Obs!
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Summary: Azure Synapse Analytics is a Microsoft limitless analytics platform that integrates enterprise data warehousing and big data processing into a single managed environment with no system integration required. Azure Synapse provides the end-to-end tools for your analytic life cycle with:
- Pipelines for data integration.
- Apache Spark pool for big data processing.
- Data Explorer for log and time series analytics.
- Serverless SQL pool for data exploration over Azure Data Lake.
- Dedicated SQL pool (formerly SQL DW) for enterprise data warehousing.
- Deep integration with Power BI, Azure Cosmos DB, and Azure Machine Learning.
Azure Synapse data security and privacy are non-negotiable. The purpose of this white paper is to provide a comprehensive overview of Azure Synapse security features, which are enterprise-grade and industry-leading. The white paper comprises a series of articles that cover the following five layers of security:
- Data protection
- Access control
- Authentication
- Network security
- Threat protection
This white paper targets all enterprise security stakeholders. They include security administrators, network administrations, Azure administrators, workspace administrators, and database administrators.
Writers: Vengatesh Parasuraman, Fretz Nuson, Ron Dunn, Khendr'a Reid, John Hoang, Nithesh Krishnappa, Mykola Kovalenko, Brad Schacht, Pedro Martinez, Mark Pryce-Maher, and Arshad Ali.
Technical Reviewers: Nandita Valsan, Rony Thomas, Abhishek Narain, Daniel Crawford, and Tammy Richter Jones.
Applies to: Azure Synapse Analytics, dedicated SQL pool (formerly SQL DW), serverless SQL pool, and Apache Spark pool.
Important
This white paper does not apply to Azure SQL Database, Azure SQL Managed Instance, Azure Machine Learning, or Azure Databricks.
Introduction
Frequent headlines of data breaches, malware infections, and malicious code injection are among an extensive list of security concerns for companies looking to cloud modernization. The enterprise customer requires a cloud provider or service solution that can address their concerns as they can't afford to get it wrong.
Some common security questions include:
- How can I control who can see what data?
- What are the options for verifying a user's identity?
- How is my data protected?
- What network security technology can I use to protect the integrity, confidentiality, and access of my networks and data?
- What are the tools that detect and notify me of threats?
The purpose of this white paper is to provide answers to these common security questions, and many others.
Component architecture
Azure Synapse is a Platform-as-a-service (PaaS) analytics service that brings together multiple independent components such as dedicated SQL pools, serverless SQL pools, Apache Spark pools, and data integration pipelines. These components are designed to work together to provide a seamless analytical platform experience.
Dedicated SQL pools are provisioned clusters that provide enterprise data warehousing capabilities for SQL workloads. Data is ingested into managed storage powered by Azure Storage, which is also a PaaS service. Compute is isolated from storage enabling customers to scale compute independently of their data. Dedicated SQL pools also provide the ability to query data files directly over customer-managed Azure Storage accounts by using external tables.
Serverless SQL pools are on-demand clusters that provide a SQL interface to query and analyze data directly over customer-managed Azure Storage accounts. Since they're serverless, there's no managed storage, and the compute nodes scale automatically in response to the query workload.
Apache Spark in Azure Synapse is one of Microsoft's implementations of open-source Apache Spark in the cloud. Spark instances are provisioned on-demand based on the metadata configurations defined in the Spark pools. Each user gets their own dedicated Spark instance for running their jobs. The data files processed by the Spark instances are managed by the customer in their own Azure Storage accounts.
Pipelines are a logical grouping of activities that perform data movement and data transformation at scale. Data flow is a transformation activity in a pipeline that's developed by using a low-code user interface. It can execute data transformations at scale. Behind the scenes, data flows use Apache Spark clusters of Azure Synapse to execute automatically generated code. Pipelines and data flows are compute-only services, and they don't have any managed storage associated with them.
Pipelines use the Integration Runtime (IR) as the scalable compute infrastructure for performing data movement and dispatch activities. Data movement activities run on the IR whereas the dispatch activities run on variety of other compute engines, including Azure SQL Database, Azure HDInsight, Azure Databricks, Apache Spark clusters of Azure Synapse, and others. Azure Synapse supports two types of IR: Azure Integration Runtime and Self-hosted Integration Runtime. The Azure IR provides a fully managed, scalable, and on-demand compute infrastructure. The Self-hosted IR is installed and configured by the customer in their own network, either in on-premises machines or in Azure cloud virtual machines.
Customers can choose to associate their Synapse workspace with a managed workspace virtual network. When associated with a managed workspace virtual network, Azure IRs and Apache Spark clusters that are used by pipelines, data flows, and the Apache Spark pools are deployed inside the managed workspace virtual network. This setup ensures network isolation between the workspaces for pipelines and Apache Spark workloads.
The following diagram depicts the various components of Azure Synapse.
