Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is the next generation of Azure Data Factory, with a simpler architecture, built-in AI, and new features. If you're new to data integration, start with Fabric Data Factory. Existing ADF workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
This article outlines how to use Copy Activity in Azure Data Factory to copy data from and to a REST endpoint. The article builds on Copy Activity in Azure Data Factory, which presents a general overview of Copy Activity.
The difference among this REST connector, HTTP connector, and the Web table connector are:
- REST connector specifically supports copying data from RESTful APIs.
- HTTP connector is generic to retrieve data from any HTTP endpoint, for example, to download file. Before this REST connector you may happen to use HTTP connector to copy data from RESTful APIs, which is supported but less functional comparing to REST connector.
- Web table connector extracts table content from an HTML webpage.
Supported capabilities
This REST connector is supported for the following capabilities:
| Supported capabilities | IR |
|---|---|
| Copy activity (source/sink) | ① ② |
| Mapping data flow (source/sink) | ① |
① Azure integration runtime ② Self-hosted integration runtime
For a list of data stores that are supported as sources/sinks, see Supported data stores.
Specifically, this generic REST connector supports:
- Copying data from a REST endpoint by using the GET or POST methods and copying data to a REST endpoint by using the POST, PUT or PATCH methods.
- Copying data by using one of the following authentications: Anonymous, Basic, Service Principal, OAuth2 Client Credential, System Assigned Managed Identity and User Assigned Managed Identity.
- Pagination in the REST APIs.
- For REST as source, copying the REST JSON response as-is or parse it by using schema mapping. Only response payload in JSON is supported.
Tip
To test a request for data retrieval before you configure the REST connector in Data Factory, learn about the API specification for header and body requirements. You can use tools like Visual Studio, PowerShell's Invoke-RestMethod or a web browser to validate.
Prerequisites
If your data store is located inside an on-premises network, an Azure virtual network, or Amazon Virtual Private Cloud, you need to configure a self-hosted integration runtime to connect to it.
If your data store is a managed cloud data service, you can use the Azure Integration Runtime. If the access is restricted to IPs that are approved in the firewall rules, you can add Azure Integration Runtime IPs to the allow list.
You can also use the managed virtual network integration runtime feature in Azure Data Factory to access the on-premises network without installing and configuring a self-hosted integration runtime.
For more information about the network security mechanisms and options supported by Data Factory, see Data access strategies.
Get started
To perform the copy activity with a pipeline, you can use one of the following tools or SDKs:
- Copy Data tool
- Azure portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST API
- Azure Resource Manager template
Create a REST linked service using UI
Use the following steps to create a REST linked service in the Azure portal UI.
Browse to the Manage tab in your Azure Data Factory or Synapse workspace and select Linked Services, then select New:
Search for REST and select the REST connector.
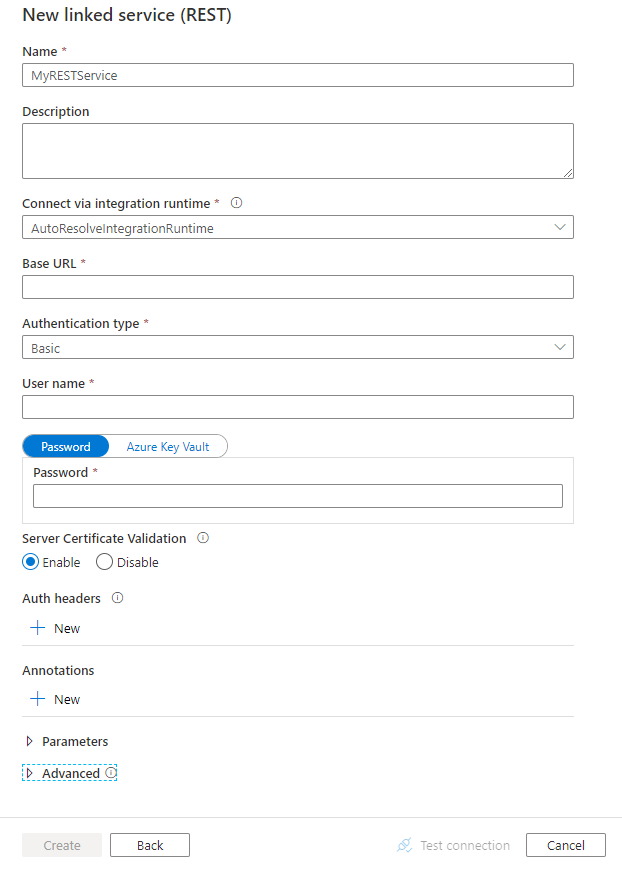
Configure the service details, test the connection, and create the new linked service.
