Tutorial: Configure availability groups for SQL Server on Ubuntu virtual machines in Azure
In this tutorial, you'll learn how to:
- Create virtual machines, place them in availability set
- Enable high availability (HA)
- Create a Pacemaker cluster
- Configure a fencing agent by creating a STONITH device
- Install SQL Server and mssql-tools on Ubuntu
- Configure SQL Server Always On availability group
- Configure availability group (AG) resources in the Pacemaker cluster
- Test a failover and the fencing agent
Note
Bias-free communication
This article contains references to the term slave, a term Microsoft considers offensive when used in this context. The term appears in this article because it currently appears in the software. When the term is removed from the software, we will remove it from the article.
This tutorial uses the Azure CLI to deploy resources in Azure.
If you don't have an Azure subscription, create a free account before you begin.
Prerequisites
Use the Bash environment in Azure Cloud Shell. For more information, see Quickstart for Bash in Azure Cloud Shell.

If you prefer to run CLI reference commands locally, install the Azure CLI. If you're running on Windows or macOS, consider running Azure CLI in a Docker container. For more information, see How to run the Azure CLI in a Docker container.
If you're using a local installation, sign in to the Azure CLI by using the az login command. To finish the authentication process, follow the steps displayed in your terminal. For other sign-in options, see Sign in with the Azure CLI.
When you're prompted, install the Azure CLI extension on first use. For more information about extensions, see Use extensions with the Azure CLI.
Run az version to find the version and dependent libraries that are installed. To upgrade to the latest version, run az upgrade.
- This article requires version 2.0.30 or later of the Azure CLI. If using Azure Cloud Shell, the latest version is already installed.
Create a resource group
If you have more than one subscription, set the subscription that you want deploy these resources to.
Use the following command to create a resource group <resourceGroupName> in a region. Replace <resourceGroupName> with a name of your choosing. This tutorial uses East US 2. For more information, see the following Quickstart.
az group create --name <resourceGroupName> --location eastus2
Create an availability set
The next step is to create an availability set. Run the following command in Azure Cloud Shell, and replace <resourceGroupName> with your resource group name. Choose a name for <availabilitySetName>.
az vm availability-set create \
--resource-group <resourceGroupName> \
--name <availabilitySetName> \
--platform-fault-domain-count 2 \
--platform-update-domain-count 2
You should get the following results once the command completes:
{
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/availabilitySets/<availabilitySetName>",
"location": "eastus2",
"name": "<availabilitySetName>",
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2,
"proximityPlacementGroup": null,
"resourceGroup": "<resourceGroupName>",
"sku": {
"capacity": null,
"name": "Aligned",
"tier": null
},
"statuses": null,
"tags": {},
"type": "Microsoft.Compute/availabilitySets",
"virtualMachines": []
}
Create a virtual network and subnet
Create a named subnet with a preassigned IP address range. Replace these values in the following command:
<resourceGroupName><vNetName><subnetName>
az network vnet create \ --resource-group <resourceGroupName> \ --name <vNetName> \ --address-prefix 10.1.0.0/16 \ --subnet-name <subnetName> \ --subnet-prefix 10.1.1.0/24The previous command creates a VNet and a subnet containing a custom IP range.
Create Ubuntu VMs inside the availability set
Get a list of virtual machine images that offer Ubuntu based OS in Azure.
az vm image list --all --offer "sql2022-ubuntupro2004"You should see the following results when you search for the BYOS images:
[ { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.230808", "version": "16.0.230808" } ]This tutorial uses
Ubuntu 20.04.Important
Machine names must be less than 15 characters in length to set up an availability group. Usernames can't contain upper case characters, and passwords must have between 12 and 72 characters.
