Create and run machine learning pipelines using components with the Azure Machine Learning studio
APPLIES TO:  Azure CLI ml extension v2 (current)
Azure CLI ml extension v2 (current)
In this article, you'll learn how to create and run machine learning pipelines by using the Azure Machine Learning studio and Components. You can create pipelines without using components, but components offer better amount of flexibility and reuse. Azure Machine Learning Pipelines can be defined in YAML and run from the CLI, authored in Python, or composed in Azure Machine Learning studio Designer with a drag-and-drop UI. This document focuses on the Azure Machine Learning studio designer UI.
Prerequisites
If you don't have an Azure subscription, create a free account before you begin. Try the free or paid version of Azure Machine Learning.
An Azure Machine Learning workspace Create workspace resources.
Install and set up the Azure CLI extension for Machine Learning.
Clone the examples repository:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/
Note
Designer supports two types of components, classic prebuilt components(v1) and custom components(v2). These two types of components are NOT compatible.
Classic prebuilt components provide prebuilt components majorly for data processing and traditional machine learning tasks like regression and classification. Classic prebuilt components continue to be supported but won't have any new components added. Also, deployment of classic prebuilt (v1) components doesn't support managed online endpoints (v2).
Custom components allow you to wrap your own code as a component. It supports sharing components across workspaces and seamless authoring across studio, CLI v2, and SDK v2 interfaces.
For new projects, we highly suggest you use custom component, which is compatible with AzureML V2 and will keep receiving new updates.
This article applies to custom components.
Register component in your workspace
To build pipeline using components in UI, you need to register components to your workspace first. You can use UI, CLI or SDK to register components to your workspace, so that you can share and reuse the component within the workspace. Registered components support automatic versioning so you can update the component but assure that pipelines that require an older version continues to work.
