Derived column transformation in mapping data flow
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
Data flows are available both in Azure Data Factory and Azure Synapse Pipelines. This article applies to mapping data flows. If you are new to transformations, please refer to the introductory article Transform data using a mapping data flow.
Use the derived column transformation to generate new columns in your data flow or to modify existing fields.
Create and update columns
When creating a derived column, you can either generate a new column or update an existing one. In the Column textbox, enter in the column you are creating. To override an existing column in your schema, you can use the column dropdown. To build the derived column's expression, click on the Enter expression textbox. You can either start typing your expression or open up the expression builder to construct your logic.
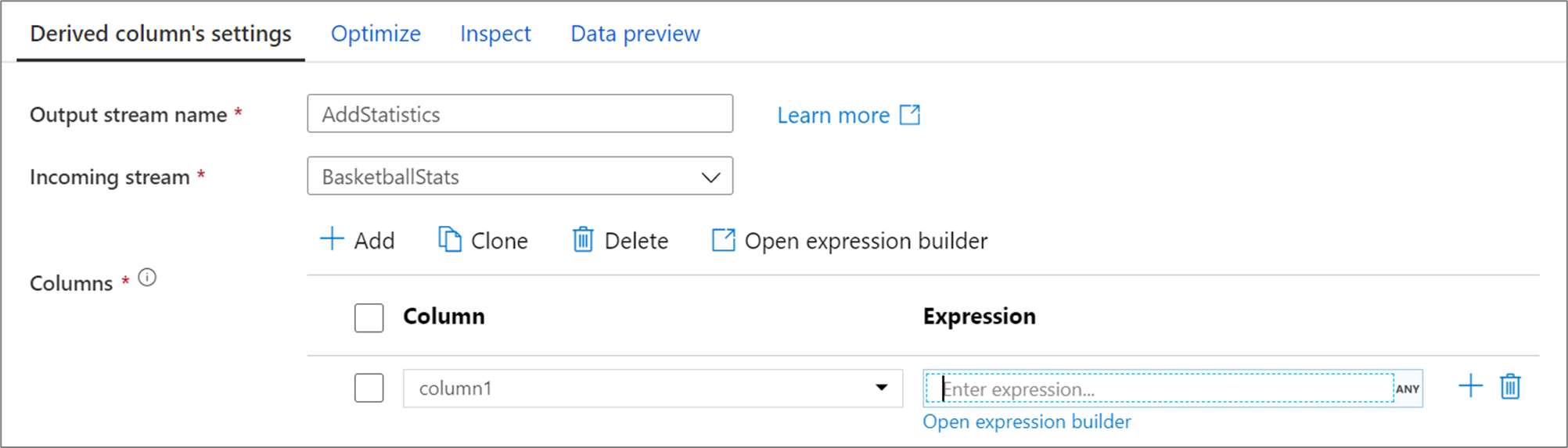
To add more derived columns, click on Add above the column list or the plus icon next to an existing derived column. Choose either Add column or Add column pattern.