Connector configuration details
The following sections provide details about properties you can use to define Data Factory entities that are specific to the REST connector.
Linked service properties
The following properties are supported for the REST linked service:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to RestService. | Yes |
| url | The base URL of the REST service. | Yes |
| enableServerCertificateValidation | Whether to validate server-side TLS/SSL certificate when connecting to the endpoint. | No (the default is true) |
| authenticationType | Type of authentication used to connect to the REST service. Allowed values are Anonymous, Basic, AadServicePrincipal, OAuth2ClientCredential, and ManagedServiceIdentity. You can additionally configure authentication headers in authHeaders property. Refer to corresponding sections below on more properties and examples respectively. |
Yes |
| authHeaders | Other HTTP request headers for authentication. For example, to use API key authentication, you can select authentication type as "Anonymous" and specify API key in the header. |
No |
| connectVia | The Integration Runtime to use to connect to the data store. Learn more from Prerequisites section. If not specified, this property uses the default Azure Integration Runtime. | No |
For different authentication types, see the corresponding sections for details.
- Basic authentication
- Service Principal authentication
- OAuth2 Client Credential authentication
- System-assigned managed identity authentication
- User-assigned managed identity authentication
- Anonymous authentication
Use basic authentication
Set the authenticationType property to Basic. In addition to the generic properties that are described in the preceding section, specify the following properties:
| Property | Description | Required |
|---|---|---|
| userName | The user name to use to access the REST endpoint. | Yes |
| password | The password for the user (the userName value). Mark this field as a SecureString type to store it securely in Data Factory. You can also reference a secret stored in Azure Key Vault. | Yes |
Example
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"authenticationType": "Basic",
"url" : "<REST endpoint>",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Use Service Principal authentication
Set the authenticationType property to AadServicePrincipal. In addition to the generic properties that are described in the preceding section, specify the following properties:
| Property | Description | Required |
|---|---|---|
| servicePrincipalId | Specify the Microsoft Entra application's client ID. | Yes |
| servicePrincipalCredentialType | Specify the credential type to use for service principal authentication. Allowed values are ServicePrincipalKey and ServicePrincipalCert. |
No |
| For ServicePrincipalKey | ||
| servicePrincipalKey | Specify the Microsoft Entra application's key. Mark this field as a SecureString to store it securely in Data Factory, or reference a secret stored in Azure Key Vault. | No |
| For ServicePrincipalCert | ||
| servicePrincipalEmbeddedCert | Specify the base64 encoded certificate of your application registered in Microsoft Entra ID, and ensure the certificate content type is PKCS #12. Mark this field as a SecureString to store it securely, or reference a secret stored in Azure Key Vault. Go to this section to learn how to save the certificate in Azure Key Vault. | No |
| servicePrincipalEmbeddedCertPassword | Specify the password of your certificate if your certificate is secured with a password. Mark this field as a SecureString to store it securely, or reference a secret stored in Azure Key Vault. | No |
| tenant | Specify the tenant information (domain name or tenant ID) under which your application resides. Retrieve it by hovering the mouse in the top-right corner of the Azure portal. | Yes |
| aadResourceId | Specify the Microsoft Entra resource you're requesting for authorization, for example, https://management.core.windows.net. |
Yes |
| azureCloudType | For Service Principal authentication, specify the type of Azure cloud environment to which your Microsoft Entra application is registered. Allowed values are AzurePublic, AzureChina, AzureUsGovernment, and AzureGermany. By default, the data factory's cloud environment is used. |
No |
Example 1: Using service principal key authentication
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example 2: Using service principal certificate authentication
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalEmbeddedCert": {
"type": "SecureString",
"value": "<the base64 encoded certificate of your application registered in Microsoft Entra ID>"
},
"servicePrincipalEmbeddedCertPassword": {
"type": "SecureString",
"value": "<password of your certificate>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Save the service principal certificate in Azure Key Vault
You have two options to save the service principal certificate in Azure Key Vault:
Option 1
Convert the service principal certificate to a base64 string. Learn more from this article.
Save the base64 string as a secret in Azure Key Vault.