The following example uses UI to register components, and the component source files are in the cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components directory of the azureml-examples repository. You need to clone the repo to local first.
- In your Azure Machine Learning workspace, navigate to Components page and select New Component (one of the two style pages will appear).


This example uses train.yml in the directory. The YAML file defines the name, type, interface including inputs and outputs, code, environment and command of this component. The code of this component train.py is under ./train_src folder, which describes the execution logic of this component. To learn more about the component schema, see the command component YAML schema reference.
Note
When register components in UI, code defined in the component YAML file can only point to the current folder where YAML file locates or the subfolders, which means you cannot specify ../ for code as UI cannot recognize the parent directory.
additional_includes can only point to the current or sub folder.
Currently, UI only supports registering components with command type.
- Select Upload from Folder, and select the
1b_e2e_registered_componentsfolder to upload. Selecttrain.ymlfrom the drop-down list.

Select Next in the bottom, and you can confirm the details of this component. Once you've confirmed, select Create to finish the registration process.
Repeat the previous steps to register Score and Eval component using
score.ymlandeval.ymlas well.After registering the three components successfully, you can see your components in the studio UI.

Create pipeline using registered component
Create a new pipeline in the designer. Remember to select the Custom option.

Give the pipeline a meaningful name by selecting the pencil icon besides the autogenerated name.
In designer asset library, you can see Data, Model and Components tabs. Switch to the Components tab, you can see the components registered from previous section. If there are too many components, you can search with the component name.
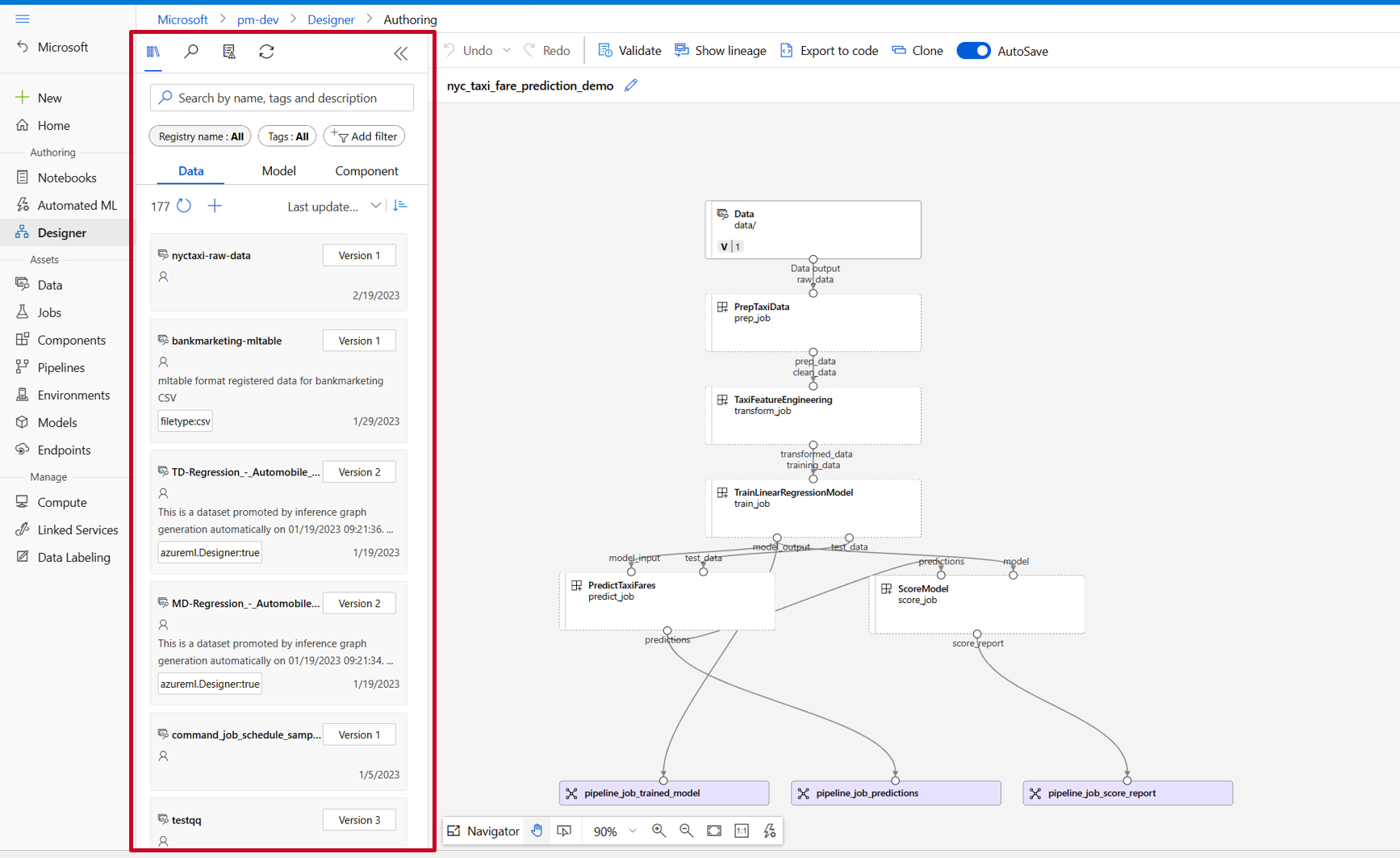
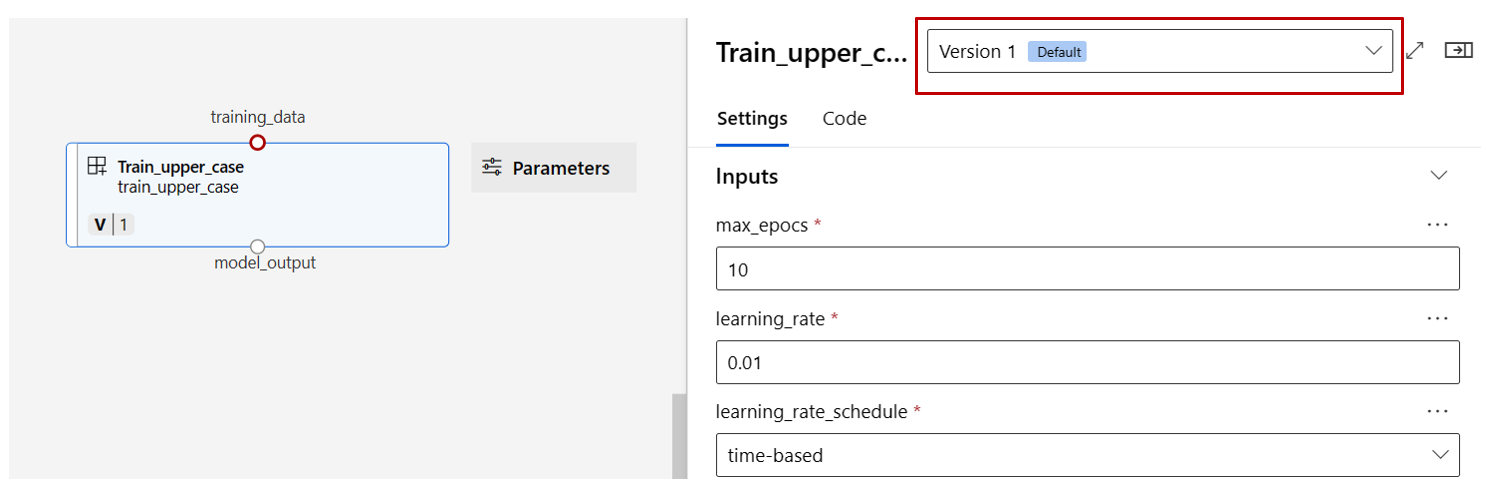
Find the train, score and eval components registered in previous section then drag-and-drop them on the canvas. By default it uses the default version of the component, and you can change to a specific version in the right pane of component. The component right pane is invoked by double click on the component.