Create three VMs in the availability set. Replace these values in the following command:
<resourceGroupName><VM-basename><availabilitySetName><VM-Size>- An example would be "Standard_D16s_v3"<username><adminPassword><vNetName><subnetName>
for i in `seq 1 3`; do az vm create \ --resource-group <resourceGroupName> \ --name <VM-basename>$i \ --availability-set <availabilitySetName> \ --size "<VM-Size>" \ --os-disk-size-gb 128 \ --image "Canonical:0001-com-ubuntu-server-jammy:20_04-lts-gen2:latest" \ --admin-username "<username>" \ --admin-password "<adminPassword>" \ --authentication-type all \ --generate-ssh-keys \ --vnet-name "<vNetName>" \ --subnet "<subnetName>" \ --public-ip-sku Standard \ --public-ip-address "" done
The previous command creates the VMs using the previously defined VNet. For more information on the different configurations, see the az vm create article.
The command also includes the --os-disk-size-gb parameter to create a custom OS drive size of 128 GB. If you increase this size later, expand appropriate folder volumes to accommodate your installation, configure the Logical Volume Manager (LVM).
You should get results similar to the following once the command completes for each VM:
{
"fqdns": "",
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/virtualMachines/ubuntu1",
"location": "westus",
"macAddress": "<Some MAC address>",
"powerState": "VM running",
"privateIpAddress": "<IP1>",
"resourceGroup": "<resourceGroupName>",
"zones": ""
}
Test connection to the created VMs
Connect to each of the VMs using the following command in Azure Cloud Shell. If you're unable to find your VM IPs, follow this Quickstart on Azure Cloud Shell.
ssh <username>@<publicIPAddress>
If the connection is successful, you should see the following output representing the Linux terminal:
[<username>@ubuntu1 ~]$
Type exit to leave the SSH session.
Configure passwordless SSH access between nodes
Passwordless SSH access allows your VMs to communicate with each other using SSH public keys. You must configure SSH keys on each node, and copy those keys to each node.
Generate new SSH keys
The required SSH key size is 4,096 bits. On each VM, change to the /root/.ssh folder, and run the following command:
ssh-keygen -t rsa -b 4096
During this step, you might be prompted to overwrite an existing SSH file. You must agree to this prompt. You don't need to enter a passphrase.
Copy the public SSH keys
On each VM, you must copy the public key from the node you just created, using the ssh-copy-id command. If you want to specify the target directory on the target VM, you can use the -i parameter.
In the following command, the <username> account can be the same account you configured for each node when creating the VM. You can also use the root account, but this option isn't recommended in a production environment.
sudo ssh-copy-id <username>@ubuntu1
sudo ssh-copy-id <username>@ubuntu2
sudo ssh-copy-id <username>@ubuntu3
Verify passwordless access from each node
To confirm that the SSH public key was copied to each node, use the ssh command from each node. If you copied the keys correctly, you aren't prompted for a password, and the connection is successful.
In this example, we're connecting to the second and third nodes from the first VM (ubuntu1). Once again the <username> account can be the same account you configured for each node when creating the VM.
ssh <username>@ubuntu2
ssh <username>@ubuntu3
Repeat this process from all three nodes, so that each node can communicate with the others without requiring passwords.
Configure name resolution
You can configure name resolution using either DNS, or by manually editing the etc/hosts file on each node.
For more information about DNS and Active Directory, see Join SQL Server on a Linux host to an Active Directory domain.
Important
We recommend that you use your private IP address in the previous example. Using the public IP address in this configuration will cause the setup to fail, and would expose your VM to external networks.
The VMs and their IP address used in this example are listed as follows:
ubuntu1: 10.0.0.85ubuntu2: 10.0.0.86ubuntu3: 10.0.0.87
Enable High availability
Use ssh to connect to each of the 3 VMs, and once connected, run the following commands to enable high availability.
