IoT Hub high availability and disaster recovery
As a first step towards implementing a resilient IoT solution, architects, developers, and business owners must define the uptime goals for the solutions they're building. These goals can be defined primarily based on specific business objectives for each scenario. In this context, the article Azure Business Continuity Technical Guidance describes a general framework to help you think about business continuity and disaster recovery. The Disaster recovery and high availability for Azure applications paper provides architecture guidance on strategies for Azure applications to achieve High Availability (HA) and Disaster Recovery (DR).
This article discusses the HA and DR features offered specifically by the IoT Hub service. The broad areas discussed in this article are:
- Intra-region HA
- Cross region DR
- Achieving cross region HA
Depending on the uptime goals you define for your IoT solutions, you should determine which of the options outlined in this article best suit your business objectives. Incorporating any of these HA/DR alternatives into your IoT solution requires a careful evaluation of the trade-offs between the:
- Level of resiliency you require
- Implementation and maintenance complexity
- COGS impact
Intra-region HA
The IoT Hub service provides intra-region HA by implementing redundancies in almost all layers of the service. The SLA published by the IoT Hub service is achieved by making use of these redundancies. No extra work is required by the developers of an IoT solution to take advantage of these HA features. Although IoT Hub offers a reasonably high uptime guarantee, transient failures can still be expected as with any distributed computing platform. If you're just getting started with migrating your solutions to the cloud from an on-premises solution, your focus needs to shift from optimizing "mean time between failures" to "mean time to recover". In other words, transient failures are to be considered normal while operating with the cloud in the mix. Appropriate retry patterns must be built in to the components interacting with a cloud application to deal with transient failures.
Availability zones
IoT Hub supports Azure availability zones. An availability zone is a high-availability offering that protects your applications and data from datacenter failures. A region with availability zone support comprises three zones supporting that region. Each zone provides one or more datacenters, each in a unique physical location with independent power, cooling, and networking. This configuration provides replication and redundancy within the region.
Availability zones provide two advantages: data resiliency and smoother deployments.
Data resiliency comes from replacing the underlying storage services with availability-zones-supported storage. Data resilience is important for IoT solutions because these solutions often operate in complex, dynamic, and uncertain environments where failures or disruptions can have significant consequences. Whether an IoT solution supports a manufacturing floor, retail or restaurant environments, healthcare systems, or infrastructure, the availability and quality of data is necessary to recover from failures and to provide reliable and consistent services.
Smoother deployments come from replacing the underlying data center hardware with newer hardware that supports availability zones. These hardware improvements minimize customer impact from device disconnects and reconnects as well as other deployment-related downtime. The IoT Hub engineering team deploys multiple updates to each IoT hub ever month, for both security reasons and to provide feature improvements. Availability-zones-supported hardware is split into 15 update domains so that each update goes smoother, with minimal impact to your workflows. For more information about update domains, see Availability sets.
Availability zone support for IoT Hub is enabled automatically for new IoT Hub resources created in the following Azure regions:
| Region | Data resiliency | Smoother deployments |
|---|---|---|
| Australia East | ||
| Brazil South | ||
| Canada Central | ||
| Central India | ||
| Central US | ||
| East US | ||
| France Central | ||
| Germany West Central | ||
| Japan East | ||
| Korea Central | ||
| North Europe | ||
| Norway East | ||
| Qatar Central | ||
| Southcentral US | ||
| Southeast Asia | ||
| UK South | ||
| West Europe | ||
| West US 2 | ||
| West US 3 |
Cross region DR
There could be some rare situations when a datacenter experiences extended outages due to power failures or other failures involving physical assets. Such events are rare during which the intra region HA capability described previously may not always help. IoT Hub provides multiple solutions for recovering from such extended outages.
The recovery options available to customers in such a situation are Microsoft-initiated failover and manual failover. The fundamental difference between the two is that Microsoft initiates the former and the user initiates the latter. Also, manual failover provides a lower recovery time objective (RTO) compared to the Microsoft-initiated failover option. The specific RTOs offered with each option are discussed in the following sections. When either of these options to perform failover of an IoT hub from its primary region is exercised, the hub becomes fully functional in the corresponding Azure geo-paired region.