In this example, we'll use the sample data under this path. Register the data into your workspace by selecting the add icon in designer asset library -> data tab, set Type = Folder(uri_folder) then follow the wizard to register the data. The data type need to be uri_folder to align with the train component definition.

Then drag and drop the data into the canvas. Your pipeline look should look like the following screenshot now.
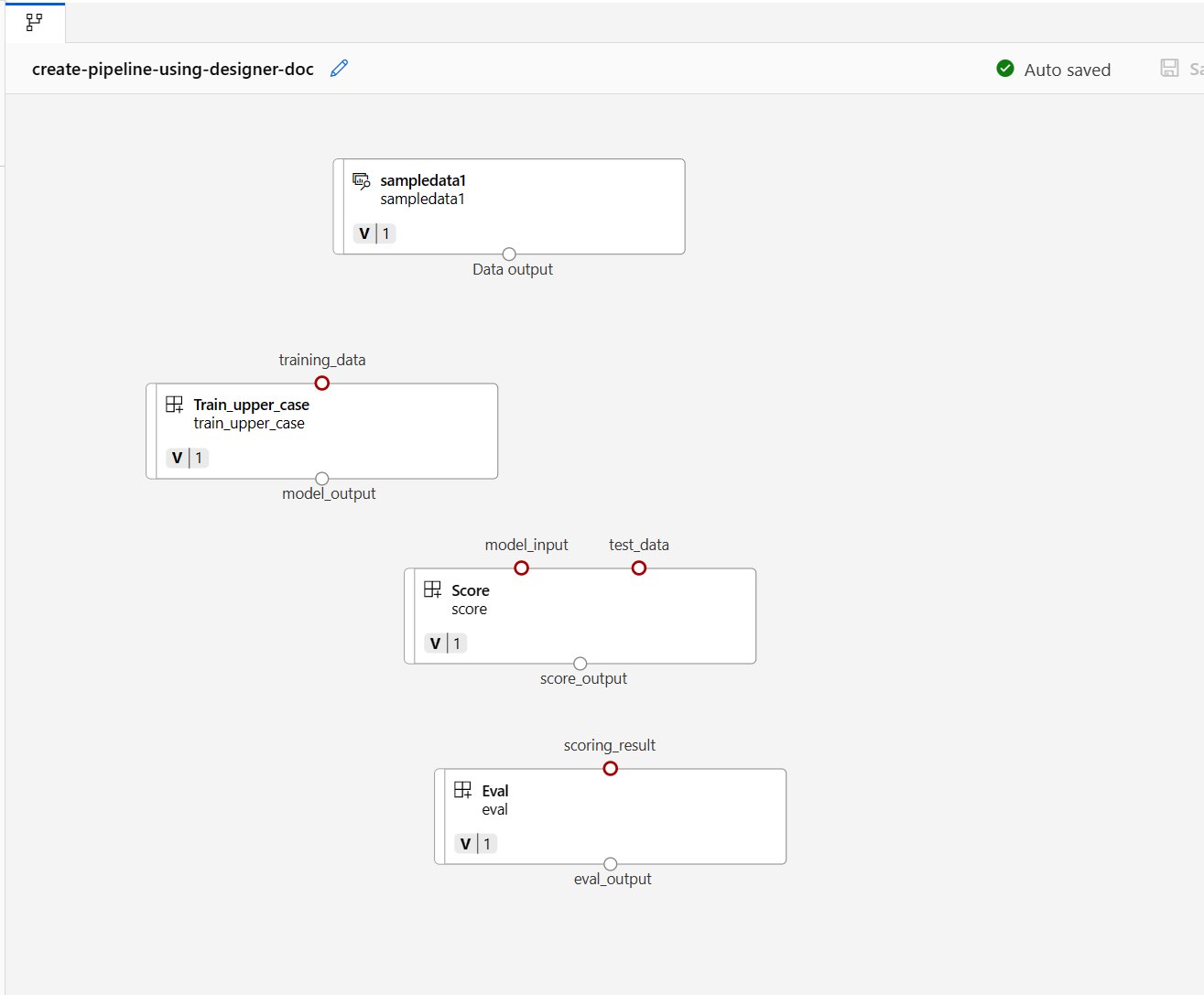
Connect the data and components by dragging connections in the canvas.
