유니스크립스 용어집
이 용어집에는 Uniscribe 설명서에 사용된 용어에 대한 정의가 포함되어 있습니다.
ABC 너비
ABC 너비는 GDI ABC 구조체로 정의된 복합 값입니다. 구조체에는 문자 모양 또는 실행의 "A", "B" 및 "C" 너비에 해당하는 abcA, abcB 및 abcC 멤버가 포함됩니다.
"A" 너비는 문자 모양 또는 실행을 나타내는 잉크와 동일한 화면 왼쪽의 언더행 (양수, "안쪽 여백") 또는 오버행 (음수)입니다. "B" 너비는 검은색 너비이며, 가장 왼쪽 잉크에서 가장 오른쪽 잉크까지의 너비입니다. "C" 너비가 잉크 오른쪽에 오버행됩니다.
다음 그림에서는 왼쪽과 오른쪽에 오버행이 있는 기울임꼴 소문자 F를 보여 줍니다. 즉, 여기서 "A" 및 "C" 너비는 모두 음수입니다. 양수 "A" 및 "C" 너비에 대한 그림은 언더행 을 참조하세요.
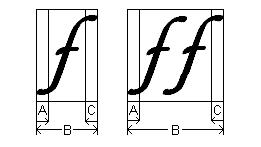
둘 이상의 문자 모양이 단위로 표시되면 일반적으로 맨 왼쪽 문자 모양만 실행의 "A" 너비에 기여하고 맨 오른쪽 문자 모양만 실행의 "C" 너비에 기여합니다. 그러나 이것은 엄격한 규칙이 아닙니다. 예를 들어 실행의 첫 번째 문자 모양이 좁은 문자이고 두 번째 문자 모양이 넓은 분음 부식 표시이고 별도의 문자 모양으로 처리되는 경우 분음 부식 표시는 실제로 문자 이상으로 확장될 수 있습니다.
advance 너비
문자 모양의 사전 너비는 해당 문자 모양을 렌더링하기 위한 시작점에서 다음 문자 모양을 렌더링하기 위한 시작점으로 쓰기 방향으로 이동하는 것입니다.
양방향 스택
양방향 스택은 왼쪽에서 오른쪽에서 왼쪽 텍스트 사이의 중첩 수준을 추적하는 5비트 정수입니다. 항상 왼쪽에서 오른쪽으로 0부터 시작합니다. 따라서 모든 짝수 값은 왼쪽에서 오른쪽 텍스트를 나타내고 모든 홀수 값은 오른쪽에서 왼쪽 텍스트를 나타냅니다. 양방향 스택은 SCRIPT_STATE 구조체의 uBidiLevel 멤버에 표시됩니다.
양방향 텍스트
양방향 텍스트는 왼쪽에서 오른쪽에서 왼쪽으로 두 부분을 모두 포함하지만, 용어는 때로는 순수 오른쪽에서 왼쪽 텍스트에 느슨하게 적용됩니다. 모든 오른쪽에서 왼쪽 텍스트는 양방향 스택을 사용해야 합니다. 기본 포함 수준 0은 왼쪽에서 오른쪽 텍스트를 의미하기 때문입니다.
셀 너비
애플리케이션은 특정 문자 모양에 대한 셀 너비를 조정하여 텍스트가 선에 맞도록 정당화할 수 있습니다. 텍스트가 잘못되었습니다. 문자 모양에 대한 셀 너비는 이전 너비와 같습니다.
cluster
클러스터는 모양을 지정할 수 있는 가장 작은 언어 단위입니다. 아랍어 및 많은 Indic 언어와 같은 언어에서 각 문자(유니코드 코드 포인트)를 나타내는 데 사용되는 문자 모양은 클러스터를 구성하는 주변 코드 포인트에 크게 의존합니다. 이러한 언어에서 애플리케이션은 클러스터를 살펴보면서만 코드 포인트를 적절한 문자 모양으로 변환할 수 있습니다. Devanagari와 같은 일부 스크립트에서는 클러스터 내 문자 모양 순서가 해당 유니코드 코드 지점의 순서와 다를 수 있습니다. 자세한 내용은 Microsoft 입력 체계 사이트의 Windows 문자 모양 처리를 참조하세요.
복잡한 스크립트
복잡한 스크립트는 다음 속성이 있는 스크립트 입니다.
- 양방향 렌더링을 허용합니다.
- 컨텍스트 셰이핑이 있습니다.
- 문자를 결합합니다.
- 특수한 단어 분리 및 정당화 규칙이 있습니다.
- 잘못된 문자 조합을 필터링합니다.
- 핵심 Windows 글꼴에서 지원되지 않으므로 글꼴 대체가 필요할 수 있습니다.
일부 복잡한 스크립트에서는 문자 모양 순서가 나타내는 기본 유니코드 문자의 순서와 상당히 다를 수 있습니다. 자세한 내용은 복잡한 스크립트 정보를 참조하세요.
참고
입력 체계의 컨텍스트에서 영어를 복잡한 스크립트로 작성하는 데 사용되는 라틴어 스크립트를 처리하는 것이 바람직한 경우가 있습니다. 예를 들어 OPENTYPE_FEATURE_RECORD 설명서에 설명된 스타일 대체 기능 또는 단일 문자 모양이 두 개 이상의 연속 문자를 나타내는 "fi"와 같은 합자를 포함합니다.
