Migrate HDInsight cluster to a newer version
To take advantage of the latest HDInsight features, we recommend that HDInsight clusters be regularly migrated to latest version. HDInsight doesn't support in-place upgrades where an existing cluster is upgraded to a newer component version. You must create a new cluster with the desired component and platform version and then migrate your applications to use the new cluster. Follow the below guidelines to migrate your HDInsight cluster versions.
Note
If you are creating a Hive cluster with a primary storage container, copy it from an existing HDInsight cluster. Don'tt copy the complete content. Copy only the data folders which are configured.
Migration tasks
The workflow to upgrade HDInsight Cluster is as follows.
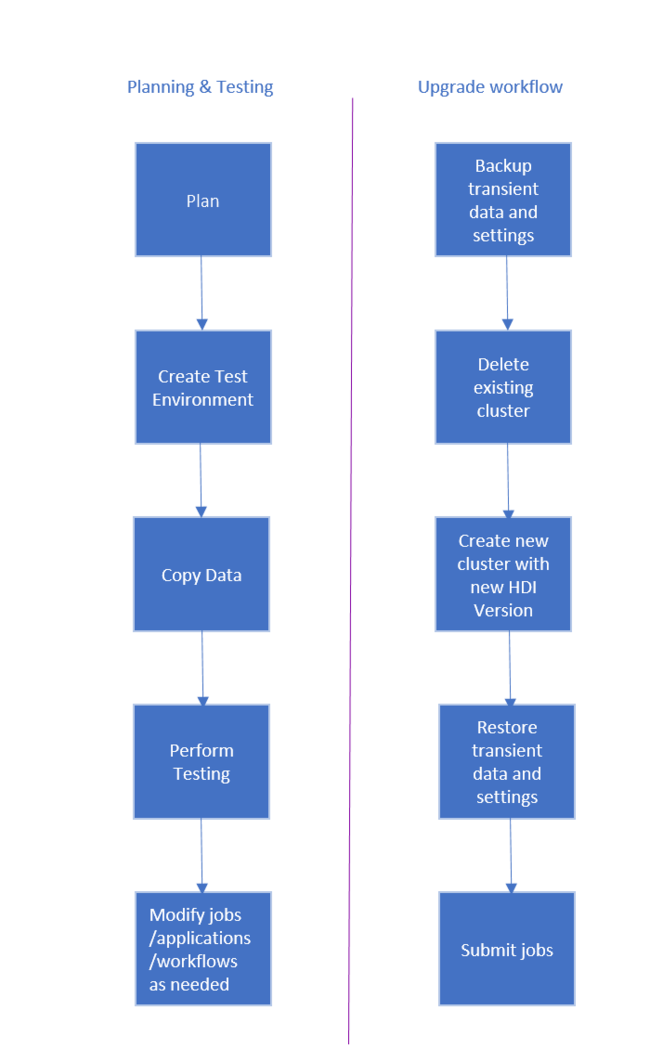
- Read each section of this document to understand changes that may be required when upgrading your HDInsight cluster.
- Create a cluster as a test/quality assurance environment. For more information on creating a cluster, see Learn how to create Linux-based HDInsight clusters
- Copy existing jobs, data sources, and sinks to the new environment.
- Perform validation testing to make sure that your jobs work as expected on the new cluster.
Once you've verified that everything works as expected, schedule downtime for the migration. During this downtime, do the following actions:
- Back up any transient data stored locally on the cluster nodes. For example, if you've data stored directly on a head node.
- Delete the existing cluster.
- Create a cluster in the same VNET subnet with latest (or supported) HDI version using the same default data store that the previous cluster used. This allows the new cluster to continue working against your existing production data.
- Import any transient data you backed up.
- Start jobs/continue processing using the new cluster.
Workload specific guidance
The following documents provide guidance on how to migrate specific workloads:
Back up and restore
For more information about database backup and restore, see Recover a database in Azure SQL Database by using automated database backups.
Upgrade scenarios
As mentioned above, Microsoft recommends that HDInsight clusters be regularly migrated to the latest version in order to take advantage of new features and fixes. See the following list of reasons we would request that a cluster to be deleted and redeployed:
- The cluster version is Retired or if you're having a cluster issue that would be resolved with a newer version.
- The root cause of a cluster issue is determined to relate an undersized VM. View Microsoft's recommended node configuration.
- A customer opens a support case and the Microsoft engineering team determines the issue has already been fixed in a newer cluster version.
- A default metastore database (Ambari, Hive, Oozie, Ranger) has reached its utilization limit. Microsoft asks you to recreate the cluster using a custom metastore database.
- The root cause of a cluster issue is due to an Unsupported Operation. Here are some of the common unsupported operations:
- Moving or Adding a service in Ambari. See the information on the cluster services in Ambari, one of the actions available from the Service Actions menu is Move [Service Name]. Another action is Add [Service Name]. Both of these options are unsupported.
- Python package corruption. HDInsight clusters depend on the built-in Python environments, Python 2.7 and Python 3.5. Directly installing custom packages in those default built-in environments may cause unexpected library version changes and break the cluster. Learn how to safely install custom external Python packages for your Spark applications.
- Third-party software. Customers have the ability to install third-party software on their HDInsight clusters; however, we'll recommend recreating the cluster if it breaks the existing functionality.
- Multiple workloads on the same cluster. In HDInsight 4.0, the Hive Warehouse Connector needs separate clusters for Spark and Interactive Query workloads. Follow these steps to set up both clusters in Azure HDInsight. Similarly, integrating Spark with HBASE requires two different clusters.
- Custom Ambari DB password changed. The Ambari DB password is set during cluster creation and there's no current mechanism to update it. If a customer deploys the cluster with a custom Ambari DB, they have the ability to change the DB password on the SQL DB; however, there's no way to update this password for a running HDInsight cluster.
- Modifying HDInsight Load Balancers. The HDInsight load balancers that are automatically deployed for Ambari and SSH access should not be modified or deleted. If you modify the HDInsight load balancer(s) and it breaks the cluster functionality, you will be advised to redeploy the cluster.
- Reusing Ranger 4.X Databases in 5.X. HDInsight 5.1 has Apache Ranger version 2.3.0 which is major version upgrade from 1.2.0 in HDInsight 4.X clusters. Reuse of an HDInsight 4.X Ranger database in HDInsight 5.1 would prevent the Ranger service from starting due to differences in the DB schema. You would need to create an empty Ranger database to successfully deploy HDInsight 5.1 ESP clusters.