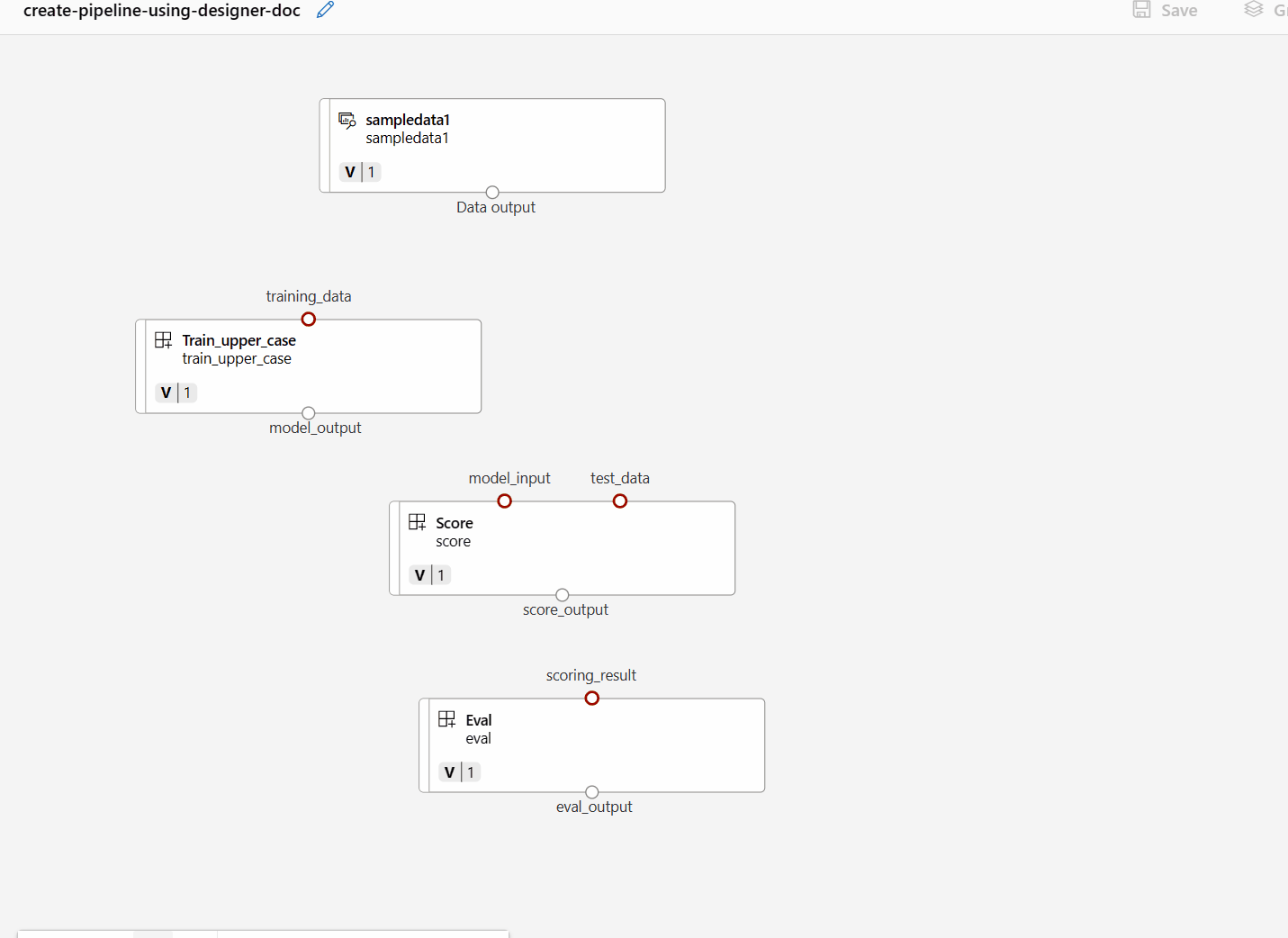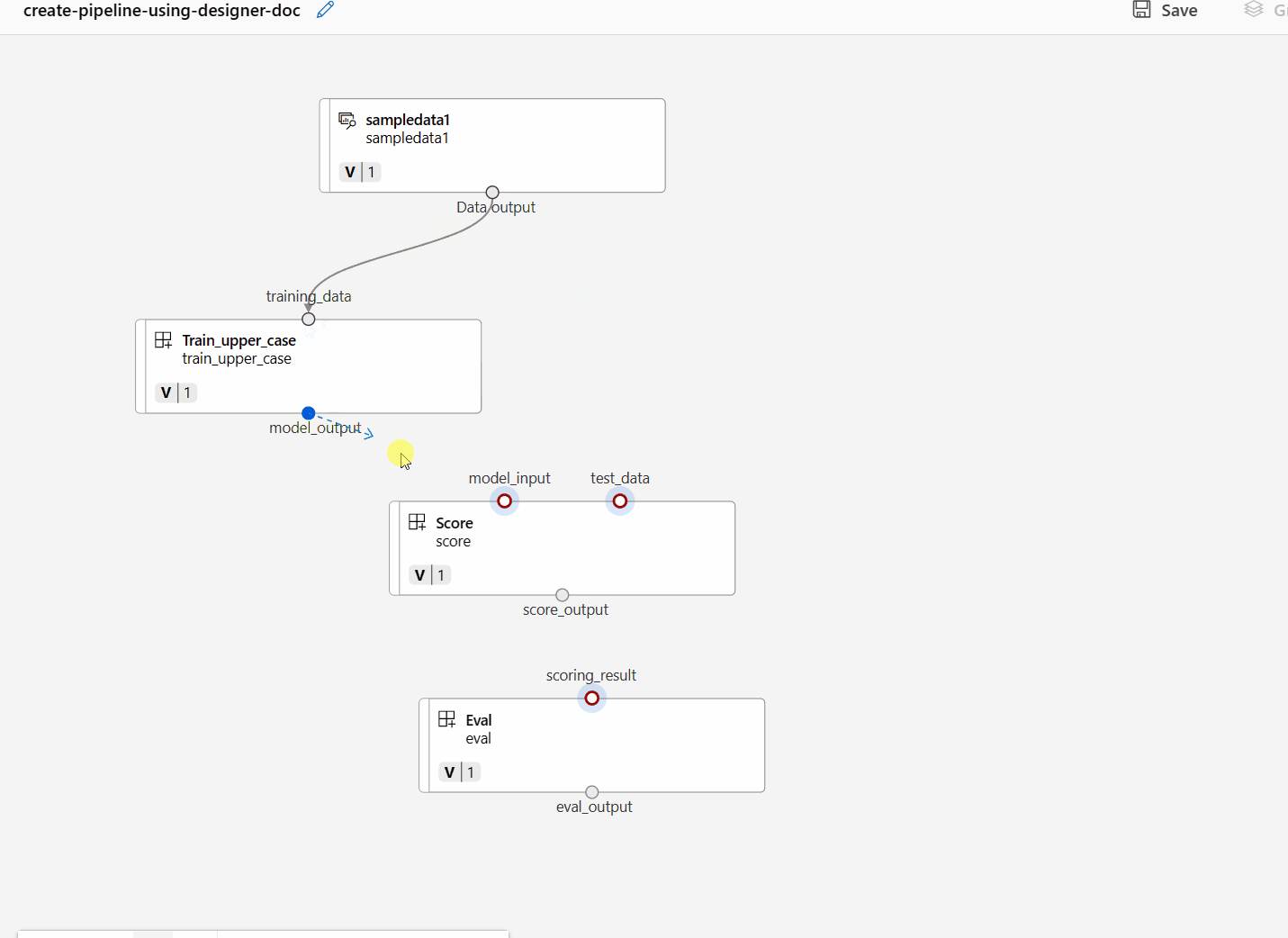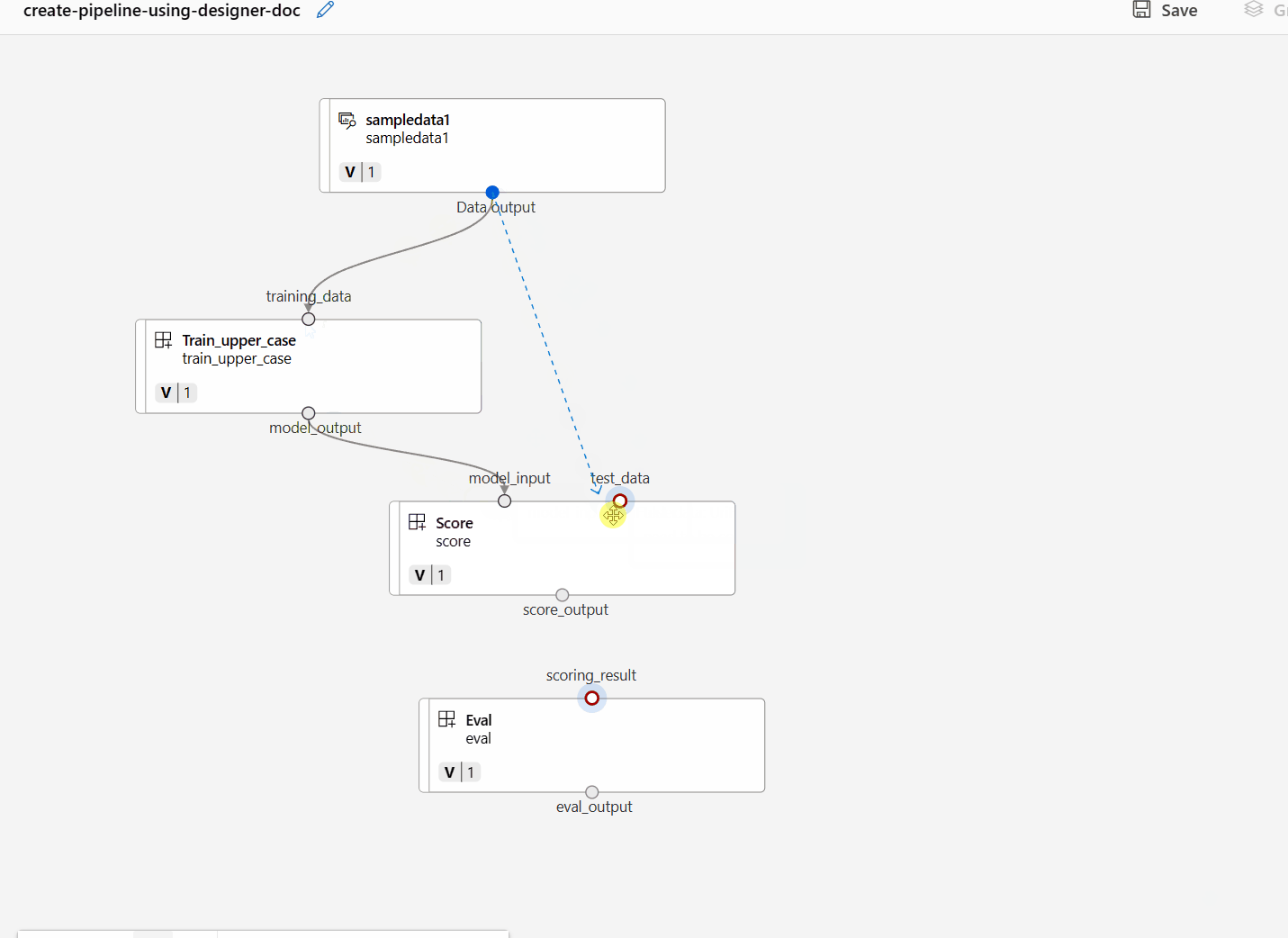