을 한 번 실행합니다. 즉, 처음 두 상태 변경 내용이 드라이버에 의해 효과적으로 통합됩니다. 마찬가지로, 세 번째 및 네 번째 상태 변경은 두 번째 DrawPrimitive 가 호출될 때 드라이버에서 효과적으로 단일 상태 변경으로 통합됩니다. 결과적으로 드라이버와 GPU는 각 그리기 호출에 대해 단일 상태 변경을 처리합니다.
이는 시퀀스 종속 드라이버 최적화의 좋은 예입니다. 드라이버는 더티 상태를 설정하여 작업을 두 번 연기한 다음 더티 상태를 지우기 위해 작업을 한 번 수행했습니다. 이는 절대적으로 필요할 때까지 작업이 지연될 때 발생할 수 있는 효율성 개선의 좋은 예입니다.
내부적으로 더티 상태를 설정하고 이후까지 작업을 연기할 상태 변경을 어떻게 알 수 있나요? 렌더링 시퀀스를 테스트하거나 드라이버 작성기와 통신해야 합니다. 드라이버가 주기적으로 업데이트되고 개선되므로 최적화 목록이 정적이지 않습니다. 특정 하드웨어 집합에서 지정된 렌더링 시퀀스의 상태 변경 비용을 절대적으로 알 수 있는 방법은 하나뿐입니다. 그리고 그것은 그것을 측정하는 것입니다.
DrawPrimitive 최적화에 주의
상태 변경 최적화 외에도 런타임은 드라이버가 처리해야 하는 그리기 호출 수를 최적화하려고 시도합니다. 예를 들어 다음을 다시 그리기 호출로 다시 고려합니다.
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 3); // Draw 3 primitives, vertices 0 - 8
DrawPrimitive(D3DPT_TRIANGLELIST, 9, 4); // Draw 4 primitives, vertices 9 - 20
예제 5a: 두 개의 그리기 호출
이 시퀀스에는 런타임이 다음과 같은 단일 호출로 통합되는 두 개의 그리기 호출이 포함됩니다.
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 7); // Draw 7 primitives, vertices 0 - 20
예제 5b: 연결된 단일 그리기 호출
런타임은 이러한 특정 그리기 호출을 모두 단일 호출에 연결하므로 드라이버가 이제 하나의 그리기 호출만 처리하면 되므로 드라이버 작업이 50% 줄어듭니다.
일반적으로 런타임은 다음과 같은 경우 두 개 이상의 연속 DrawPrimitive 호출을 연결합니다.
- 기본 형식은 삼각형 목록(D3DPT_TRIANGLELIST)입니다.
- 연속 적인 각 DrawPrimitive 호출은 꼭짓점 버퍼 내에서 연속 꼭짓점을 참조해야 합니다.
마찬가지로 두 개 이상의 연속 DrawIndexedPrimitive 호출을 연결하기 위한 적절한 조건은 다음과 같습니다.
- 기본 형식은 삼각형 목록(D3DPT_TRIANGLELIST)입니다.
- 연속 적인 각 DrawIndexedPrimitive 호출은 인덱스 버퍼 내에서 연속된 인덱스를 순차적으로 참조해야 합니다.
- 연속 적인 각 DrawIndexedPrimitive 호출은 BaseVertexIndex에 대해 동일한 값을 사용해야 합니다.
프로파일링 중에 연결을 방지하려면 기본 형식이 삼각형 목록이 아니도록 렌더링 시퀀스를 수정하거나 연속 꼭짓점(또는 인덱스)을 사용하는 연속 그리기 호출이 없도록 렌더링 시퀀스를 수정합니다. 특히 런타임은 다음 조건을 모두 충족하는 그리기 호출을 연결합니다.
- 이전 호출이 DrawPrimitive인 경우 다음 그리기 호출인 경우:
- 는 삼각형 목록을 사용하며, AND
- StartVertex = 이전 StartVertex + 이전 PrimitiveCount * 3을 지정합니다.
- DrawIndexedPrimitive를 사용하는 경우 다음 그리기를 호출하는 경우:
- 는 삼각형 목록을 사용하며, AND
- StartIndex = 이전 StartIndex + 이전 PrimitiveCount * 3, AND를 지정합니다.
- BaseVertexIndex = 이전 BaseVertexIndex를 지정합니다.