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Install and configure Pacemaker cluster
To get started with configuring Pacemaker cluster, you need to install the required packages and resource agents. Run the below commands on each of your VMs:
sudo apt-get install -y pacemaker pacemaker-cli-utils crmsh resource-agents fence-agents csync2 python3-azure
Now proceed to create authentication key on primary server:
sudo corosync-keygen
The authkey is generated in /etc/corosync/authkey location. Copy the authkey to secondary servers in this location: /etc/corosync/authkey
sudo scp /etc/corosync/authkey username@ubuntu2:~
sudo scp /etc/corosync/authkey username@ubuntu3:~
Move the authkey from home directory to /etc/corosync.
sudo mv authkey /etc/corosync/authkey
Proceed to create the cluster by using following commands:
cd /etc/corosync/
sudo vi corosync.conf
Edit the Corosync file to depict contents as follows:
totem {
version: 2
secauth: off
cluster_name: demo
transport: udpu
}
nodelist {
node {
ring0_addr: 10.0.0.85
name: ubuntu1
nodeid: 1
}
node {
ring0_addr: 10.0.0.86
name: ubuntu2
nodeid: 2
}
node {
ring0_addr: 10.0.0.87
name: ubuntu3
nodeid: 3
}
}
quorum {
provider: corosync_votequorum
two_node: 0
}
qb {
ipc_type: native
}
logging {
fileline: on
to_stderr: on
to_logfile: yes
logfile: /var/log/corosync/corosync.log
to_syslog: no
debug: off
}
Copy the corosync.conf file to other nodes to /etc/corosync/corosync.conf:
sudo scp /etc/corosync/corosync.conf username@ubuntu2:~
sudo scp /etc/corosync/corosync.conf username@ubuntu3:~
sudo mv corosync.conf /etc/corosync/
Restart Pacemaker and Corosync, and confirm the status:
sudo systemctl restart pacemaker corosync
sudo crm status
The output looks similar to the following example:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by hacluster via crmd on ubuntu1
* 3 nodes configured
* 0 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* No resources
Configure fencing agent
Configure fencing on the cluster. Fencing is the isolation of failed node in a cluster. It restarts the failed node, letting it go down, reset, and come back up, rejoining the cluster.
In order to configure fencing, perform the following actions:
- Register a new application in Microsoft Entra ID and create a secret
- Create a custom role from json file in powershell/CLI
- Assign the role and application to the VMs in cluster
- Set the fencing agent properties
Register a new application in Microsoft Entra ID and create a secret
- Go to Microsoft Entra ID in the portal and make a note of the Tenant ID.
- Select App Registrations on the left hand side menu and then select New Registration.
- Enter a Name and then select Accounts in this organization directory only.
- For Application Type, select Web, enter
http://localhostas a sign-on URL, then select Register. - Select Certificates and secrets on the left hand side menu, then select New client secret.
- Enter a description and select an expiry period.
- Make a note of the value of the secret, it's used as the following password and the secret ID, it's used as the following username.
- Select "Overview" and make a note of the Application ID. It's used as the following login.
Create a JSON file called fence-agent-role.json and add the following (adding your subscription ID):
{
"Name": "Linux Fence Agent Role-ap-server-01-fence-agent",
"Id": null,
"IsCustom": true,
"Description": "Allows to power-off and start virtual machines",
"Actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"NotActions": [],
"AssignableScopes": [
"/subscriptions/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
]
}
Create a custom role from JSON file in PowerShell/CLI
az role definition create --role-definition fence-agent-role.json
Assign the role and application to the VMs in cluster
- For each of the VMs in the cluster, select Access Control (IAM) from the side menu.
- Select Add a role assignment (use the classic experience).
- Select the role created previously.
- In the Select list, enter the name of the application created earlier.