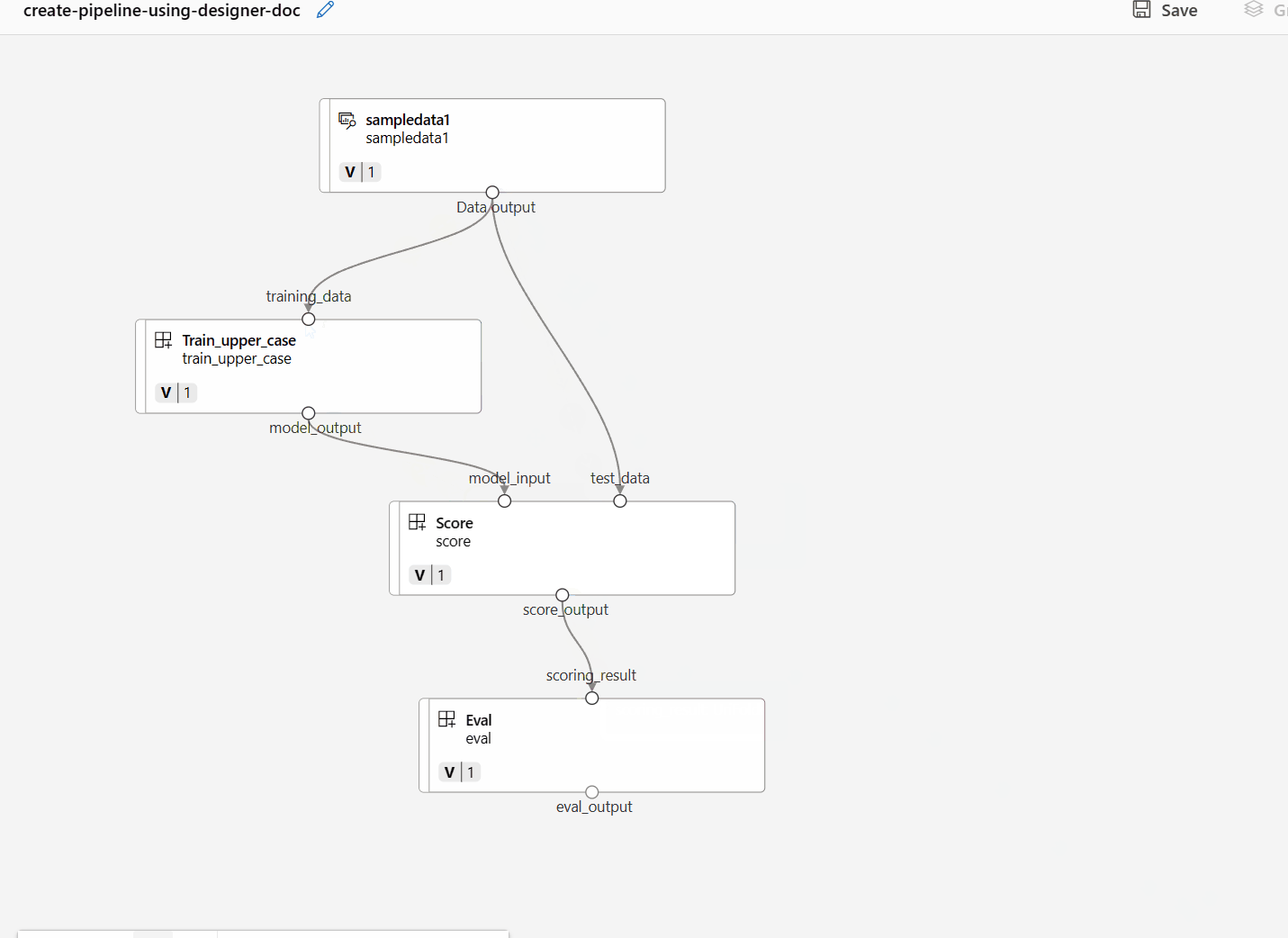
Double click one component, you'll see a right pane where you can configure