Both these failover options offer the following recovery point objectives (RPOs):
| Data type | Recovery point objectives (RPO) |
|---|---|
| Identity registry | 0-5 mins data loss |
| Device twin data | 0-5 mins data loss |
| Cloud-to-device messages1 | 0-5 mins data loss |
| Parent1 and device jobs | 0-5 mins data loss |
| Device-to-cloud messages | All unread messages are lost |
| Cloud-to-device feedback messages | All unread messages are lost |
1Cloud-to-device messages and parent jobs aren't recovered as a part of manual failover.
Once the failover operation for the IoT hub completes, all operations from the device and back-end applications are expected to continue working without requiring a manual intervention. This means that your device-to-cloud messages should continue to work, and the entire device registry is intact. Events emitted via Event Grid can be consumed via the same subscription(s) configured earlier as long as those Event Grid subscriptions continue to be available. No additional handling is required for custom endpoints.
Caution
- The Event Hubs-compatible name and endpoint of the IoT Hub built-in events endpoint change after failover. When receiving telemetry messages from the built-in endpoint using either the Event Hubs client or event processor host, you should use the IoT hub connection string to establish the connection. This ensures that your back-end applications continue to work without requiring manual intervention post failover. If you use the Event Hub-compatible name and endpoint in your application directly, you will need to fetch the new Event Hub-compatible endpoint after failover to continue operations. For more information, see Manual failover and Event Hub.
- If you use Azure Functions or Azure Stream Analytics to connect the built-in Events endpoint, you might need to perform a Restart. This is because during failover previous offsets are no longer valid.
- When routing to storage, we recommend listing the blobs or files and then iterating over them, to ensure all blobs or files are read without making any assumptions of partition. The partition range could potentially change during a Microsoft-initiated failover or manual failover. You can use the List Blobs API to enumerate the list of blobs or List ADLS Gen2 API for the list of files. To learn more, see Azure Storage as a routing endpoint.
Microsoft-initiated failover
Microsoft-initiated failover is exercised by Microsoft in rare situations to fail over all the IoT hubs from an affected region to the corresponding geo-paired region. This process is a default option and requires no intervention from the user. Microsoft reserves the right to make a determination of when this option will be exercised. This mechanism doesn't involve a user consent before the user's hub is failed over. Microsoft-initiated failover has a recovery time objective (RTO) of 2-26 hours.
The large RTO is because Microsoft must perform the failover operation on behalf of all the affected customers in that region. If you're running a less critical IoT solution that can sustain a downtime of roughly a day, it's ok for you to take a dependency on this option to satisfy the overall disaster recovery goals for your IoT solution. The total time for runtime operations to become fully operational once this process is triggered, is described in the "Time to recover" section.
Only users deploying IoT hubs to the Brazil South and Southeast Asia (Singapore) regions can opt out of this feature. For more information, see Disable disaster recovery.
Note
Azure IoT Hub doesn't store or process customer data outside of the geography where you deploy the service instance. For more information, see Cross-region replication in Azure.
Manual failover
If your business uptime goals aren't satisfied by the RTO that Microsoft initiated failover provides, consider using manual failover to trigger the failover process yourself. The RTO using this option could be anywhere between 10 minutes to a couple of hours. The RTO is currently a function of the number of devices registered against the IoT hub instance being failed over. You can expect the RTO for a hub hosting approximately 100,000 devices to be in the ballpark of 15 minutes. The total time for runtime operations to become fully operational once this process is triggered, is described in the "Time to recover" section.
The manual failover option is always available for use irrespective of whether the primary region is experiencing downtime or not. Therefore, this option could potentially be used to perform planned failovers. One example usage of planned failovers is to perform periodic failover drills. A word of caution though is that a planned failover operation results in a downtime for the hub for the period defined by the RTO for this option, and also results in a data loss as defined by the RPO table above. You could consider setting up a test IoT hub instance to exercise the planned failover option periodically to gain confidence in your ability to get your end-to-end solutions up and running when a real disaster happens.