포함 수준
양방향 텍스트에서 포함 수준은 양방향 스택의 인덱스입니다.
글꼴 대체
글꼴 대체는 애플리케이션에서 사용자가 선택한 글꼴 이외의 글꼴을 자동으로 선택하는 것입니다. Uniscribe에서 텍스트의 전체 또는 일부가 사용자가 선택한 글꼴이 지원하지 않는 스크립트에 있는 경우 ScriptStringAnalyse 함수에 의해 글꼴 대체가 적용됩니다.
문자 모양(glyph)
문자 모양은 글꼴에 표시되는 단일 단위입니다. OpenType의 경우 이 단원은 개요로 정의됩니다. 다른 유형의 글꼴의 경우 비트맵, 그래픽 명령 집합 등으로 정의할 수 있습니다. 문자 모양이 반드시 단일 문자에 해당하지는 않습니다. 예를 들어 "fi" 합자("fi")는 두 문자 "f"와 "i"를 나타냅니다. 할례와 타일 ("")와 베트남어 소문자 "o"는 일반적으로 여러 문자 모양으로 구성됩니다.
항목
항목에는 단일 스크립트 및 방향이 있습니다. ScriptItemize 또는 ScriptItemizeOpenType 함수는 단락을 항목으로 분석할 수 있습니다. 항목이 반드시 실행이 되는 것은 아닙니다. 여러 스타일의 문자를 포함할 수 있습니다. 범위를 확인하려면 항목 및 실행 정보를 결합해야 합니다.
LRM
LRM은 LEFT-TO-RIGHT MARK(유니코드 코드 포인트 U+200E)를 나타냅니다. 이 표시는 논리적 순서로 따라 오는 문자를 왼쪽에서 오른쪽으로 렌더링하도록 지정합니다.
LTR
LTR은 왼쪽에서 오른쪽으로 나타냅니다.
range
범위는 실행의 특별한 경우입니다. 그것은 완전히 하나의 항목 내에 빠진다. 따라서 항목이 실행으로 나뉘면 각 실행은 범위입니다.
Rlm
RLM은 RIGHT-TO-LEFT MARK(유니코드 코드 포인트 U+200F)를 나타냅니다. 이 표시는 논리적 순서로 따라 오는 문자를 오른쪽에서 왼쪽으로 렌더링해야 했음을 나타냅니다.
RTL
RTL은 오른쪽에서 왼쪽으로 나타냅니다.
실행
실행은 Uniscribe가 렌더링할 텍스트의 구절입니다. 글꼴, 크기 및 색과 같은 단일 스타일이 있어야 하지만 다양한 스크립트에서 그릴 수 있습니다. 실행에는 왼쪽에서 오른쪽 및 오른쪽에서 왼쪽 콘텐츠가 모두 포함될 수 있습니다.
NADS
NADS는 NATIONAL DIGIT SHAPES(유니코드 코드 포인트 U+206E)를 나타냅니다. 이 용어는 유럽 숫자(U+0030~ U+0039)를 국가 숫자로 렌더링해야 한다고 지정합니다. 국가 별 숫자에 대한 자세한 내용은 숫자 셰이프를 참조하세요.
끄 덕
NODS는 NOMINAL DIGIT SHAPES(유니코드 코드 포인트 U+206F)를 나타냅니다. 이 용어는 유럽 숫자(U+0030~U+0039)를 국가 숫자가 아닌 정상적으로 렌더링해야 한다고 지정합니다.
오버행
오버행은 문자 모양의 사전 너비 를 넘어 확장되는 문자 모양 잉크의 일부입니다. 대부분의 문자 모양(예: "H")에는 인접한 문자 모양과 분리할 수 있는 약간의 공백이 있으므로 오버행이 없습니다. 오버행이 있는 문자 모양의 예는 ABC 너비를 설명하기 위해 이 항목에서 사용되는 기울임꼴 "f"입니다. 기울임꼴 "f"의 위쪽과 아래쪽 모두 인접한 문자 모양을 돌출합니다. 오버행은 음의 "A" 또는 "C" 너비에 해당합니다.
패딩(padding)
언더행을 참조하세요.
스크립트
스크립트는 라틴어 스크립트, 아랍어 스크립트, 중국어 스크립트와 같이 작성된 언어의 시스템입니다. 단일 스크립트는 하나 이상의 인간 언어에 적용할 수 있습니다. 스크립트는 글꼴과 특별한 관계가 없습니다. 예를 들어 라틴어 스크립트는 Times New Roman 또는 Arial 글꼴에 의해 똑같이 잘 렌더링될 수 있습니다.
underhang
언더행은 문자 모양의 단색 부분의 왼쪽 또는 오른쪽에 있는 공백의 너비입니다. 언더행은 ABC 너비에 대해 설명된 대로 양수 "A" 또는 "C" 너비에 해당합니다. 언더행은 "패딩"으로도 알려져 있습니다. 다음 그림에서는 소문자 n의 언더행을 보여 줍니다.
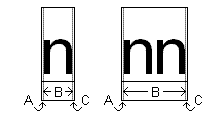
관련 항목
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기