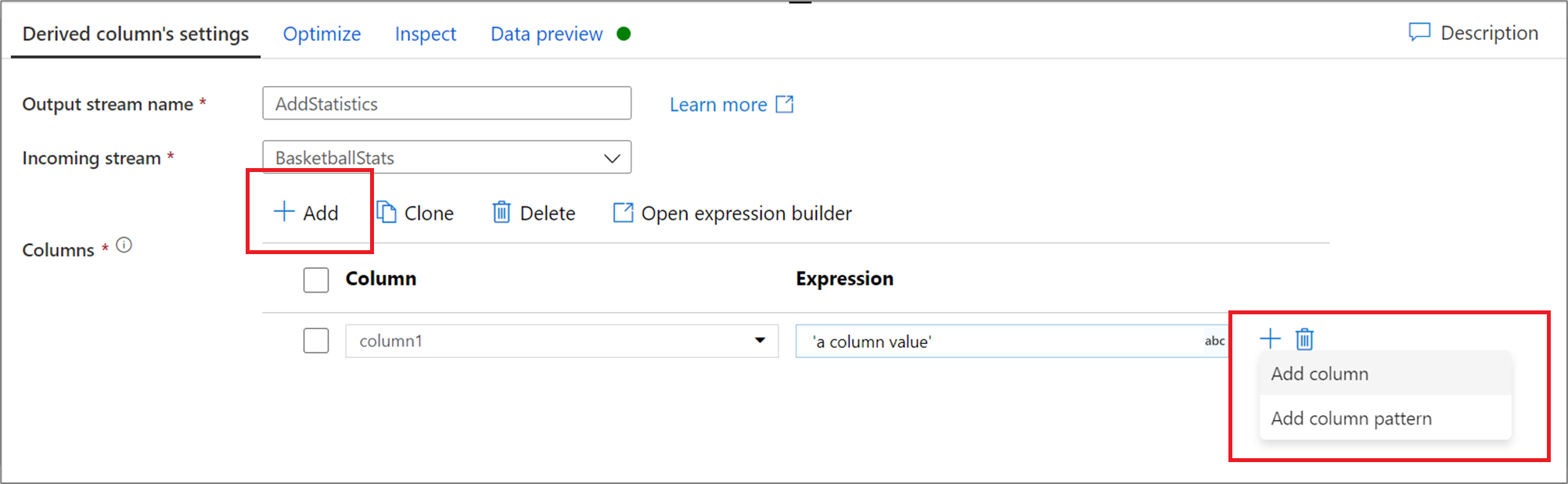
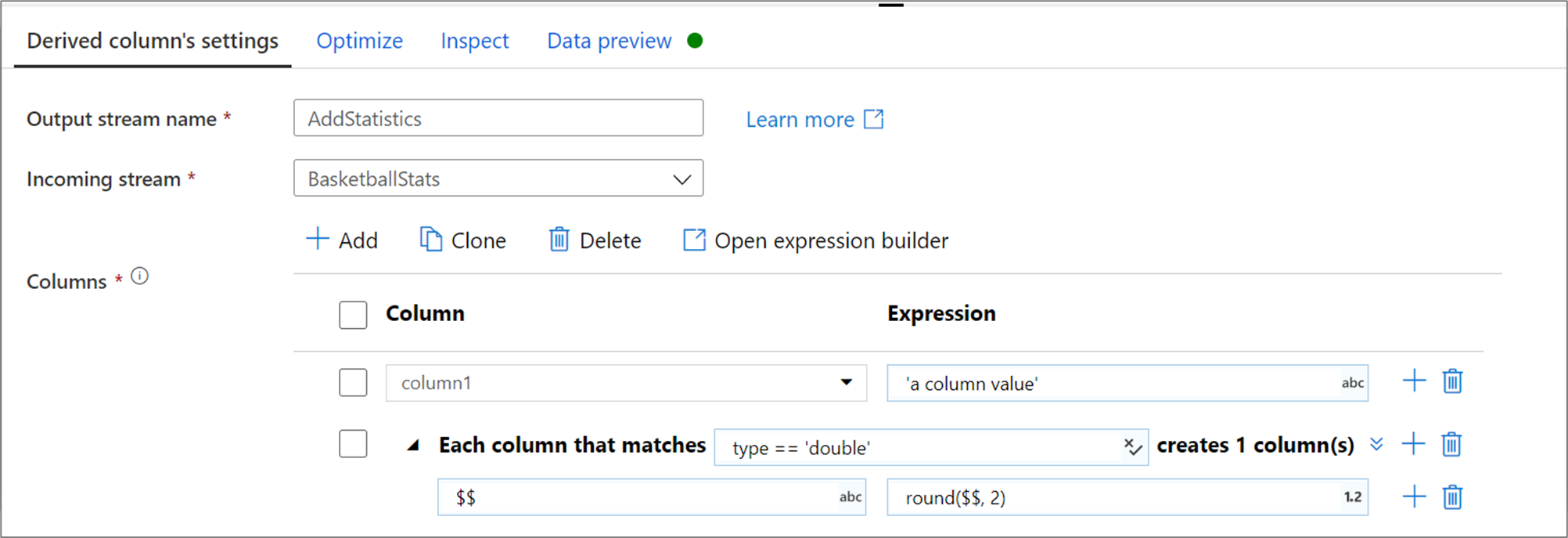
Column patterns
In cases where your schema is not explicitly defined or if you want to update a set of columns in bulk, you will want to create column patterns. Column patterns allow for you to match columns using rules based upon the column metadata and create derived columns for each matched column. For more information, learn how to build column patterns in the derived column transformation.
