Obs!
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
In this overview, you learn about the benefits and capabilities of the text to speech feature of the Speech service, which is part of Azure AI services.
Text to speech enables your applications, tools, or devices to convert text into human like synthesized speech. The text to speech capability is also known as speech synthesis. Use human like standard voices out of the box, or create a custom voice that's unique to your product or brand. For a full list of supported voices, languages, and locales, see Language and voice support for the Speech service.
Core features
Text to speech includes the following features:
| Feature | Summary | Demo |
|---|---|---|
| Standard voice (called Neural on the pricing page) | Highly natural out-of-the-box voices. Create an Azure subscription and Speech resource, and then use the Speech SDK or visit the Speech Studio portal and select standard voices to get started. Check the pricing details. | Check the Voice Gallery and determine the right voice for your business needs. |
| Custom voice | Easy-to-use self-service for creating a natural brand voice, with limited access for responsible use. Create an Azure subscription and Azure AI Foundry resource and then apply to use custom voice. After you're granted access, go to the professional voice fine-tuning documentation to get started. Check the pricing details. | Check the voice samples. |
More about neural text to speech features
Text to speech uses deep neural networks to make the voices of computers nearly indistinguishable from the recordings of people. With the clear articulation of words, neural text to speech significantly reduces listening fatigue when users interact with AI systems.
The patterns of stress and intonation in spoken language are called prosody. Traditional text to speech systems break down prosody into separate linguistic analysis and acoustic prediction steps governed by independent models. That can result in muffled, buzzy voice synthesis.
Here's more information about neural text to speech features in the Speech service, and how they overcome the limits of traditional text to speech systems:
Real-time speech synthesis: Use the Speech SDK or REST API to convert text to speech by using standard voices or custom voices.
Asynchronous synthesis of long audio: Use the batch synthesis API to asynchronously synthesize text to speech files longer than 10 minutes (for example, audio books or lectures). Unlike synthesis performed via the Speech SDK or Speech to text REST API, responses aren't returned in real-time. The expectation is that requests are sent asynchronously, responses are polled for, and synthesized audio is downloaded when the service makes it available.
Standard voices: Azure AI Speech uses deep neural networks to overcome the limits of traditional speech synthesis regarding stress and intonation in spoken language. Prosody prediction and voice synthesis happen simultaneously, which results in more fluid and natural-sounding outputs. Each standard voice model is available at 24 kHz and high-fidelity 48 kHz. You can use neural voices to:
- Make interactions with chatbots and voice assistants more natural and engaging.
- Convert digital texts such as e-books into audiobooks.
- Enhance in-car navigation systems.
For a full list of standard Azure AI Speech neural voices, see Language and voice support for the Speech service.
Improve text to speech output with SSML: Speech Synthesis Markup Language (SSML) is an XML-based markup language used to customize text to speech outputs. With SSML, you can adjust pitch, add pauses, improve pronunciation, change speaking rate, adjust volume, and attribute multiple voices to a single document.
You can use SSML to define your own lexicons or switch to different speaking styles. With the multilingual voices, you can also adjust the speaking languages via SSML. To improve the voice output for your scenario, see Improve synthesis with Speech Synthesis Markup Language and Speech synthesis with the Audio Content Creation tool.
Visemes: Visemes are the key poses in observed speech, including the position of the lips, jaw, and tongue in producing a particular phoneme. Visemes have a strong correlation with voices and phonemes.
By using viseme events in Speech SDK, you can generate facial animation data. This data can be used to animate faces in lip-reading communication, education, entertainment, and customer service. Viseme is currently supported only for the
en-US(US English) neural voices.
Note
In addition to Azure AI Speech neural (non HD) voices, you can also use Azure AI Speech high definition (HD) voices and Azure OpenAI neural (HD and non HD) voices. The HD voices provide a higher quality for more versatile scenarios.
Some voices don't support all Speech Synthesis Markup Language (SSML) tags. This includes neural text to speech HD voices, personal voices, and embedded voices.
- For Azure AI Speech high definition (HD) voices, check the SSML support here.
- For personal voice, you can find the SSML support here.