프로파일링할 때 간과하기 쉬운 그리기 호출 연결의 더 미묘한 예는 다음과 같습니다. 렌더링 시퀀스가 다음과 같다고 가정합니다.
for(int i = 0; i < 1500; i++)
{
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
예제 5c: 하나의 상태 변경 및 하나의 그리기 호출
루프는 1500개의 삼각형을 반복하여 텍스처를 설정하고 각 삼각형을 그립니다. 이 렌더링 루프는 이전 섹션에 표시된 것처럼 SetTexture의 경우 약 2750주기와 DrawPrimitive의 경우 1100주기를 사용합니다. SetTexture를 렌더링 루프 외부로 이동하면 SetTexture 호출과 관련된 작업의 양인 1500 * 2750 주기로 드라이버에서 수행하는 작업의 양이 1500회 감소할 것으로 예상할 수 있습니다. 코드 조각은 다음과 같습니다.
SetTexture(...); // Set the state outside the loop
for(int i = 0; i < 1500; i++)
{
// SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
예제 5d: 루프 외부에서 상태 변경이 있는 예제 5c
SetTexture를 렌더링 루프 외부로 이동하면 SetTexture가 1500번이 아닌 한 번 호출되므로 SetTexture와 관련된 작업의 양이 줄어듭니다. 그리기 호출 연결에 대한 모든 조건이 충족되므로 DrawPrimitive에 대한 작업도 1500개 호출에서 1개 호출로 줄어듭니다. 렌더링 시퀀스가 처리되면 런타임은 단일 드라이버 호출로 1500개의 호출을 처리합니다. 이 한 줄의 코드를 이동하면 드라이버 작업의 양이 크게 감소했습니다.
total work done = runtime + driver work
Example 5c: with SetTexture in the loop:
runtime work = 1500 SetTextures + 1500 DrawPrimitives
driver work = 1500 SetTextures + 1500 DrawPrimitives
Example 5d: with SetTexture outside of the loop:
runtime work = 1 SetTexture + 1 DrawPrimitive + 1499 Concatenated DrawPrimitives
driver work = 1 SetTexture + 1 DrawPrimitive
이러한 결과는 완전히 정확하지만 원래 질문의 맥락에서 매우 오해의 소지가 있습니다. 그리기 호출 최적화로 인해 드라이버 작업의 양이 크게 감소했습니다. 사용자 지정 프로파일링을 수행할 때 일반적인 문제입니다. 렌더링 시퀀스에서 호출을 제거할 때는 그리기 호출 연결이 발생하지 않도록 주의해야 합니다. 실제로 이 시나리오는 이 런타임 최적화를 통해 가능한 드라이버 성능 개선의 강력한 예입니다.
이제 상태 변경 내용을 측정하는 방법을 알고 있습니다. DrawPrimitive를 프로파일링하여 시작합니다. 그런 다음 시퀀스에 각 추가 상태 변경을 추가하고(경우에 따라 한 호출을 추가하고 다른 경우에는 두 개의 호출을 추가하는 경우) 두 시퀀스의 차이를 측정합니다. 결과를 틱 또는 주기 또는 시간으로 변환할 수 있습니다. QueryPerformanceCounter를 사용하여 렌더링 시퀀스를 측정하는 것과 마찬가지로 개별 상태 변경 내용을 측정하는 것은 쿼리 메커니즘을 사용하여 명령 버퍼를 제어하고 상태 변경 내용을 루프에 배치하여 모드 전환의 영향을 최소화합니다. 이 기술은 프로파일러가 상태를 사용하도록 설정하고 사용하지 않도록 설정하는 평균을 반환하기 때문에 상태를 토글하는 비용을 측정합니다.
이 기능을 사용하면 임의의 렌더링 시퀀스를 생성하고 연결된 런타임 및 드라이버 작업을 정확하게 측정할 수 있습니다. 그런 다음 CPU 제한 시나리오를 가정하여 렌더링 시퀀스에서 "이러한 호출 중 몇 개 이상"을 수행할 수 있는지와 같은 예산 질문에 답하는 데 이 숫자를 사용할 수 기본 합리적인 프레임 속도를 얻을 수 있습니다.
요약
이 문서에서는 개별 호출을 정확하게 프로파일링할 수 있도록 명령 버퍼를 제어하는 방법을 보여 줍니다. 프로파일링 번호는 틱, 주기 또는 절대 시간으로 생성할 수 있습니다. 각 API 호출과 연결된 런타임 및 드라이버 작업의 양을 나타냅니다.