Building schemas using the expression builder
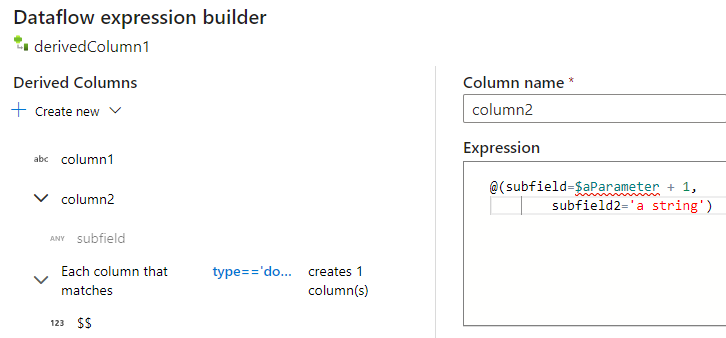
When using the mapping data flow expression builder, you can create, edit, and manage your derived columns in the Derived Columns section. All columns that are created or changed in the transformation are listed. Interactively choose which column or pattern you are editing by clicking on the column name. To add an additional column select Create new and choose whether you wish to add a single column or a pattern.
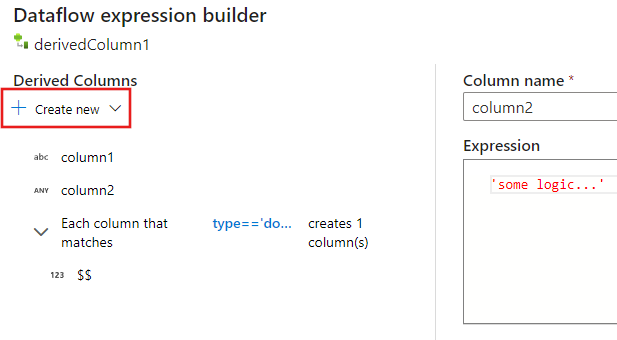
When working with complex columns, you can create subcolumns. To do this, click on the plus icon next to any column and select Add subcolumn. For more information on handling complex types in data flow, see JSON handling in mapping data flow.
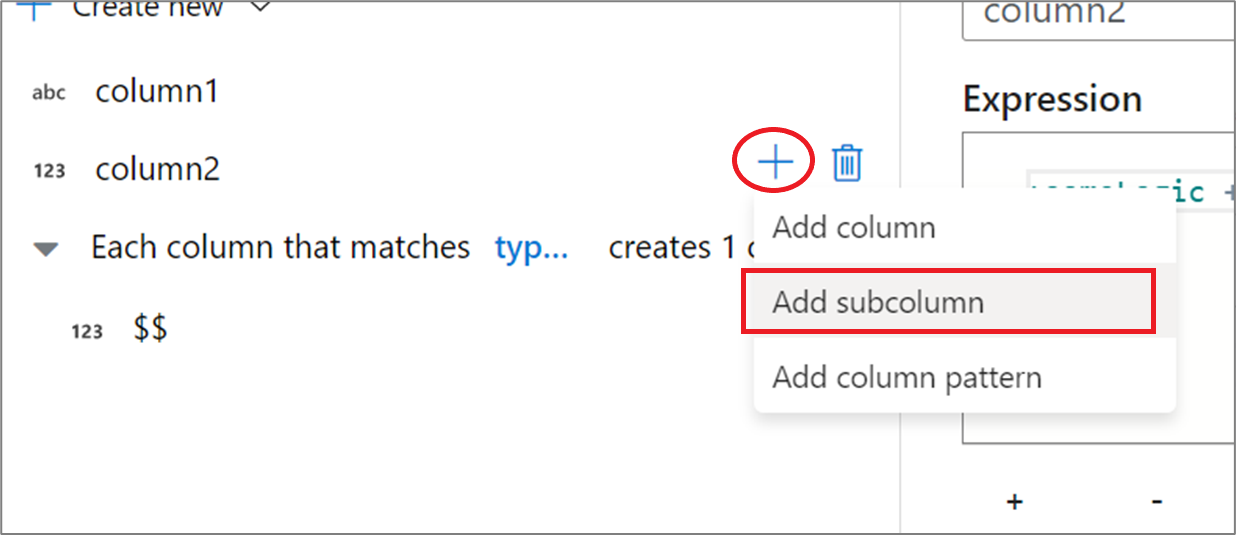
For more information on handling complex types in data flow, see JSON handling in mapping data flow.
