Significant version changes in HDInsight 4.0 and advantages
HDInsight 4.0 has several advantages over HDInsight 3.6. Here's an overview of what's new in Azure HDInsight 4.0.
| # | OSS component | HDInsight 4.0 Version | HDInsight 3.6 Version |
|---|---|---|---|
| 1 | Apache Hadoop | 3.1.1 | 2.7.3 |
| 2 | Apache HBase | 2.1.6 | 1.1.2 |
| 3 | Apache Hive | 3.1.0 | 1.2.1, 2.1 (LLAP) |
| 4 | Apache Kafka | 2.1.1, 2.4(GA) | 1.1 |
| 5 | Apache Phoenix | 5 | 4.7.0 |
| 6 | Apache Spark | 2.4.4, 3.0.0(Preview) | 2.2 |
| 7 | Apache TEZ | 0.9.1 | 0.7.0 |
| 8 | Apache ZooKeeper | 3.4.6 | 3.4.6 |
| 9 | Apache Kafka | 2.1.1, 2.4.1(Preview) | 1.1 |
| 10 | Apache Ranger | 1.1.0 | 0.7.0 |
Workloads and Features
Hive
- Advanced features
- LLAP workload management
- LLAP Support JDBC, Druid and Kafka connectors
- Better SQL features – Constraints and default values
- Surrogate Keys
- Information schema.
- Performance advantage
- Result caching - Caching query results allow a previously computed query result to be reused
- Dynamic materialized views - Precomputation of summaries
- ACID V2 performance improvements in both storage format and execution engine
- Security
- GDPR compliance enabled on Apache Hive transactions
- Hive UDF execution authorization in ranger
HBase
- Advanced features
- Procedure 2. Procedure V2, or procv2, is an updated framework for executing multistep HBase administrative operations.
- Fully off-heap read/write path.
- In-memory compactions
- HBase cluster supports Premium ADLS Gen2
- Performance advantage
- Accelerated Writes uses Azure premium SSD managed disks to improve performance of the Apache HBase Write Ahead Log (WAL).
- Security
- Hardening of both secondary indexes, which include Local and Global
Kafka
- Advanced features
- Kafka partition distribution on Azure fault domains
- Zstd compression support
- Kafka Consumer Incremental Rebalance
- Support MirrorMaker 2.0
- Performance advantage
- Improved windowed aggregation performance in Kafka Streams
- Improved broker resiliency by reducing memory footprint of message conversion
- Replication protocol improvements for fast leader failover
- Security
- Access control for topic creation for specific topics/topic prefix
- Hostname verification to prevent SSL configuration man-in-the- middle attacks
- Improved encryption support with faster Transport Layer Security (TLS) and CRC32C implementation
Spark
- Advanced features
- Structured streaming support for ORC
- Capability to integrate with new Metastore Catalog feature
- Structured Streaming support for Hive Streaming library
- Transparent write to Hive warehouse
- Spark Cruise - an automatic computation reuse system for Spark.
- Performance advantage
- Result caching - Caching query results allow a previously computed query result to be reused
- Dynamic materialized views - Precomputation of summaries
- Security
- GDPR compliance enabled for Spark transactions
Hive Partition Discovery and Repair
Hive automatically discovers and synchronizes the metadata of the partition in Hive Metastore.
The discover.partitions table property enables and disables synchronization of the file system with partitions. In external partitioned tables, this property is enabled (true) by default.
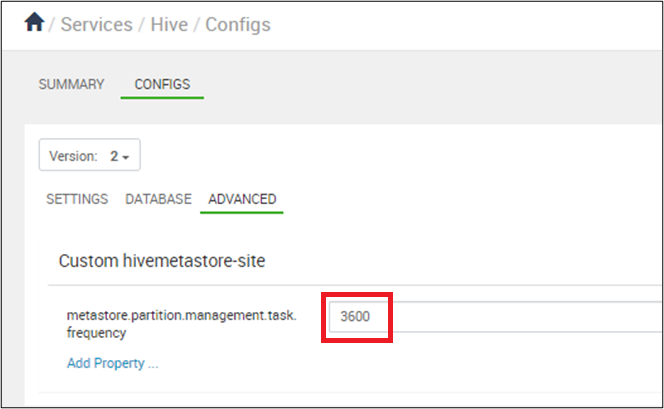
When Hive Metastore Service (HMS) is started in remote service mode, a background thread (PartitionManagementTask) gets scheduled periodically every 300 s (configurable via metastore.partition.management.task.frequency config) that looks for tables with discover.partitions table property set to true and performs msck repair in sync mode.
If the table is a transactional table, then Exclusive Lock is obtained for that table before performing msck repair. With this table property, MSCK REPAIR TABLE table_name SYNC PARTITIONS is no longer required to be run manually.