Now we can create the fencing agent resource using previous values and your subscription ID:
sudo crm configure primitive fence-vm stonith:fence_azure_arm \
params \
action=reboot \
resourceGroup="resourcegroupname" \
resourceGroup="$resourceGroup" \
username="$secretId" \
login="$applicationId" \
passwd="$password" \
tenantId="$tenantId" \
subscriptionId="$subscriptionId" \
pcmk_reboot_timeout=900 \
power_timeout=60 \
op monitor \
interval=3600 \
timeout=120
Set the fencing agent properties
Run the following commands to set the fencing agent properties:
sudo crm configure property cluster-recheck-interval=2min
sudo crm configure property start-failure-is-fatal=true
sudo crm configure property stonith-timeout=900
sudo crm configure property concurrent-fencing=true
sudo crm configure property stonith-enabled=true
And confirm the cluster status:
sudo crm status
The output looks similar to the following example:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 1 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* fence-vm (stonith:fence_azure_arm): Started ubuntu1
Install SQL Server and mssql-tools
The following commands are used to install SQL Server:
Import the public repository GPG keys:
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.ascRegister the Ubuntu repository:
sudo add-apt-repository "$(wget -qO- https://packages.microsoft.com/config/ubuntu/20.04/mssql-server-2022.list)"Run the following commands to install SQL Server:
sudo apt-get update sudo apt-get install -y mssql-serverAfter the package installation finishes, run
mssql-conf setupand follow the prompts to set the SA password and choose your edition. As a reminder, the following editions are freely licensed: Evaluation, Developer, and Express.sudo /opt/mssql/bin/mssql-conf setupOnce the configuration is done, verify that the service is running:
systemctl status mssql-server --no-pagerInstall the SQL Server command-line tools
To create a database, you need to connect with a tool that can run Transact-SQL statements on SQL Server. The following steps install the SQL Server command-line tools: sqlcmd and bcp.
Use the following steps to install the mssql-tools18 on Ubuntu.
Note
- Ubuntu 18.04 is supported starting with SQL Server 2019 CU 3.
- Ubuntu 20.04 is supported starting with SQL Server 2019 CU 10.
- Ubuntu 22.04 is supported starting with SQL Server 2022 CU 10.
Enter superuser mode.
sudo suImport the public repository GPG keys.
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.ascRegister the Microsoft Ubuntu repository.
For Ubuntu 22.04, use the following command:
curl https://packages.microsoft.com/config/ubuntu/22.04/prod.list > /etc/apt/sources.list.d/mssql-release.listFor Ubuntu 20.04, use the following command:
curl https://packages.microsoft.com/config/ubuntu/20.04/prod.list > /etc/apt/sources.list.d/mssql-release.listFor Ubuntu 18.04, use the following command:
curl https://packages.microsoft.com/config/ubuntu/18.04/prod.list > /etc/apt/sources.list.d/mssql-release.listFor Ubuntu 16.04, use the following command:
curl https://packages.microsoft.com/config/ubuntu/16.04/prod.list > /etc/apt/sources.list.d/mssql-release.list
Exit superuser mode.
exitUpdate the sources list and run the installation command with the unixODBC developer package.
sudo apt-get update sudo apt-get install mssql-tools18 unixodbc-devNote
To update to the latest version of mssql-tools, run the following commands:
sudo apt-get update sudo apt-get install mssql-tools18Optional: Add
/opt/mssql-tools18/bin/to yourPATHenvironment variable in a bash shell.To make sqlcmd and bcp accessible from the bash shell for login sessions, modify your
PATHin the~/.bash_profilefile with the following command:echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bash_profileTo make sqlcmd and bcp accessible from the bash shell for interactive/non-login sessions, modify the
PATHin the~/.bashrcfile with the following command:echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bashrc source ~/.bashrc
Install SQL Server high availability agent
Run the following command on all nodes to install the high availability agent package for SQL Server:
sudo apt-get install mssql-server-ha
Configure an availability group
Use the following steps to configure a SQL Server Always On availability group for your VMs. For more information, see Configure SQL Server Always On availability groups for high availability on Linux.
Enable availability groups and restart SQL Server
Enable availability groups on each node that hosts a SQL Server instance. Then restart the mssql-server service. Run the following commands on each node:
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Create a certificate
Microsoft doesn't support Active Directory authentication to the AG endpoint. Therefore, you must use a certificate for AG endpoint encryption.
Connect to all nodes using SQL Server Management Studio (SSMS) or sqlcmd. Run the following commands to enable an AlwaysOn_health session and create a master key:
Important
If you're connecting remotely to your SQL Server instance, you'll need to have port 1433 open on your firewall. You'll also need to allow inbound connections to port 1433 in your NSG for each VM. For more information, see Create a security rule for creating an inbound security rule.