the component.
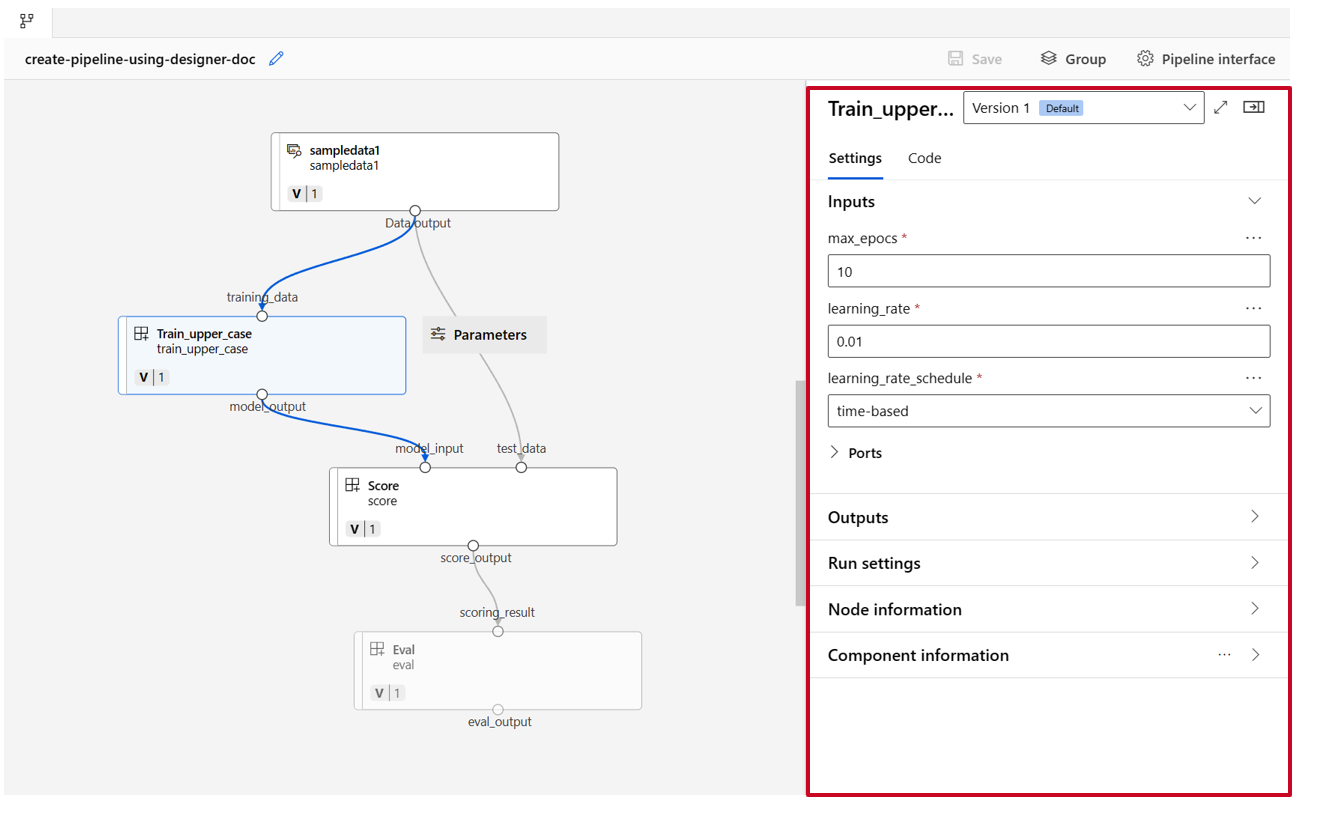
For components with primitive type inputs like number, integer, string and boolean, you can change values of such inputs in the component detailed pane, under Inputs section.