Assuming you have an external table created using a version of Hive that doesn't support partition discovery, enable partition discovery for the table.
ALTER TABLE exttbl SET TBLPROPERTIES ('discover.partitions' = 'true');
Set synchronization of partitions to occur every 10 minutes expressed in seconds: In Ambari > Hive > Configs, set metastore.partition.management.task.frequency to 3600 or more.
Warning
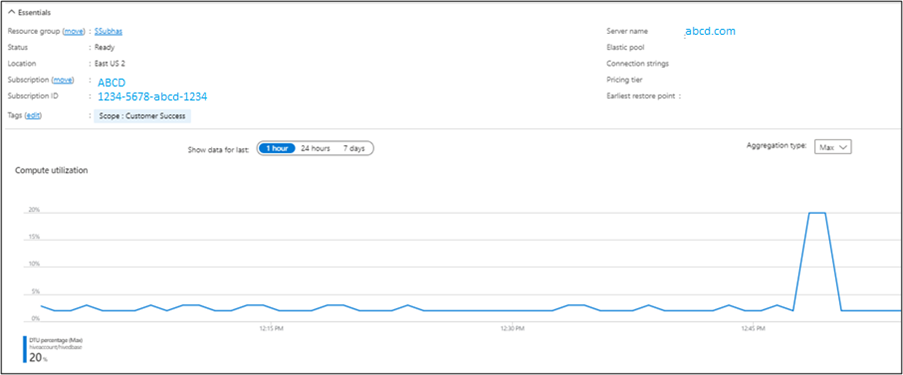
With the management.task running every 10 minutes, there will be pressure on the SQL server DTU.
You can verify the output from Microsoft Azure portal.
Hive drops the metadata and corresponding data in any partition created after the retention period. You express the retention time using a numeral and the following character or characters. Hive drops the metadata and corresponding data in any partition created after the retention period. You express the retention time using a numeral and the following character(s).
ms (milliseconds)
s (seconds)
m (minutes)
d (days)
To configure a partition retention period for one week.
ALTER TABLE employees SET TBLPROPERTIES ('partition.retention.period'='7d');
The partition metadata and the actual data for employees in Hive is automatically dropped after a week.
Hive 3
Performance optimizations available under Hive 3
OLAP Vectorization Dynamic Semijoin reduction Parquet support for vectorization with LLAP Automatic query cache.
New SQL features
Materialized Views Surrogate Keys Constraints Metastore CachedStore.
OLAP Vectorization
Vectorization allows Hive to process a batch of rows together instead of processing one row at a time. Each batch is usually an array of primitive types. Operations are performed on the entire column vector, which improves the instruction pipelines and cache usage. Vectorized execution of PTF, roll up and grouping sets.
Dynamic Semijoin reduction
Dramatically improves performance for selective joins. It builds a bloom filter from one side of join and filters rows from other side. Skips scan and further evaluation of rows that wouldn't qualify the join.
Parquet support for vectorization with LLAP
Vectorized query execution is a feature that greatly reduces the CPU usage for typical query operations such as
- scans
- filters
- aggregate
- joins
Vectorization is also implemented for the ORC format. Spark also uses Whole Stage Codegen and this vectorization (for Parquet) since Spark 2.0. Added timestamp column for Parquet vectorization and format under LLAP.
Warning
Parquet writes are slow when conversion to zoned times from timestamp. For more information, see here.
Automatic query cache
- With
hive.query.results.cache.enabled=true, every query that runs in Hive 3 stores its result in a cache. - If the input table changes, Hive evicts invalid data from the cache. For example, if you perform aggregation and the base table changes, queries you run most frequently stay in cache, but stale queries are evicted.
- The query result cache works with managed tables only because Hive can't track changes to an external table.
- If you join external and managed tables, Hive falls back to executing the full query. The query result cache works with ACID tables. If you update an ACID table, Hive reruns the query automatically.
- You can enable and disable the query result cache from command line. You might want to do so to debug a query.
- Disable the query result cache by setting the following parameter to false:
hive.query.results.cache.enabled=false - Hive stores the query result cache in
/tmp/hive/__resultcache__/. By default, Hive allocates 2 GB for the query result cache. You can change this setting by configuring the following parameter in bytes:hive.query.results.cache.max.size - Changes to query processing: During query compilation, check the results cache to see if it already has the query results. If there's a cache hit, then the query plan is set to a
FetchTaskthat reads from the cached location.
During query execution:
Parquet DataWriteableWriter relies on NanoTimeUtils to convert a timestamp object into a binary value. This query calls toString() on the timestamp object, and then parses the String.
- If the results cache can be used for this query
- The query is
FetchTaskreading from the cached results directory. - No cluster tasks are required.
- The query is
- If the results cache can't be used, run the cluster tasks as normal
- Check if the query results that have been computed are eligible to add to the results cache.