- Replace the
<MasterKeyPassword>with your own password.
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE = ON); GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<MasterKeyPassword>'; GO- Replace the
Connect to the primary replica using SSMS or sqlcmd. The below commands create a certificate at
/var/opt/mssql/data/dbm_certificate.cerand a private key atvar/opt/mssql/data/dbm_certificate.pvkon your primary SQL Server replica:- Replace the
<PrivateKeyPassword>with your own password.
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; GO BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO- Replace the
Exit the sqlcmd session by running the exit command, and return back to your SSH session.
Copy the certificate to the secondary replicas and create the certificates on the server
Copy the two files that were created to the same location on all servers that will host availability replicas.
On the primary server, run the following
scpcommand to copy the certificate to the target servers:- Replace
<username>andsles2with the user name and target VM name that you're using. - Run this command for all secondary replicas.
Note
You don't have to run
sudo -i, which gives you the root environment. You can run thesudocommand in front of each command instead.# The below command allows you to run commands in the root environment sudo -iscp /var/opt/mssql/data/dbm_certificate.* <username>@sles2:/home/<username>- Replace
On the target server, run the following command:
- Replace
<username>with your user name. - The
mvcommand moves the files or directory from one place to another. - The
chowncommand is used to change the owner and group of files, directories, or links. - Run these commands for all secondary replicas.
sudo -i mv /home/<username>/dbm_certificate.* /var/opt/mssql/data/ cd /var/opt/mssql/data chown mssql:mssql dbm_certificate.*- Replace
The following Transact-SQL script creates a certificate from the backup that you created on the primary SQL Server replica. Update the script with strong passwords. The decryption password is the same password that you used to create the .pvk file in the previous step. To create the certificate, run the following script using sqlcmd or SSMS on all secondary servers:
CREATE CERTIFICATE dbm_certificate FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO
Create the database mirroring endpoints on all replicas
Run the following script on all SQL Server instances using sqlcmd or SSMS:
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
GO
Create the availability group
Connect to the SQL Server instance that hosts the primary replica using sqlcmd or SSMS. Run the following command to create the availability group:
- Replace
ag1with your desired AG name. - Replace the
ubuntu1,ubuntu2, andubuntu3values with the names of the SQL Server instances that host the replicas.
CREATE AVAILABILITY
GROUP [ag1]
WITH (
DB_FAILOVER = ON,
CLUSTER_TYPE = EXTERNAL
)
FOR REPLICA
ON N'ubuntu1'
WITH (
ENDPOINT_URL = N'tcp://ubuntu1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'ubuntu2'
WITH (
ENDPOINT_URL = N'tcp://ubuntu2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'ubuntu3'
WITH (
ENDPOINT_URL = N'tcp://ubuntu3:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
Create a SQL Server login for Pacemaker
On all SQL Server instances, create a SQL Server login for Pacemaker. The following Transact-SQL creates a login.
- Replace
<password>with your own complex password.
USE [master]
GO
CREATE LOGIN [pacemakerLogin]
WITH PASSWORD = N'<password>';
GO
ALTER SERVER ROLE [sysadmin]
ADD MEMBER [pacemakerLogin];
GO
On all SQL Server instances, save the credentials used for the SQL Server login.
