Azure Synapse Dedicated SQL Pool Connector for Apache Spark
Introduction
The Azure Synapse Dedicated SQL Pool Connector for Apache Spark in Azure Synapse Analytics enables efficient transfer of large data sets between the Apache Spark runtime and the Dedicated SQL pool. The connector is shipped as a default library with Azure Synapse Workspace. The connector is implemented using Scala language. The connector supports Scala and Python. To use the Connector with other notebook language choices, use the Spark magic command - %%spark.
At a high-level, the connector provides the following capabilities:
- Read from Azure Synapse Dedicated SQL Pool:
- Read large data sets from Synapse Dedicated SQL Pool Tables (Internal and External) and views.
- Comprehensive predicate push down support, where filters on DataFrame get mapped to corresponding SQL predicate push down.
- Support for column pruning.
- Support for query push down.
- Write to Azure Synapse Dedicated SQL Pool:
- Ingest large volume data to Internal and External table types.
- Supports following DataFrame save mode preferences:
AppendErrorIfExistsIgnoreOverwrite
- Write to External Table type supports Parquet and Delimited Text file format (example - CSV).
- To write data to internal tables, the connector now uses COPY statement instead of CETAS/CTAS approach.
- Enhancements to optimize end-to-end write throughput performance.
- Introduces an optional call-back handle (a Scala function argument) that clients can use to receive post-write metrics.
- Few examples include - number of records, duration to complete certain action, and failure reason.
Orchestration approach
Read
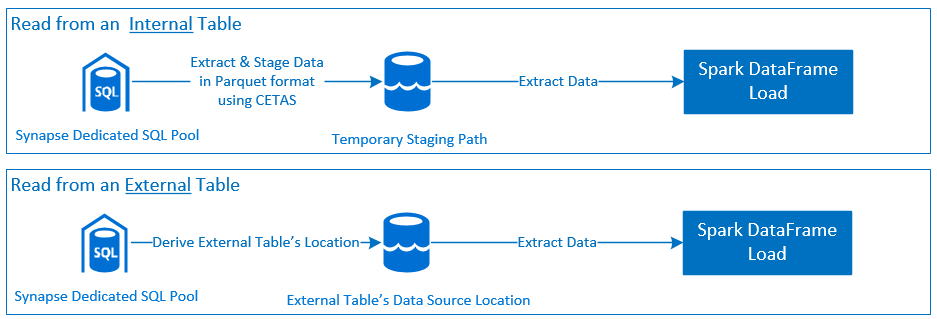
Write
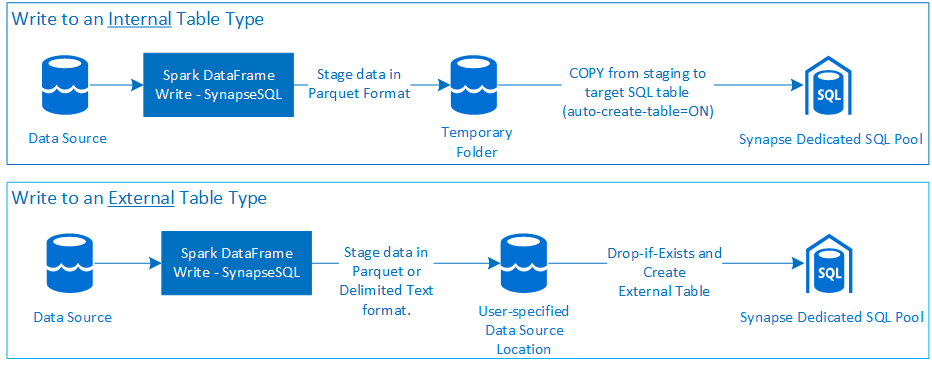
Prerequisites
Prerequisites such as setting up required Azure resources and steps to configure them are discussed in this section.
Azure resources
Review and setup following dependent Azure Resources:
- Azure Data Lake Storage - used as the primary storage account for the Azure Synapse Workspace.
- Azure Synapse Workspace - create notebooks, build and deploy DataFrame based ingress-egress workflows.
- Dedicated SQL Pool (formerly SQL DW) - provides enterprise Data Warehousing features.
- Azure Synapse Serverless Spark Pool - Spark runtime where the jobs are executed as Spark Applications.
Prepare the database
Connect to the Synapse Dedicated SQL Pool database and run following setup statements:
Create a database user that is mapped to the Microsoft Entra user Identity used to sign in to the Azure Synapse Workspace.
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;Create schema in which tables will be defined, such that the Connector can successfully write-to and read-from respective tables.
CREATE SCHEMA [<schema_name>];
Authentication
Microsoft Entra ID based authentication
Microsoft Entra ID based authentication is an integrated authentication approach. The user is required to successfully sign in to the Azure Synapse Analytics Workspace.
Basic authentication
A basic authentication approach requires user to configure username and password options. Refer to the section - Configuration options to learn about relevant configuration parameters for reading from and writing to tables in Azure Synapse Dedicated SQL Pool.