- For embedded voices, check the SSML support here.
Get started
To get started with text to speech, see the quickstart. Text to speech is available via the Speech SDK, the REST API, and the Speech CLI.
Tip
To convert text to speech with a no-code approach, try the Audio Content Creation tool in Speech Studio.
Sample code
Sample code for text to speech is available on GitHub. These samples cover text to speech conversion in most popular programming languages:
Custom voice
In addition to standard voices, you can create custom voices that are unique to your product or brand. Custom voice is an umbrella term that includes professional voice fine-tuning and personal voice. All it takes to get started is a handful of audio files and the associated transcriptions. For more information, see the professional voice fine-tuning documentation.
Pricing note
Billable characters
When you use the text to speech feature, you're billed for each character that's converted to speech, including punctuation. Although the SSML document itself isn't billable, optional elements that are used to adjust how the text is converted to speech, like phonemes and pitch, are counted as billable characters. Here's a list of what's billable:
- Text passed to the text to speech feature in the SSML body of the request
- All markup within the text field of the request body in the SSML format, except for
<speak>and<voice>tags - Letters, punctuation, spaces, tabs, markup, and all white-space characters
- Every code point defined in Unicode
For detailed information, see Speech service pricing.
Important
Each Chinese character is counted as two characters for billing, including kanji used in Japanese, hanja used in Korean, or hanzi used in other languages.
Model training and hosting time for custom voice
Custom voice training and hosting are both calculated by hour and billed per second. For the billing unit price, see Speech service pricing.
Professional voice fine-tuning time is measured by "compute hour" (a unit to measure machine running time). Typically, when training a voice model, two computing tasks are running in parallel. So, the calculated compute hours are longer than the actual training time. For professional voice fine-tuning, it usually takes 20 to 40 compute hours to train a single-style voice, and around 90 compute hours to train a multi-style voice. The professional voice fine-tuning time is billed with a cap of 96 compute hours. So in the case that a voice model is trained in 98 compute hours, you'll only be charged with 96 compute hours.
Custom voice endpoint hosting is measured by the actual time (hour). The hosting time (hours) for each endpoint is calculated at 00:00 UTC every day for the previous 24 hours. For example, if the endpoint has been active for 24 hours on day one, it's billed for 24 hours at 00:00 UTC the second day. If the endpoint is newly created or suspended during the day, it's billed for its accumulated running time until 00:00 UTC the second day. If the endpoint isn't currently hosted, it isn't billed. In addition to the daily calculation at 00:00 UTC each day, the billing is also triggered immediately when an endpoint is deleted or suspended. For example, for an endpoint created at 08:00 UTC on December 1, the hosting hour will be calculated to 16 hours at 00:00 UTC on December 2 and 24 hours at 00:00 UTC on December 3. If the user suspends hosting the endpoint at 16:30 UTC on December 3, the duration (16.5 hours) from 00:00 to 16:30 UTC on December 3 will be calculated for billing.
Personal voice
When you use the personal voice feature, you're billed for both profile storage and synthesis.
- Profile storage: After a personal voice profile is created, it will be billed until it's removed from the system. The billing unit is per voice per day. If voice storage lasts for less than 24 hours, it's still billed as one full day.
- Synthesis: Billed per character. For details on billable characters, see the above billable characters.
Text to speech avatar
When you use the text-to-speech avatar feature, charges are billed per second based on the length of video output. However, for the real-time avatar, charges are billed per second based on the time when the avatar is active, regardless of whether it's speaking or remaining silent. To optimize costs for real-time avatar usage, refer to the "Use Local Video for Idle" tips provided in the avatar chat sample code.
Custom text to speech avatar training is time is measured by "compute hour" (machine running time) and billed per second. Training duration varies depending on how much data you use. It normally takes 20-40 compute hours on average to train a custom avatar. The avatar training time is billed with a cap of 96 compute hours. So in the case that an avatar model is trained in 98 compute hours, you're only charged for 96 compute hours.
Avatar hosting is billed per second per endpoint. You can suspend your endpoint to save costs. If you want to suspend your endpoint, you can delete it directly. To use it again, redeploy the endpoint.