먼저 렌더링 시퀀스에서 Draw*Primitive 호출을 프로파일링합니다. 다음이 필요합니다.
- QueryPerformanceCounter를 사용하여 API 호출당 틱 수를 측정합니다. QueryPerformanceFrequency를 사용하여 원하는 경우 결과를 주기 또는 시간으로 변환합니다.
- 시작하기 전에 쿼리 메커니즘을 사용하여 명령 버퍼를 비웁 수 있습니다.
- 모드 전환의 영향을 최소화하기 위해 렌더링 시퀀스를 루프에 포함합니다.
- 쿼리 메커니즘을 사용하여 GPU가 작업을 완료한 시기를 측정합니다.
- 수행된 작업의 양에 큰 영향을 미칠 런타임 연결에 주의하세요.
이렇게 하면 빌드에 사용할 수 있는 DrawPrimitive에 대한 기준 성능을 제공합니다. 하나의 상태 변경을 프로파일러하려면 다음 추가 팁을 따르세요.
- 알려진 렌더링 시퀀스 프로필에 상태 변경 사항을 새 시퀀스에 추가합니다. 루프에서 테스트가 수행되므로 상태를 반대 값(예: 사용 및 사용 안 함)으로 두 번 설정해야 합니다.
- 두 시퀀스 간의 주기 시간 차이를 비교합니다.
- 파이프라인(예: SetTexture)을 크게 변경하는 상태 변경의 경우 두 시퀀스의 차이를 빼서 상태 변경 시간을 가져옵니다.
- 파이프라인을 크게 변경하는 상태 변경의 경우(따라서 SetRenderState와 같은 상태를 전환해야 함) 렌더링 시퀀스의 차이를 빼고 2로 나눕니다. 이렇게 하면 각 상태 변경에 대한 평균 주기 수가 생성됩니다.
그러나 프로파일링할 때 예기치 않은 결과를 초래하는 최적화에 주의해야 합니다. 상태 변경 최적화는 작업을 지연시키는 더티 상태를 설정할 수 있습니다. 이로 인해 프로필 결과가 예상만큼 직관적이지 않을 수 있습니다. 연결된 그리기 호출은 드라이버 작업을 크게 줄여 오해의 소지가 있는 결론을 내릴 수 있습니다. 신중하게 계획된 렌더링 시퀀스는 상태 변경을 방지하고 호출 연결이 발생하지 않도록 하는 데 사용됩니다. 요령은 프로파일링 중에 최적화가 수행되지 않도록 하여 생성하는 숫자가 적절한 예산 수치인지를 방지하는 것입니다.
참고 항목
쿼리 메커니즘 없이 애플리케이션에서 이 프로파일링 전략을 복제하는 것이 더 어렵습니다. Direct3D 9 이전에는 명령 버퍼를 비우는 유일한 예측 가능한 방법은 GPU가 유휴 상태일 때까지 대기하도록 활성 표면(예: 렌더링 대상)을 잠그는 것입니다. 표면을 잠그면 GPU가 완료되기를 기다리는 것 외에도 잠금되기 전에 표면을 업데이트해야 하는 렌더링 명령이 버퍼에 있는 경우 런타임이 명령 버퍼를 비워야 하기 때문입니다. 이 기술은 Direct3D 9에 도입된 쿼리 메커니즘을 사용하는 것이 더 눈에 띄지만 기능적입니다.
부록
이 표의 숫자는 이러한 각 상태 변경과 관련된 런타임 및 드라이버 작업의 양에 대한 근사치 범위입니다. 근사값은 종이에 표시된 기술을 사용하여 드라이버에 대한 실제 측정값을 기반으로 합니다. 이러한 숫자는 Direct3D 9 런타임을 사용하여 생성되었으며 드라이버에 종속됩니다.