Authorization
Azure Data Lake Storage Gen2
There are two ways to grant access permissions to Azure Data Lake Storage Gen2 - Storage Account:
- Role based Access Control role - Storage Blob Data Contributor role
- Assigning the
Storage Blob Data Contributor Rolegrants the User permissions to read, write, and delete from the Azure Storage Blob Containers. - RBAC offers a coarse control approach at the container level.
- Assigning the
- Access Control Lists (ACL)
- ACL approach allows for fine-grained controls over specific paths and/or files under a given folder.
- ACL checks aren't enforced if the User is already granted permissions using RBAC approach.
- There are two broad types of ACL permissions:
- Access Permissions (applied at a specific level or object).
- Default Permissions (automatically applied for all child objects at the time of their creation).
- Type of permissions include:
Executeenables ability to traverse or navigate the folder hierarchies.Readenables ability to read.Writeenables ability to write.
- It's important to configure ACLs such that the Connector can successfully write and read from the storage locations.
Note
If you'd like to run notebooks using Synapse Workspace pipelines you must also grant above listed access permissions to the Synapse Workspace default managed identity. The workspace's default managed identity name is same as the name of the workspace.
To use the Synapse workspace with secured storage accounts, a managed private end point must be configured from the notebook. The managed private end point must be approved from the ADLS Gen2 storage account's
Private endpoint connectionssection in theNetworkingpane.
Azure Synapse Dedicated SQL Pool
To enable successful interaction with Azure Synapse Dedicated SQL Pool, following authorization is necessary unless you're a user also configured as an Active Directory Admin on the Dedicated SQL End Point:
Read scenario
Grant the user
db_exporterusing the system stored proceduresp_addrolemember.EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
Write scenario
- Connector uses the COPY command to write data from staging to the internal table's managed location.
Configure required permissions described here.
Following is a quick access snippet of the same:
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- Connector uses the COPY command to write data from staging to the internal table's managed location.
API documentation
Azure Synapse Dedicated SQL Pool Connector for Apache Spark - API Documentation.
Configuration options
To successfully bootstrap and orchestrate the read or write operation, the Connector expects certain configuration parameters. The object definition - com.microsoft.spark.sqlanalytics.utils.Constants provides a list of standardized constants for each parameter key.
Following is the list of configuration options based on usage scenario:
- Read using Microsoft Entra ID based authentication
- Credentials are automapped, and user isn't required to provide specific configuration options.
- Three-part table name argument on
synapsesqlmethod is required to read from respective table in Azure Synapse Dedicated SQL Pool.
- Read using basic authentication
- Azure Synapse Dedicated SQL End Point
Constants.SERVER- Synapse Dedicated SQL Pool End Point (Server FQDN)Constants.USER- SQL User Name.Constants.PASSWORD- SQL User Password.
- Azure Data Lake Storage (Gen 2) End Point - Staging Folders
Constants.DATA_SOURCE- Storage path set on the data source location parameter is used for data staging.
- Azure Synapse Dedicated SQL End Point
- Write using Microsoft Entra ID based authentication
- Azure Synapse Dedicated SQL End Point
- By default, the Connector infers the Synapse Dedicated SQL end point by using the database name set on the
synapsesqlmethod's three-part table name parameter. - Alternatively, users can use the
Constants.SERVERoption to specify the sql end point. Ensure the end point hosts the corresponding database with respective schema.
- By default, the Connector infers the Synapse Dedicated SQL end point by using the database name set on the
- Azure Data Lake Storage (Gen 2) End Point - Staging Folders
- For Internal Table Type:
- Configure either
Constants.TEMP_FOLDERorConstants.DATA_SOURCEoption. - If user chose to provide
Constants.DATA_SOURCEoption, staging folder will be derived by using thelocationvalue from the DataSource. - If both are provided, then the
Constants.TEMP_FOLDERoption value will be used. - In the absence of a staging folder option, the Connector will derive one based on the runtime configuration -
spark.sqlanalyticsconnector.stagingdir.prefix.
- Configure either
- For External Table Type:
Constants.DATA_SOURCEis a required configuration option.- The connector uses the storage path set on the data source's location parameter in combination with the
locationargument to thesynapsesqlmethod and derives the absolute path to persist external table data. - If the
locationargument tosynapsesqlmethod isn't specified, then the connector will derive the location value as<base_path>/dbName/schemaName/tableName.
- For Internal Table Type:
- Azure Synapse Dedicated SQL End Point
- Write using basic authentication
- Azure Synapse Dedicated SQL End Point
Constants.SERVER- - Synapse Dedicated SQL Pool End Point (Server FQDN).Constants.USER- SQL User Name.Constants.PASSWORD- SQL User Password.Constants.STAGING_STORAGE_ACCOUNT_KEYassociated with Storage Account that hostsConstants.TEMP_FOLDERS(internal table types only) orConstants.DATA_SOURCE.