Manual failover is available at no additional cost for IoT hubs created after May 18, 2017
For step-by-step instructions, see Tutorial: Perform manual failover for an IoT hub
Manual failover and Event Hubs
The Event Hubs-compatible name and endpoint of the IoT Hub built-in events endpoint change after manual failover. This is because the Event Hubs client doesn't have visibility into IoT Hub events. The same is true for other cloud-based clients such as Functions and Azure Stream Analytics. To retrieve the endpoint and name, you can use the Azure portal or the .NET SDK.
Use the portal
For more information about using the portal to retrieve the Event Hub-compatible endpoint and the Event Hub-compatible name, see Connect to the built-in endpoint.
Use the .NET SDK
To use the IoT Hub connection string to recapture the Event Hubs-compatible endpoint, use a sample located at https://github.com/Azure/azure-sdk-for-net/tree/main/samples/iothub-connect-to-eventhubs. The code example uses the connection string to get the new Event Hubs endpoint and re-establish the connection. You must have Visual Studio installed.
Run test drills
Test drills shouldn't be performed on IoT hubs that are being used in your production environments.
Don't use manual failover to migrate IoT hub to a different region
Manual failover should not be used as a mechanism to permanently migrate your hub between the Azure geo paired regions. Assuming that the devices were located closest to the hub's primary region, latency for operations being performed against the IoT hub will increase when the hub fails over to a secondary region.
Failback
You can fail back to the old primary region by triggering the failover action a second time. If the original failover operation was performed to recover from an extended outage in the original primary region, we recommended that the hub should be failed back to the original location once that location has recovered from the outage situation.
Important
- Users are only allowed to perform 2 successful failover and 2 successful failback operations per day.
- Back to back failover/failback operations are not allowed. You must wait for 1 hour between these operations.
Time to recover
While the FQDN (and therefore the connection string) of the IoT hub instance remains the same post failover, the underlying IP address does change. The time for the runtime operations being performed against your IoT hub instance to become fully operational after the failover process can be expressed using the following function:
Time to recover = RTO [10 min - 2 hours for manual failover | 2 - 26 hours for Microsoft-initiated failover] + DNS propagation delay + Time taken by the client application to refresh any cached IoT Hub IP address.
Important
The IoT SDKs do not cache the IP address of the IoT hub. We recommend that user code interfacing with the SDKs should not cache the IP address of the IoT hub.
Disable disaster recovery
IoT Hub provides Microsoft-Initiated Failover and Manual Failover by replicating data to the paired region for each IoT hub. For some regions, you can avoid data replication outside of the region by disabling disaster recovery when creating an IoT hub. The following regions support this feature:
- Brazil South; paired region, South Central US.
- Southeast Asia (Singapore); paired region, East Asia (Hong Kong SAR).
To disable disaster recovery in supported regions, make sure that Disaster recovery enabled is unselected when you create your IoT hub:
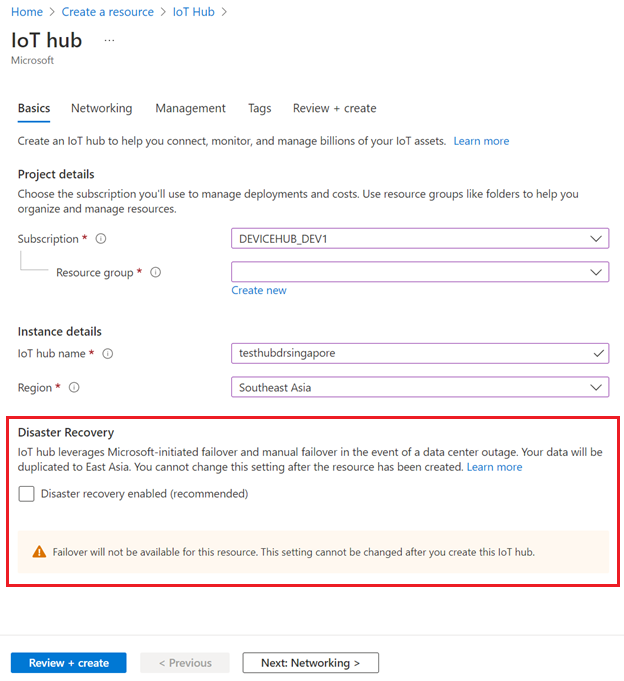
You can also disable disaster recovery when you create an IoT hub using an ARM template.