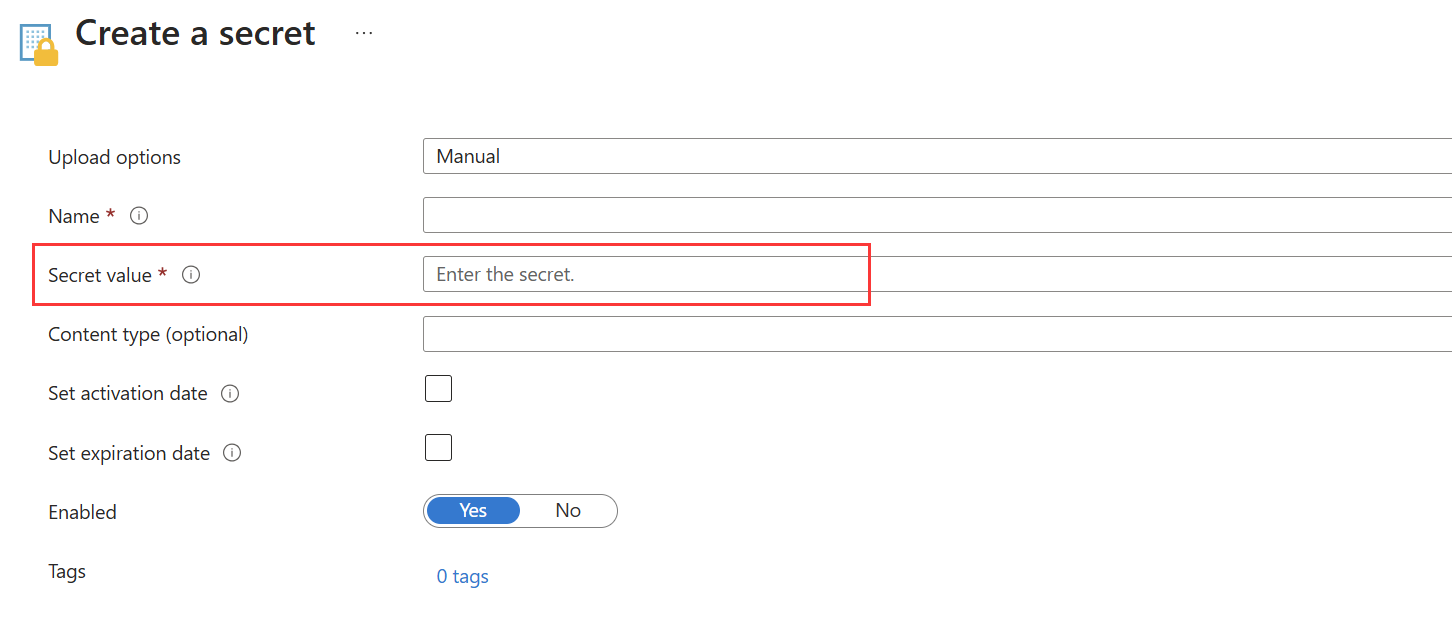
Option 2
If you can't download the certificate from Azure Key Vault, you can use this template to save the converted service principal certificate as a secret in Azure Key Vault.

Use OAuth2 Client Credential authentication
Set the authenticationType property to OAuth2ClientCredential. In addition to the generic properties that are described in the preceding section, specify the following properties:
| Property | Description | Required |
|---|---|---|
| tokenEndpoint | The token endpoint of the authorization server to acquire the access token. | Yes |
| clientId | The client ID associated with your application. | Yes |
| clientSecret | The client secret associated with your application. Mark this field as a SecureString type to store it securely in Data Factory. You can also reference a secret stored in Azure Key Vault. | Yes |
| scope | The scope of the access required. It describes what kind of access will be requested. | No |
| resource | The target service or resource to which the access will be requested. | No |
Example
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"enableServerCertificateValidation": true,
"authenticationType": "OAuth2ClientCredential",
"clientId": "<client ID>",
"clientSecret": {
"type": "SecureString",
"value": "<client secret>"
},
"tokenEndpoint": "<token endpoint>",
"scope": "<scope>",
"resource": "<resource>"
}
}
}
Use system-assigned managed identity authentication
Set the authenticationType property to ManagedServiceIdentity. In addition to the generic properties that are described in the preceding section, specify the following properties:
| Property | Description | Required |
|---|---|---|
| aadResourceId | Specify the Microsoft Entra resource you're requesting for authorization, for example, https://management.core.windows.net. |
Yes |
Example
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<AAD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Use user-assigned managed identity authentication
Set the authenticationType property to ManagedServiceIdentity. In addition to the generic properties that are described in the preceding section, specify the following properties:
| Property | Description | Required |
|---|---|---|
| aadResourceId | Specify the Microsoft Entra resource you're requesting for authorization, for example, https://management.core.windows.net. |
Yes |
| credentials | Specify the user-assigned managed identity as the credential object. | Yes |
Example
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Using authentication headers
In addition, you can configure request headers for authentication along with the built-in authentication types.