Data flow script
Syntax
<incomingStream>
derive(
<columnName1> = <expression1>,
<columnName2> = <expression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <deriveTransformationName>
Example
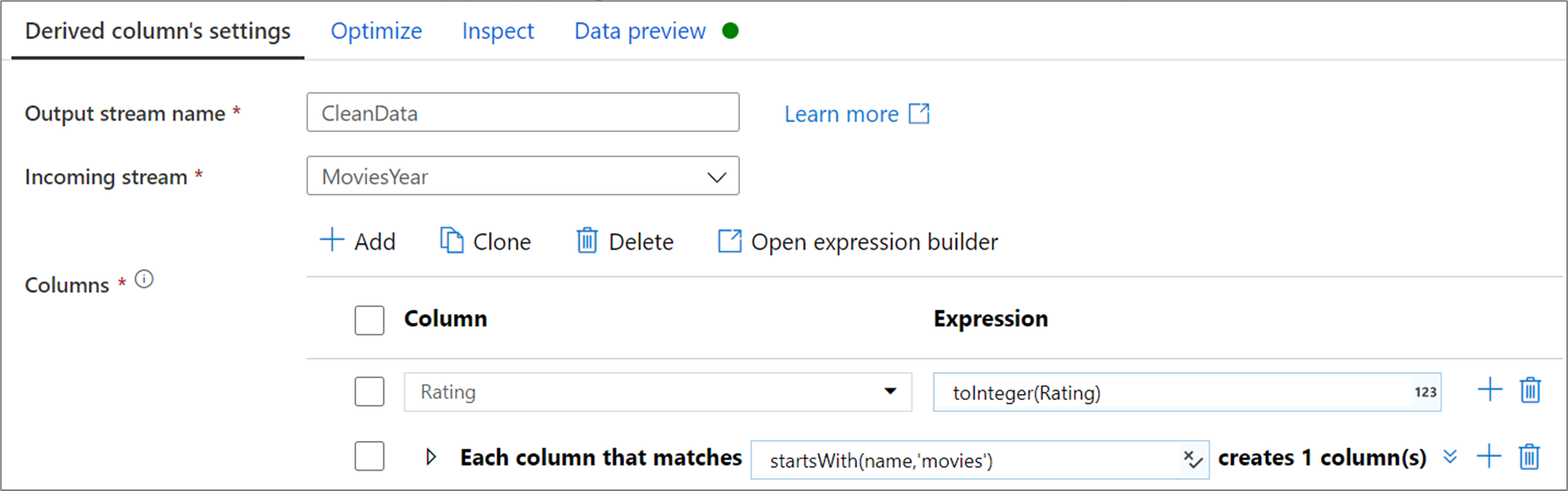
The below example is a derived column named CleanData that takes an incoming stream MoviesYear and creates two derived columns. The first derived column replaces column Rating with Rating's value as an integer type. The second derived column is a pattern that matches each column whose name starts with 'movies'. For each matched column, it creates a column movie that is equal to the value of the matched column prefixed with 'movie_'.
In the UI, this transformation looks like the below image:
The data flow script for this transformation is in the snippet below:
MoviesYear derive(
Rating = toInteger(Rating),
each(
match(startsWith(name,'movies')),
'movie' = 'movie_' + toString($$)
)
) ~> CleanData
Related content
- Learn more about the Mapping Data Flow expression language.