You can also change the output settings (where to store the component's output) and run settings (compute target to run this component) in the right pane.
Now let's promote the max_epocs input of the train component to pipeline level input. Doing so, you can assign a different value to this input every time before submitting the pipeline.
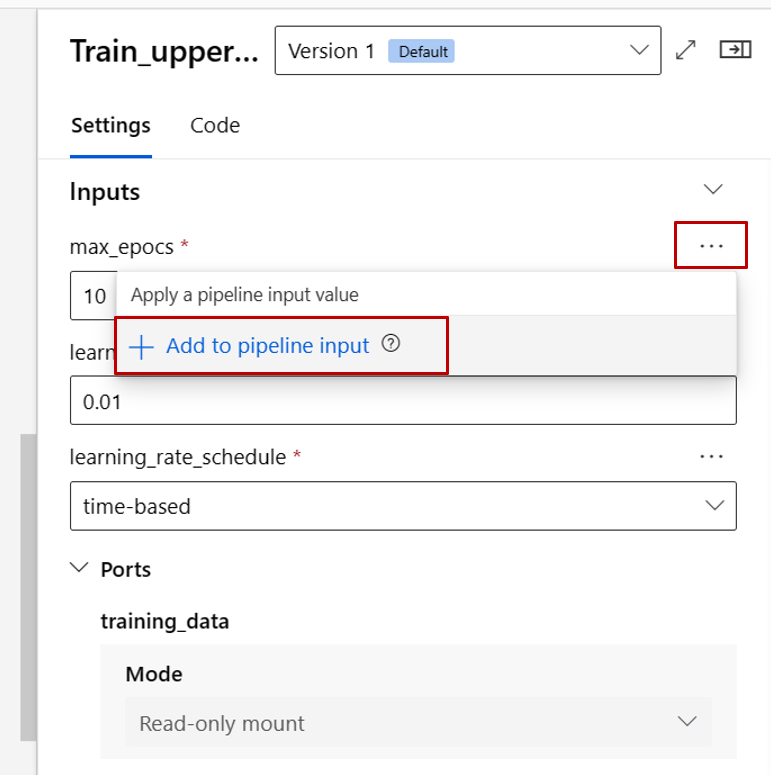









Note
Custom components and the designer classic prebuilt components cannot be used together.
Submit pipeline
Select Configure & Submit on the right top corner to submit the pipeline.

Then you'll see a step-by-step wizard, follow the wizard to submit the pipeline job.

In Basics step, you can configure the experiment, job display name, job description etc.
In Inputs & Outputs step, you can configure the Inputs/Outputs that are promoted to pipeline level. In previous step, we promoted the max_epocs of train component to pipeline input, so you should be able to see and assign value to max_epocs here.
In Runtime settings, you can configure the default datastore and default compute of the pipeline. It's the default datastore/compute for all components in the pipeline. But note if you set a different compute or datastore for a component explicitly, the system respects the component level setting. Otherwise, it uses the pipeline default value.
The Review + Submit step is the last step to review all configurations before submit. The wizard remembers your last time's configuration if you ever submit the pipeline.
After submitting the pipeline job, there will be a message on the top with a link to the job detail. You can select this link to review the job details.

Specify identity in pipeline job
When submitting pipeline job, you can specify the identity to access the data under Run settings. The default identity is AMLToken which didn't use any identity meanwhile we support both UserIdentity and Managed. For UserIdentity, the identity of job submitter is used to access input data and write the result to the output folder. If you specify Managed, the system will use the managed identity to access the input data and write the result to the output folder.

Next steps
- Use these Jupyter notebooks on GitHub to explore machine learning pipelines further
- Learn how to use CLI v2 to create pipeline using components.
- Learn how to use SDK v2 to create pipeline using components