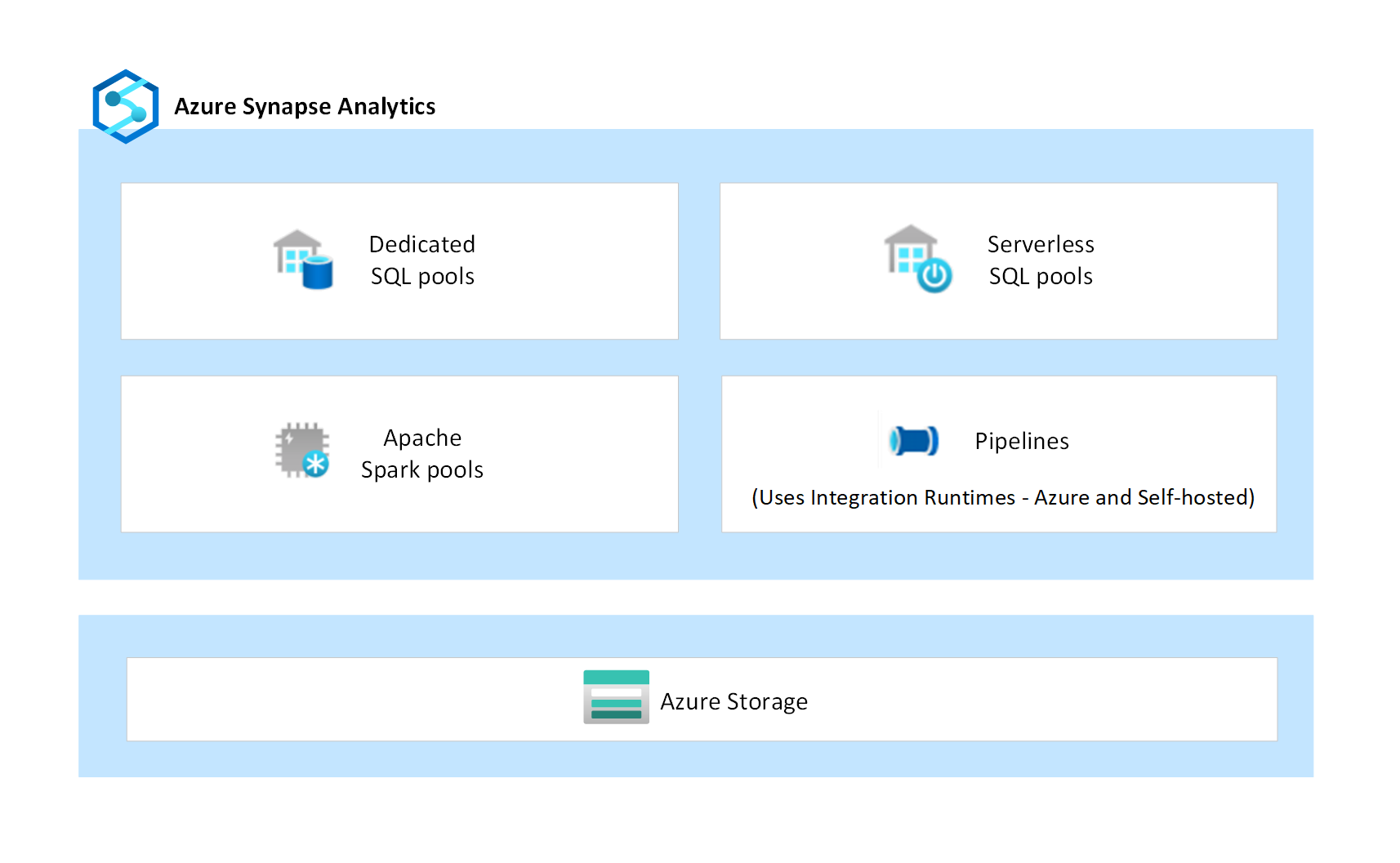
Component isolation
Each individual component of Azure Synapse depicted in the diagram provides its own security features. Security features provide data protection, access control, authentication, network security, and threat protection for securing the compute and the associated data that’s processed. Additionally, Azure Storage, being a PaaS service, provides additional security of its own, that's set up and managed by the customer in their own storage accounts. This level of component isolation limits and minimizes the exposure if there were a security vulnerability in any one of its components.
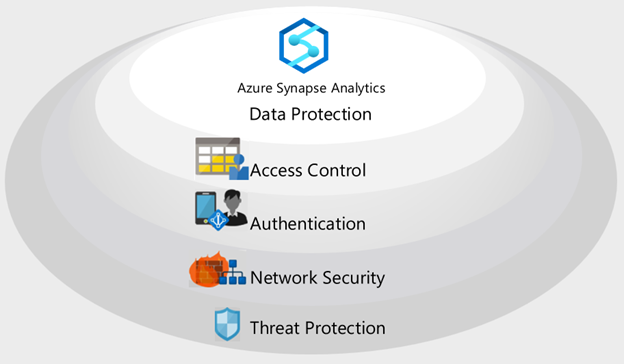
Security layers
Azure Synapse implements a multi-layered security architecture for end-to-end protection of your data. There are five layers:
- Data protection to identify and classify sensitive data, and encrypt data at rest and in motion.
- Access control to determine a user's right to interact with data.
- Authentication to prove the identity of users and applications.
- Network security to isolate network traffic with private endpoints and virtual private networks.
- Threat protection to identify potential security threats, such as unusual access locations, SQL injection attacks, authentication attacks, and more.
Next steps
In the next article in this white paper series, learn about data protection.