Monitor Azure text to speech metrics
Monitoring key metrics associated with text to speech services is crucial for managing resource usage and controlling costs. This section guides you on how to find usage information in the Azure portal and provide detailed definitions of the key metrics. For more information on Azure monitor metrics, see Azure Monitor Metrics overview.
How to find usage information in the Azure portal
To effectively manage your Azure resources, it's essential to access and review usage information regularly. Here's how to find the usage information:
Go to the Azure portal and sign in with your Azure account.
Navigate to Resources and select your resource you wish to monitor.
Select Metrics under Monitoring from the left-hand menu.
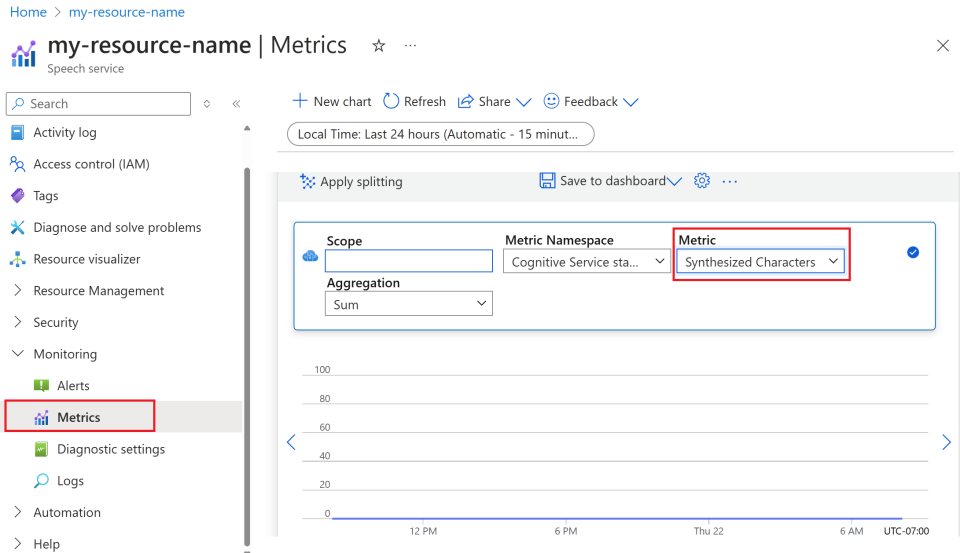
Customize metric views.
You can filter data by resource type, metric type, time range, and other parameters to create custom views that align with your monitoring needs. Additionally, you can save the metric view to dashboards by selecting Save to dashboard for easy access to frequently used metrics.
Set up alerts.
To manage usage more effectively, set up alerts by navigating to the Alerts tab under Monitoring from the left-hand menu. Alerts can notify you when your usage reaches specific thresholds, helping to prevent unexpected costs.
Definition of metrics
Here's a table summarizing the key metrics for Azure text to speech.
| Metric name | Description |
|---|---|
| Synthesized Characters | Tracks the number of characters converted into speech, including standard voice and custom voice. For details on billable characters, see Billable characters. |
| Video Seconds Synthesized | Measures the total duration of video synthesized, including batch avatar synthesis, real-time avatar synthesis, and custom avatar synthesis. |
| Avatar Model Hosting Seconds | Tracks the total time in seconds that your custom avatar model is hosted. |
| Voice Model Hosting Hours | Tracks the total time in hours that your custom voice model is hosted. |
| Voice Model Training Minutes | Measures the total time in minutes for training your custom voice model. |
Reference docs
Responsible AI
An AI system includes not only the technology, but also the people who use it, the people who are affected by it, and the environment in which it's deployed. Read the transparency notes to learn about responsible AI use and deployment in your systems.
- Transparency note and use cases for custom voice
- Characteristics and limitations for using custom voice
- Limited access to custom voice
- Guidelines for responsible deployment of synthetic voice technology
- Disclosure for voice talent
- Disclosure design guidelines
- Disclosure design patterns
- Code of Conduct for Text to speech integrations
- Data, privacy, and security for custom voice