Failover capability won't be available if you disable disaster recovery for an IoT hub.
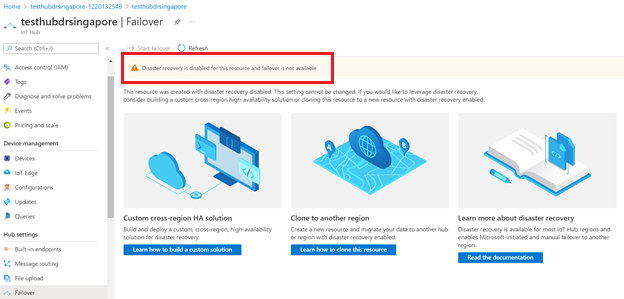
You can only disable disaster recovery to avoid data replication outside of the paired region in Brazil South or Southeast Asia when you create an IoT hub. If you want to configure your existing IoT hub to disable disaster recovery, you need to create a new IoT hub with disaster recovery disabled and manually migrate your existing IoT hub. For guidance, see How to migrate an IoT hub.
Achieve cross region HA
If your business uptime goals aren't satisfied by the RTO that either Microsoft-initiated failover or manual failover options provide, you should consider implementing a per-device automatic cross region failover mechanism. A complete treatment of deployment topologies in IoT solutions is outside the scope of this article. The article discusses the regional failover deployment model for high availability and disaster recovery.
In a regional failover model, the solution back end runs primarily in one datacenter location. A secondary IoT hub and back end are deployed in another datacenter location. If the IoT hub in the primary region suffers an outage or the network connectivity from the device to the primary region is interrupted, devices use a secondary service endpoint. You can improve the solution availability by implementing a cross-region failover model instead of staying within a single region.
At a high level, to implement a regional failover model with IoT Hub, you need to take the following steps:
A secondary IoT hub and device routing logic: If service in your primary region is disrupted, devices must start connecting to your secondary region. Given the state-aware nature of most services involved, it's common for solution administrators to trigger the inter-region failover process. The best way to communicate the new endpoint to devices, while maintaining control of the process, is to have them regularly check a concierge service for the current active endpoint. The concierge service can be a web application that is replicated and kept reachable using DNS-redirection techniques (for example, using Azure Traffic Manager).
Note
IoT hub service is not a supported endpoint type in Azure Traffic Manager. The recommendation is to integrate the proposed concierge service with Azure traffic manager by making it implement the endpoint health probe API.
Identity registry replication: To be usable, the secondary IoT hub must contain all device identities that can connect to the solution. The solution should keep geo-replicated backups of device identities, and upload them to the secondary IoT hub before switching the active endpoint for the devices. The device identity export functionality of IoT Hub is useful in this context. For more information, see IoT Hub developer guide - identity registry.
Merging logic: When the primary region becomes available again, all the state and data that have been created in the secondary site must be migrated back to the primary region. This state and data mostly relate to device identities and application metadata, which must be merged with the primary IoT hub and any other application-specific stores in the primary region.
To simplify this step, you should use idempotent operations. Idempotent operations minimize the side-effects from the eventual consistent distribution of events, and from duplicates or out-of-order delivery of events. In addition, the application logic should be designed to tolerate potential inconsistencies or slightly out-of-date state. This situation can occur due to the extra time it takes for the system to heal based on recovery point objectives (RPO).
Choose the right HA/DR option
Here's a summary of the HA/DR options presented in this article that can be used as a frame of reference to choose the right option that works for your solution.
| HA/DR option | RTO | RPO | Requires manual intervention? | Implementation complexity | Cost impact |
|---|---|---|---|---|---|
| Microsoft-initiated failover | 2 - 26 hours | Refer to the RPO table above | No | None | None |
| Manual failover | 10 min - 2 hours | Refer to the RPO table above | Yes | Very low. You only need to trigger this operation from the portal. | None |
| Cross region HA | < 1 min | Depends on the replication frequency of your custom HA solution | No | High | > 1x the cost of 1 IoT hub |
Next steps
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for