Example: Using API key authentication
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint>",
"authenticationType": "Anonymous",
"authHeaders": {
"x-api-key": {
"type": "SecureString",
"value": "<API key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset properties
This section provides a list of properties that the REST dataset supports.
For a full list of sections and properties that are available for defining datasets, see Datasets and linked services.
To copy data from REST, the following properties are supported:
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to RestResource. | Yes |
| relativeUrl | A relative URL to the resource that contains the data. When this property isn't specified, only the URL that's specified in the linked service definition is used. The HTTP connector copies data from the combined URL: [URL specified in linked service]/[relative URL specified in dataset]. |
No |
If you were setting requestMethod, additionalHeaders, requestBody, and paginationRules in dataset, it's still supported as-is, while you're suggested to use the new model in activity going forward.
Example:
{
"name": "RESTDataset",
"properties": {
"type": "RestResource",
"typeProperties": {
"relativeUrl": "<relative url>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<REST linked service name>",
"type": "LinkedServiceReference"
}
}
}
Copy Activity properties
This section provides a list of properties supported by the REST source and sink.
For a full list of sections and properties that are available for defining activities, see Pipelines.
REST as source
The following properties are supported in the copy activity source section:
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity source must be set to RestSource. | Yes |
| requestMethod | The HTTP method. Allowed values are GET (default) and POST. | No |
| additionalHeaders | Other HTTP request headers. | No |
| requestBody | The body for the HTTP request. | No |
| paginationRules | The pagination rules to compose next page requests. Refer to pagination support section on details. | No |
| httpRequestTimeout | The time-out (the TimeSpan value) for the HTTP request to get a response. This value is the time-out to get a response, not the time-out to read response data. The default value is 00:01:40. | No |
| requestInterval | The time to wait before sending the request for next page. The default value is 00:00:01 | No |
Note
The REST connector ignores any "Accept" header specified in additionalHeaders. Since it only supports JSON responses, it automatically sets the header to Accept: application/json.
Pagination isn't supported for REST API responses where the top-level structure is a JSON array.
Example 1: Using the Get method with pagination
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"additionalHeaders": {
"x-user-defined": "helloworld"
},
"paginationRules": {
"AbsoluteUrl": "$.paging.next"
},
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Example 2: Using the Post method
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"requestMethod": "Post",
"requestBody": "<body for POST REST request>",
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
REST as sink
The following properties are supported in the copy activity sink section:
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity sink must be set to RestSink. | Yes |
| requestMethod | The HTTP method. Allowed values are POST (default), PUT, and PATCH. | No |
| additionalHeaders | Other HTTP request headers. | No |
| httpRequestTimeout | The time-out (the TimeSpan value) for the HTTP request to get a response. This value is the time-out to get a response, not the time-out to write the data. The default value is 00:01:40. | No |
| requestInterval | The interval time between different requests in millisecond. Request interval value should be a number between [10, 60000]. | No |
| httpCompressionType | HTTP compression type to use while sending data with Optimal Compression Level. Allowed values are none and gzip. | No |
| writeBatchSize | Number of records to write to the REST sink per batch. The default value is 10000. | No |
REST connector as sink works with the REST APIs that accept JSON. The data will be sent in JSON with the following pattern. As needed, you can use the copy activity schema mapping to reshape the source data to conform to the expected payload by the REST API.
[
{ <data object> },
{ <data object> },
...
]
Example:
"activities":[
{
"name": "CopyToREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<REST output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "RestSink",
"requestMethod": "POST",
"httpRequestTimeout": "00:01:40",
"requestInterval": 10,
"writeBatchSize": 10000,
"httpCompressionType": "none",
},
}
}
]
Mapping data flow properties
REST is supported in data flows for both integration datasets and inline datasets.