- Azure Data Lake Storage (Gen 2) End Point - Staging Folders
- SQL basic authentication credentials don't apply to access storage end points.
- Hence, ensure to assign relevant storage access permissions as described in the section Azure Data Lake Storage Gen2.
- Azure Synapse Dedicated SQL End Point
Code templates
This section presents reference code templates to describe how to use and invoke the Azure Synapse Dedicated SQL Pool Connector for Apache Spark.
Note
Using the Connector in Python-
- The connector is supported in Python for Spark 3 only. For Spark 2.4 (unsupported), we can use the Scala connector API to interact with content from a DataFrame in PySpark by using DataFrame.createOrReplaceTempView or DataFrame.createOrReplaceGlobalTempView. See Section - Using materialized data across cells.
- The call back handle is not available in Python.
Read from Azure Synapse Dedicated SQL Pool
Read Request - synapsesql method signature
Read from a table using Microsoft Entra ID based authentication
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Read from a query using Microsoft Entra ID based authentication
Note
Restrictions while reading from query:
- Table name and query cannot be specified at the same time.
- Only select queries are allowed. DDL and DML SQLs are not allowed.
- The select and filter options on dataframe are not pushed down to the SQL dedicated pool when a query is specified.
- Read from a query is only available in Spark 3.
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Read from a table using basic authentication
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Read from a query using basic authentication
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Write to Azure Synapse Dedicated SQL Pool
Write Request - synapsesql method signature
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Write using Microsoft Entra ID based authentication
Following is a comprehensive code template that describes how to use the Connector for write scenarios:
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure Portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
Write using basic authentication
Following code snippet replaces the write definition described in the Write using Microsoft Entra ID based authentication section, to submit write request using SQL basic authentication approach:
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
In a basic authentication approach, in order to read data from a source storage path other configuration options are required. Following code snippet provides an example to read from an Azure Data Lake Storage Gen2 data source using Service Principal credentials:
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
Supported DataFrame save modes
Following save modes are supported when writing source data to a destination table in Azure Synapse Dedicated SQL Pool:
- ErrorIfExists (default save mode)
- If destination table exists, then the write is aborted with an exception returned to the callee. Else, a new table is created with data from the staging folders.
- Ignore
- If the destination table exists, then the write will ignore the write request without returning an error. Else, a new table is created with data from the staging folders.
- Overwrite
- If the destination table exists, then existing data in the destination is replaced with data from the staging folders. Else, a new table is created with data from the staging folders.
- Append
- If the destination table exists, then the new data is appended to it. Else, a new table is created with data from the staging folders.
Write request callback handle
The new write path API changes introduced an experimental feature to provide the client with a key->value map of post-write metrics. Keys for the metrics are defined in the new Object definition - Constants.FeedbackConstants. Metrics can be retrieved as a JSON string by passing in the callback handle (a Scala Function). Following is the function signature:
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
Following are some notable metrics (presented in camel case):
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
Following is a sample JSON string with post-write metrics:
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
More code samples
Using materialized data across cells
Spark DataFrame's createOrReplaceTempView can be used to access data fetched in another cell, by registering a temporary view.
- Cell where data is fetched (say with Notebook language preference as
Scala)
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- Now, change the language preference on the Notebook to
PySpark (Python)and fetch data from the registered view<temporary_view_name>
spark.sql("select * from <temporary_view_name>").show()
Response handling
Invoking synapsesql has two possible end states - Success or a Failed State. This section describes how to handle the request response for each scenario.
Read request response
Upon completion, the read response snippet is displayed in the cell's output. Failure in the current cell will also cancel subsequent cell executions. Detailed error information is available in the Spark Application Logs.
Write request response
By default, a write response is printed to the cell output. On failure, the current cell is marked as failed, and subsequent cell executions will be aborted. The other approach is to pass the callback handle option to the synapsesql method. The callback handle will provide programmatic access to the write response.
Other considerations
- When reading from the Azure Synapse Dedicated SQL Pool tables:
- Consider applying necessary filters on the DataFrame to take advantage of the Connector's column-pruning feature.
- Read scenario doesn't support the
TOP(n-rows)clause, when framing theSELECTquery statements. The choice to limit data is to use the DataFrame's limit(.) clause.- Refer the example - Using materialized data across cells section.
- When writing to the Azure Synapse Dedicated SQL Pool tables:
- For internal table types:
- Tables are created with ROUND_ROBIN data distribution.
- Column types are inferred from the DataFrame that would read data from source. String columns are mapped to
NVARCHAR(4000).
- For external table types:
- DataFrame's initial parallelism drives the data organization for the external table.
- Column types are inferred from the DataFrame that would read data from source.
- Better data distribution across executors can be achieved by tuning the
spark.sql.files.maxPartitionBytesand the DataFrame'srepartitionparameter. - When writing large data sets, it's important to factor in the impact of DWU Performance Level setting that limits transaction size.
- For internal table types:
- Monitor Azure Data Lake Storage Gen2 utilization trends to spot throttling behaviors that can impact read and write performance.