Create the file:
sudo vi /var/opt/mssql/secrets/passwdAdd the following two lines to the file:
pacemakerLogin <password>To exit the vi editor, first hit the Esc key, and then enter the command
:wqto write the file and quit.Make the file only readable by root:
sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 400 /var/opt/mssql/secrets/passwd
Join secondary replicas to the availability group
On your secondary replicas, run the following commands to join them to the AG:
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GORun the following Transact-SQL script on the primary replica and each secondary replica:
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemakerLogin; GO GRANT VIEW SERVER STATE TO pacemakerLogin; GOOnce the secondary replicas are joined, you can see them in SSMS Object Explorer by expanding the Always On High Availability node:
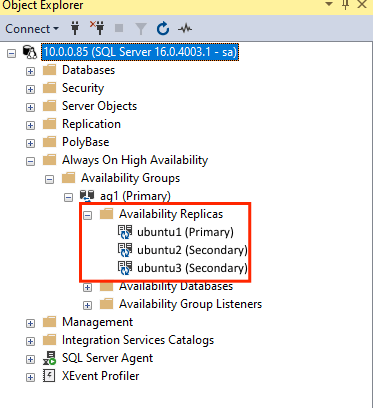
Add a database to the availability group
This section follows the article for adding a database to an availability group.
The following Transact-SQL commands are used in this step. Run these commands on the primary replica:
CREATE DATABASE [db1]; -- creates a database named db1
GO
ALTER DATABASE [db1] SET RECOVERY FULL; -- set the database in full recovery mode
GO
BACKUP DATABASE [db1] -- backs up the database to disk
TO DISK = N'/var/opt/mssql/data/db1.bak';
GO
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1]; -- adds the database db1 to the AG
GO
Verify that the database is created on the secondary servers
On each secondary SQL Server replica, run the following query to see if the db1 database was created and is in a SYNCHRONIZED state:
SELECT * FROM sys.databases
WHERE name = 'db1';
GO
SELECT DB_NAME(database_id) AS 'database',
synchronization_state_desc
FROM sys.dm_hadr_database_replica_states;
GO
If the synchronization_state_desc lists SYNCHRONIZED for db1, this means the replicas are synchronized. The secondaries are showing db1 in the primary replica.
Create availability group resources in Pacemaker cluster
To create the availability group resource in Pacemaker, Run the following commands:
sudo crm
configure
primitive ag1_cluster \
ocf:mssql:ag \
params ag_name="ag1" \
meta failure-timeout=60s \
op start timeout=60s \
op stop timeout=60s \
op promote timeout=60s \
op demote timeout=10s \
op monitor timeout=60s interval=10s \
op monitor timeout=60s on-fail=demote interval=11s role="Master" \
op monitor timeout=60s interval=12s role="Slave" \
op notify timeout=60s
ms ms-ag1 ag1_cluster \
meta master-max="1" master-node-max="1" clone-max="3" \
clone-node-max="1" notify="true"
commit
This above command creates the ag1_cluster resource, that is, the availability group resource. Then it creates ms-ag1 resource (primary/secondary resource in Pacemaker, then adding the AG resource to it. This ensures that AG resource runs on all three nodes in cluster but only one of those nodes is primary.)
To view the AG group resource, and to check status of cluster:
sudo crm resource status ms-ag1
sudo crm status
The output looks similar to the following example:
resource ms-ag1 is running on: ubuntu1 Master
resource ms-ag1 is running on: ubuntu3
resource ms-ag1 is running on: ubuntu2
The output looks similar to the following example. To add colocation and promotion constraints, see Tutorial: Configure an availability group listener on Linux virtual machines.
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 4 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* Clone Set: ms-ag1 [ag1_cluster] (promotable):
* Masters: [ ubuntu1 ]
* Slaves : [ ubuntu2 ubuntu3 ]
* fence-vm (stonith:fence_azure_arm): Started ubuntu1
Run the following command to create a group resource, so that the colocation and promotion constraints applied to the listener and load balancer don't have to be applied individually.
sudo crm configure group virtualip-group azure-load-balancer virtualip
The output of crm status will look similar to the following example:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 6 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* Clone Set: ms-ag1 [ag1_cluster] (promotable):
* Masters: [ ubuntu1 ]
* Slaves : [ ubuntu2 ubuntu3 ]
* Resource Group: virtual ip-group:
* azure-load-balancer (ocf :: heartbeat:azure-lb): Started ubuntu1
* virtualip (ocf :: heartbeat: IPaddr2): Started ubuntu1
* fence-vm (stonith:fence_azure_arm): Started ubuntu1