Source transformation
| Property | Description | Required |
|---|---|---|
| requestMethod | The HTTP method. Allowed values are GET and POST. | Yes |
| relativeUrl | A relative URL to the resource that contains the data. When this property isn't specified, only the URL that's specified in the linked service definition is used. The HTTP connector copies data from the combined URL: [URL specified in linked service]/[relative URL specified in dataset]. |
No |
| additionalHeaders | Other HTTP request headers. | No |
| httpRequestTimeout | The time-out (the TimeSpan value) for the HTTP request to get a response. This value is the time-out to get a response, not the time-out to write the data. The default value is 00:01:40. | No |
| requestInterval | The interval time between different requests in millisecond. Request interval value should be a number between [10, 60000]. | No |
| QueryParameters.request_query_parameter OR QueryParameters['request_query_parameter'] | "request_query_parameter" is user-defined, which references one query parameter name in the next HTTP request URL. | No |
Sink transformation
| Property | Description | Required |
|---|---|---|
| additionalHeaders | Other HTTP request headers. | No |
| httpRequestTimeout | The time-out (the TimeSpan value) for the HTTP request to get a response. This value is the time-out to get a response, not the time-out to write the data. The default value is 00:01:40. | No |
| requestInterval | The interval time between different requests in millisecond. Request interval value should be a number between [10, 60000]. | No |
| httpCompressionType | HTTP compression type to use while sending data with Optimal Compression Level. Allowed values are none and gzip. | No |
| writeBatchSize | Number of records to write to the REST sink per batch. The default value is 10000. | No |
You can set the delete, insert, update, and upsert methods as well as the relative row data to send to the REST sink for CRUD operations.
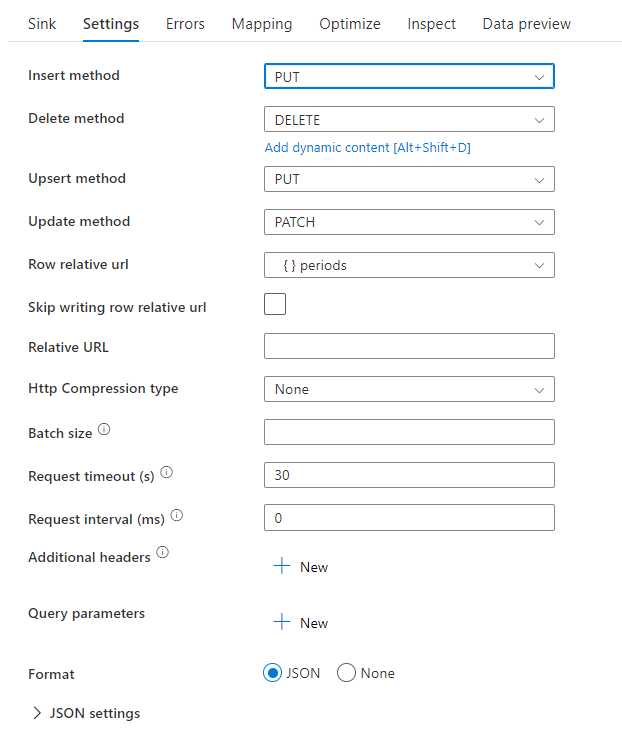
Sample data flow script
Notice the use of an alter row transformation before the sink to instruct ADF what type of action to take with your REST sink. That is, insert, update, upsert, delete.
AlterRow1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
rowRelativeUrl: 'periods',
insertHttpMethod: 'PUT',
deleteHttpMethod: 'DELETE',
upsertHttpMethod: 'PUT',
updateHttpMethod: 'PATCH',
timeout: 30,
requestFormat: ['type' -> 'json'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Note
Data Flow generates a total of N+1 API calls when processing N pages. This includes one initial call to infer the schema, followed by N calls corresponding to the number of pages fetched from the source.
Pagination support
When you copy data from REST APIs, normally, the REST API limits its response payload size of a single request under a reasonable number; while to return large amount of data, it splits the result into multiple pages and requires callers to send consecutive requests to get next page of the result. Usually, the request for one page is dynamic and composed by the information returned from the response of previous page.
This generic REST connector supports the following pagination patterns:
- Next request’s absolute or relative URL = property value in current response body
- Next request’s absolute or relative URL = header value in current response headers
- Next request’s query parameter = property value in current response body
- Next request’s query parameter = header value in current response headers
- Next request’s header = property value in current response body
- Next request’s header = header value in current response headers
Pagination rules are defined as a dictionary in dataset, which contains one or more case-sensitive key-value pairs. The configuration will be used to generate the request starting from the second page. The connector will stop iterating when it gets HTTP status code 204 (No Content), or any of the JSONPath expressions in "paginationRules" returns null.