이 문서의 기술은 런타임 및 드라이버 작업을 측정하도록 설계되었습니다. 일반적으로 렌더링 시퀀스의 전체 배열이 필요하므로 모든 애플리케이션에서 CPU 및 GPU의 성능과 일치하는 결과를 제공하는 것은 실용적이지 않습니다. 또한 렌더링 시퀀스 전에 파이프라인의 상태 설정에 크게 의존하기 때문에 GPU의 성능을 벤치마킹하기가 특히 어렵습니다. 예를 들어 알파 혼합을 사용하도록 설정해도 필요한 CPU 작업의 양에는 거의 영향을 주지 않지만 GPU에서 수행하는 작업의 양에 큰 영향을 줄 수 있습니다. 따라서 이 문서의 기술은 렌더링해야 하는 데이터의 양을 제한하여 GPU 작업을 가능한 최소 크기로 제한합니다. 즉, 테이블의 숫자는 GPU로 제한되는 애플리케이션과 달리 CPU가 제한된 애플리케이션에서 얻은 결과와 가장 밀접하게 일치합니다.
제시된 기술을 사용하여 가장 중요한 시나리오 및 구성을 다루는 것이 좋습니다. 테이블의 값을 사용하여 생성한 숫자와 비교할 수 있습니다. 각 드라이버가 다르기 때문에 실제 숫자를 생성하는 유일한 방법은 시나리오를 사용하여 프로파일링 결과를 생성하는 것입니다.
| API 호출 | 평균 주기 수 |
|---|---|
| SetVertexDeclaration | 6500 - 11250 |
| SetFVF | 6400 - 11200 |
| SetVertexShader | 3000 - 12100 |
| SetPixelShader | 6300 - 7000 |
| SPECULARENABLE | 1900 - 11200 |
| SetRenderTarget | 6000 - 6250 |
| SetPixelShaderConstant(상수 1개) | 1500 - 9000 |
| NORMALIZENORMALS | 2200 - 8100 |
| LightEnable | 1300 - 9000 |
| SetStreamSource | 3700 - 5800 |
| 조명 | 1700 - 7500 |
| DIFFUSEMATERIALSOURCE | 900 - 8300 |
| AMBIENTMATERIALSOURCE | 900 - 8200 |
| COLORVERTEX | 800 - 7800 |
| SetLight | 2200 - 5100 |
| SetTransform | 3200 - 3750 |
| SetIndices | 900 - 5600 |
| 주위 | 1150 - 4800 |
| SetTexture | 2500 - 3100 |
| SPECULARMATERIALSOURCE | 900 - 4600 |
| EMISSIVEMATERIALSOURCE | 900 - 4500 |
| SetMaterial | 1000 - 3700 |
| ZENABLE | 700 - 3900 |
| WRAP0 | 1600 - 2700 |
| MINFILTER | 1700 - 2500 |
| MAGFILTER | 1700 - 2400 |
| SetVertexShaderConstant(1 상수) | 1000 - 2700 |
| COLOROP | 1500 - 2100 |
| COLORARG2 | 1300 - 2000 |
| COLORARG1 | 1300 - 1980 |
| CULLMODE | 500 - 2570 |
| 클리핑 | 500 - 2550 |
| DrawIndexedPrimitive | 1200 - 1400 |
| ADDRESSV | 1090 - 1500 |
| ADDRESSU | 1070 - 1500 |
| DrawPrimitive | 1050 - 1150 |
| SRGBTEXTURE | 150 - 1500 |
| STENCILMASK | 570 - 700 |
| STENCILZFAIL | 500 - 800 |
| STENCILREF | 550 - 700 |
| ALPHABLENDENABLE | 550 - 700 |
| 스텐실푸NC | 560 - 680 |
| STENCILWRITEMASK | 520 - 700 |
| STENCILFAIL | 500 - 750 |
| ZFUNC | 510 - 700 |
| ZWRITEENABLE | 520 - 680 |
| STENCILENABLE | 540 - 650 |
| 스텐실패스 | 560 - 630 |
| SRCBLEND | 500 - 685 |
| Two_Sided_StencilMODE | 450 - 590 |
| ALPHATESTENABLE | 470 - 525 |
| ALPHAREF | 460 - 530 |
| ALPHAFUNC | 450 - 540 |
| DESTBLEND | 475 - 510 |
| COLORWRITEENABLE | 465 - 515 |
| CCW_STENCILFAIL | 340 - 560 |
| CCW_STENCILPASS | 340 - 545 |
| CCW_STENCILZFAIL | 330 - 495 |
| SCISSORTESTENABLE | 375 - 440 |
| CCW_STENCILFUNC | 250 - 480 |
| SetScissorRect | 150 - 340 |
관련 항목
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기