- If results can be cached, the temporary results generated for the query are saved to the results cache. You might need to perform steps here to ensure that the query clean-up does not delete the query results directory.
SQL features
Materialized Views
The initial implementation introduced in Apache Hive 3.0.0 focuses on introducing materialized views and automatic query rewriting based on those materializations in the project. Materialized views can be stored natively in Hive or in other custom storage handlers (ORC), and they can seamlessly exploit exciting new Hive features such as LLAP acceleration.
More information, see Hive - Materialized Views - Microsoft Tech Community
Surrogate Keys
Use the built-in SURROGATE_KEY user-defined function (UDF) to automatically generate numerical Ids for rows as you enter data into a table. The generated surrogate keys can replace wide, multiple composite keys.
Hive supports the surrogate keys on ACID tables only. The table you want to join using surrogate keys can't have column types that need casting. These data types must be primitives, such as INT or STRING.
Joins using the generated keys are faster than joins using strings. Using generated keys doesn't force data into a single node by a row number. You can generate keys as abstractions of natural keys. Surrogate keys have an advantage over UUIDs, which are slower and probabilistic.
The SURROGATE_KEY UDF generates a unique ID for every row that you insert into a table.
It generates keys based on the execution environment in a distributed system, which includes many factors, such as
- Internal data structures
- State of a table
- Last transaction ID.
Surrogate key generation doesn't require any coordination between compute tasks. The UDF takes no arguments, or two arguments are
- Write ID bits
- Task ID bits
Constraints
SQL constraints to enforce data integrity and improve performance. The optimizer uses the constraint information to make smart decisions. Constraints can make data predictable and easy to locate.
| Constraints | Description |
|---|---|
| Check | Limits the range of values you can place in a column. |
| PRIMARY KEY | Identifies each row in a table using a unique identifier. |
| FOREIGN KEY | Identifies a row in another table using a unique identifier. |
| UNIQUE KEY | Checks that values stored in a column are different. |
| NOT NULL | Ensures that a column can't be set to NULL. |
| ENABLE | Ensures that all incoming data conforms to the constraint. |
| DISABLE | Doesn't ensure that all incoming data conforms to the constraint. |
| VALIDATEC | hecks that all existing data in the table conforms to the constraint. |
| NOVALIDATE | Doesn't check that all existing data in the table conforms to the constraint |
| ENFORCED | Maps to ENABLE NOVALIDATE. |
| NOT ENFORCED | Maps to DISABLE NOVALIDATE. |
| RELY | Specifies abiding by a constraint; used by the optimizer to apply further optimizations. |
| NORELY | Specifies not abiding by a constraint. |
For more information, see https://cwiki.apache.org/confluence/display/Hive/Supported+Features%3A++Apache+Hive+3.1
Metastore CachedStore
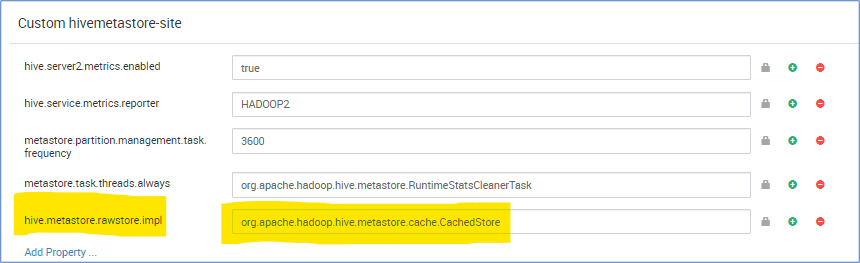
Hive metastore operation takes much time and thus slow down Hive compilation. In some extreme case, it takes longer than the actual query run time. Especially, we find the latency of cloud db is high and 90% of total query runtime is waiting for metastore SQL database operations. Based on this observation, the metastore operation performance is enhanced, if we have a memory structure which cache the database query result.
hive.metastore.rawstore.impl=org.apache.hadoop.hive.metastore.cache.CachedStore
Troubleshooting guide
HDInsight 3.6 to 4.0 troubleshooting guide for Hive workloads provides answers to common issues faced when migrating Hive workloads from HDInsight 3.6 to HDInsight 4.0.
References
Hive 3.1.0
HBase 2.1.6
https://apache.googlesource.com/hbase/+/ba26a3e1fd5bda8a84f99111d9471f62bb29ed1d/RELEASENOTES.md
Hadoop 3.1.1
Further reading
Feedback
Disponibbli dalwaqt: Matul l-2024 se nkunu qed inwaqqfu gradwalment Problemi GitHub bħala l-mekkaniżmu ta’ feedback għall-kontenut u se nibdluh b’sistema ġdida ta’ feedback. Għal aktar informazzjoni, ara: https://aka.ms/ContentUserFeedback.
Issottometti u ara feedback għal