Supported keys in pagination rules:
| Key | Description |
|---|---|
| AbsoluteUrl | Indicates the URL to issue the next request. It can be either absolute URL or relative URL. |
| QueryParameters.request_query_parameter OR QueryParameters['request_query_parameter'] | "request_query_parameter" is user-defined, which references one query parameter name in the next HTTP request URL. |
| Headers.request_header OR Headers['request_header'] | "request_header" is user-defined, which references one header name in the next HTTP request. |
| EndCondition:end_condition | "end_condition" is user-defined, which indicates the condition that will end the pagination loop in the next HTTP request. |
| MaxRequestNumber | Indicates the maximum pagination request number. Leave it as empty means no limit. |
| SupportRFC5988 | By default, this is set to true if no pagination rule is defined. You can disable this rule by setting supportRFC5988 to false or remove this property from script. |
Supported values in pagination rules:
| Value | Description |
|---|---|
| Headers.response_header OR Headers['response_header'] | "response_header" is user-defined, which references one header name in the current HTTP response, the value of which will be used to issue next request. |
| A JSONPath expression starting with "$" (representing the root of the response body) | The response body should contain only one JSON object and the array of object as the response body isn't supported. The JSONPath expression should return a single primitive value, which will be used to issue next request. |
Note
The pagination rules in mapping data flows is different from it in copy activity in the following aspects:
- Range isn't supported in mapping data flows.
['']isn't supported in mapping data flows. Instead, use{}to escape special character. For example,body.{@odata.nextLink}, whose JSON node@odata.nextLinkcontains special character..- The end condition is supported in mapping data flows, but the condition syntax is different from it in copy activity.
bodyis used to indicate the response body instead of$.headeris used to indicate the response header instead ofheaders. Here are two examples showing this difference:- Example 1:
Copy activity: "EndCondition:$.data": "Empty"
Mapping data flows: "EndCondition:body.data": "Empty" - Example 2:
Copy activity: "EndCondition:headers.complete": "Exist"
Mapping data flows: "EndCondition:header.complete": "Exist"
- Example 1:
Pagination rules examples
This section provides a list of examples for pagination rules settings.
Example 1: Variables in QueryParameters
This example provides the configuration steps to send multiple requests whose variables are in QueryParameters.
Multiple requests:
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
......
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=10000
Step 1: Input sysparm_offset={offset} either in Base URL or Relative URL as shown in the following screenshots:
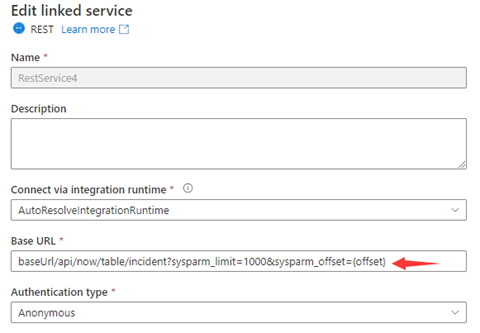
or
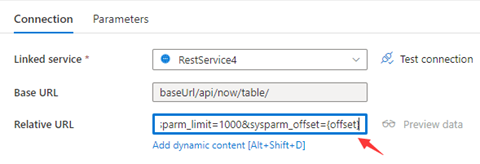
Step 2: Set Pagination rules as either option 1 or option 2:
Option1: "QueryParameters.{offset}" : "RANGE:0:10000:1000"
Option2: "AbsoluteUrl.{offset}" : "RANGE:0:10000:1000"
Example 2:Variables in AbsoluteUrl
This example provides the configuration steps to send multiple requests whose variables are in AbsoluteUrl.
Multiple requests:
BaseUrl/api/now/table/t1
BaseUrl/api/now/table/t2
......
BaseUrl/api/now/table/t100
Step 1: Input {id} either in Base URL in the linked service configuration page or Relative URL in the dataset connection pane.
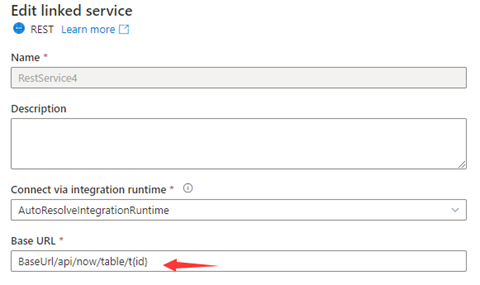
or
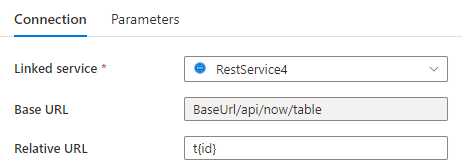
Step 2: Set Pagination rules as "AbsoluteUrl.{id}" :"RANGE:1:100:1".
Example 3:Variables in Headers
This example provides the configuration steps to send multiple requests whose variables are in Headers.
Multiple requests:
RequestUrl: https://example/table
Request 1: Header(id->0)
Request 2: Header(id->10)
......
Request 100: Header(id->100)
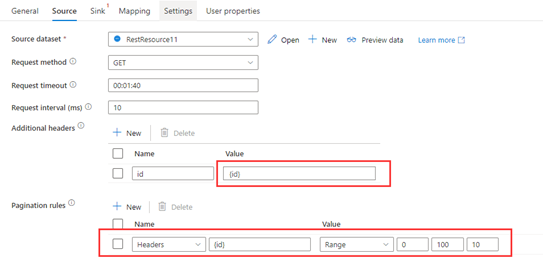
Step 1: Input {id} in Additional headers.
Step 2: Set Pagination rules as "Headers.{id}" : "RANGE:0:100:10".
Example 4:Variables are in AbsoluteUrl/QueryParameters/Headers, the end variable isn't predefined and the end condition is based on the response
This example provides configuration steps to send multiple requests whose variables are in AbsoluteUrl/QueryParameters/Headers but the end variable isn't defined. For different responses, different end condition rule settings are shown in Example 4.1-4.6.
Multiple requests:
Request 1: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
Request 2: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
Request 3: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=2000,
......
Two responses encountered in this example:
Response 1:
{
Data: [
{key1: val1, key2: val2
},
{key1: val3, key2: val4
}
]
}
Response 2:
{
Data: [
{key1: val5, key2: val6
},
{key1: val7, key2: val8
}
]
}
Step 1: Set the range of Pagination rules as Example 1 and leave the end of range empty as "AbsoluteUrl.{offset}": "RANGE:0::1000".
Step 2: Set different end condition rules according to different last responses. See below examples:
Example 4.1: The pagination ends when the value of the specific node in response is empty
The REST API returns the last response in the following structure:
{ Data: [] }Set the end condition rule as "EndCondition:$.data": "Empty" to end the pagination when the value of the specific node in response is empty.

Example 4.2: The pagination ends when the value of the specific node in response does not exist
The REST API returns the last response in the following structure:
{}Set the end condition rule as "EndCondition:$.data": "NonExist" to end the pagination when the value of the specific node in response doesn't exist.

Example 4.3: The pagination ends when the value of the specific node in response exists
The REST API returns the last response in the following structure:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Set the end condition rule as "EndCondition:$.Complete": "Exist" to end the pagination when the value of the specific node in response exists.

Example 4.4: The pagination ends when the value of the specific node in response is a user-defined const value
The REST API returns the response in the following structure:
{ Data: [ {key1: val1, key2: val2 }, {key1: val3, key2: val4 } ], Complete: false }......
And the last response is in the following structure:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Set the end condition rule as "EndCondition:$.Complete": "Const:true" to end the pagination when the value of the specific node in response is a user-defined const value.

Example 4.5: The pagination ends when the value of the header key in response equals to user-defined const value
The header keys in REST API responses are shown in the structure below:
Response header 1:
header(Complete->0)
......
Last Response header:header(Complete->1)Set the end condition rule as "EndCondition:headers.Complete": "Const:1" to end the pagination when the value of the header key in response is equal to user-defined const value.

Example 4.6: The pagination ends when the key exists in the response header
The header keys in REST API responses are shown in the structure below:
Response header 1:
header()
......
Last Response header:header(CompleteTime->20220920)Set the end condition rule as "EndCondition:headers.CompleteTime": "Exist" to end the pagination when the key exists in the response header.

Example 5:Set end condition to avoid endless requests when range rule isn't defined
This example provides the configuration steps to send multiple requests when the range rule isn't used. The end condition can be set refer to Example 4.1-4.6 to avoid endless requests. The REST API returns response in the following structure, in which case next page's URL is represented in paging.next.
{
"data": [
{
"created_time": "2017-12-12T14:12:20+0000",
"name": "album1",
"id": "1809938745705498_1809939942372045"
},
{
"created_time": "2017-12-12T14:14:03+0000",
"name": "album2",
"id": "1809938745705498_1809941802371859"
},
{
"created_time": "2017-12-12T14:14:11+0000",
"name": "album3",
"id": "1809938745705498_1809941879038518"
}
],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "https://graph.facebook.com/me/albums?limit=25&after=MTAxNTExOTQ1MjAwNzI5NDE="
}
}
...
The last response is:
{
"data": [],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "Same with Last Request URL"
}
}
Step 1: Set Pagination rules as "AbsoluteUrl": "$.paging.next".
Step 2: If next in the last response is always same with the last request URL and not empty, endless requests will be sent. The end condition can be used to avoid endless requests. Therefore, set the end condition rule refer to Example 4.1-4.6.
Example 6:Set the max request number to avoid endless request
Set MaxRequestNumber to avoid endless request as shown in the following screenshot:

Example 7:The RFC 5988 pagination rule is supported by default
The backend will automatically get the next URL based on the RFC 5988 style links in the header.

Tip
If you don't want to enable this default pagination rule, you can set supportRFC5988 to false or just delete it in the script.
Example 8a: The next request URL is in the response body when using pagination in mapping data flows
This example states how to set the pagination rule and the end condition rule in mapping data flows when the next request URL is from the response body.
The response schema is shown below:
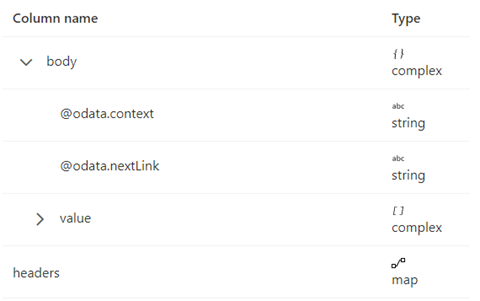
The pagination rules should be set as the following screenshot:

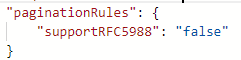
By default, the pagination will stop when body.{@odata.nextLink}** is null or empty.
But if the value of @odata.nextLink in the last response body is equal to the last request URL, then it will lead to the endless loop. To avoid this condition, define end condition rules.
If Value in the last response is Empty, then the end condition rule can be set as below:

If the value of the complete key in the response header equals to true indicates the end of pagination, then the end condition rule can be set as below:
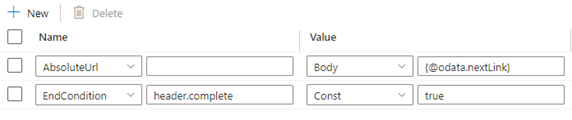
Example 8b: The next request URL is in the response body when using pagination in copy activity
This example demonstrates how to set the pagination rule in a copy activity when the next request URL is contained within the response body.
The response schema is shown below:
The pagination rules should be set as shown in the following screenshot:

Example 9: The response format is XML and the next request URL is from the response body when use pagination in mapping data flows
This example states how to set the pagination rule in mapping data flows when the response format is XML and the next request URL is from the response body. As shown in the following screenshot, the first URL is https://<user>.dfs.core.windows.NET/bugfix/test/movie_1.xml
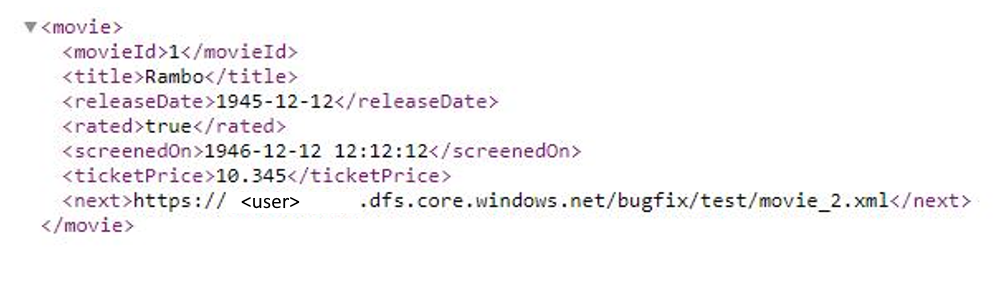
The response schema is shown below:
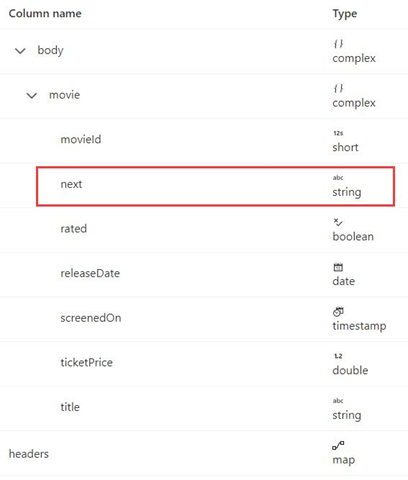
The pagination rule syntax is the same as in Example 8 and should be set as below in this example:

Export JSON response as-is
You can use the REST connector to export a REST API's JSON response as-is to various file-based storage systems (sinks). To enable this schema-agnostic copy behavior, use default schema mapping (don’t define any mapping in the Copy Activity's Mapping tab.)
Schema mapping
To copy data from REST endpoint to tabular sink, refer to schema mapping.
Related content
For a list of data stores that Copy Activity supports as sources and sinks in Azure Data Factory, see Supported data stores and formats.