Traffic Manager endpoint monitoring
Azure Traffic Manager includes built-in endpoint monitoring and automatic endpoint failover. This feature helps you deliver high-availability applications that are resilient to endpoint failure, including Azure region failures. Endpoint monitoring is enabled by default. To disable monitoring, see Enable or disable health checks.
Configure endpoint monitoring
To configure endpoint monitoring, you must specify the following settings on your Traffic Manager profile:
- Protocol. Choose HTTP, HTTPS, or TCP as the protocol that Traffic Manager uses when probing your endpoint to check its health. HTTPS monitoring doesn't verify whether your TLS/SSL certificate is valid, it only checks that the certificate is present.
- Port. Choose the port used for the request.
- Path. This configuration setting is valid only for the HTTP and HTTPS protocols, for which specifying the path setting is required. Providing this setting for the TCP monitoring protocol results in an error. For HTTP and HTTPS protocol, give the relative path and the name of the webpage or the file that the monitoring accesses. A forward slash
/is a valid entry for the relative path. This value implies that the file is in the root directory (default). - Custom header settings. This configuration setting helps you add specific HTTP headers to the health checks that Traffic Manager sends to endpoints under a profile. The custom headers can be specified at a profile level to be applicable for all endpoints in that profile and/or at an endpoint level applicable only to that endpoint. You can use custom headers for health checks of endpoints in a multi-tenant environment. That way, it can be routed correctly to their destination by specifying a host header. You can also use this setting by adding unique headers that can be used to identify Traffic Manager originated HTTP(S) requests and processes them differently. You can specify up to eight
header:valuepairs separated by a comma. For example,header1:value1, header2:value2.
Note
Using asterisk characters (*) in custom Host headers is unsupported.
Expected status code ranges. This setting allows you to specify multiple success code ranges in the format 200-299, 301-301. If these status codes are received as response from an endpoint when a health check is done, Traffic Manager marks those endpoints as healthy. You can specify a maximum of eight status code ranges. This setting is applicable only to HTTP and HTTPS protocol and to all endpoints. This setting is at the Traffic Manager profile level and by default the value 200 is defined as the success status code.
Probing interval. This value specifies how often an endpoint is checked for its health from a Traffic Manager probing agent. You can specify two values here: 30 seconds (normal probing) and 10 seconds (fast probing). If no values are provided, the profile sets to a default value of 30 seconds. Visit the Traffic Manager pricing page to learn more about fast probing pricing.
Tolerated number of failures. This value specifies how many failures a Traffic Manager probing agent tolerates before marking that endpoint as unhealthy. Its value can range between 0 and 9. A value of 0 means a single monitoring failure can cause that endpoint to be marked as unhealthy. If no value is specified, it uses the default value of 3.
Probe timeout. This property specifies the amount of time the Traffic Manager probing agent should wait before considering a health probe check to an endpoint a failure. If the Probing Interval is set to 30 seconds, then you can set the Timeout value between 5 and 10 seconds. If no value is specified, it uses a default value of 10 seconds. If the Probing Interval is set to 10 seconds, then you can set the Timeout value between 5 and 9 seconds. If no Timeout value is specified, it uses a default value of 9 seconds.
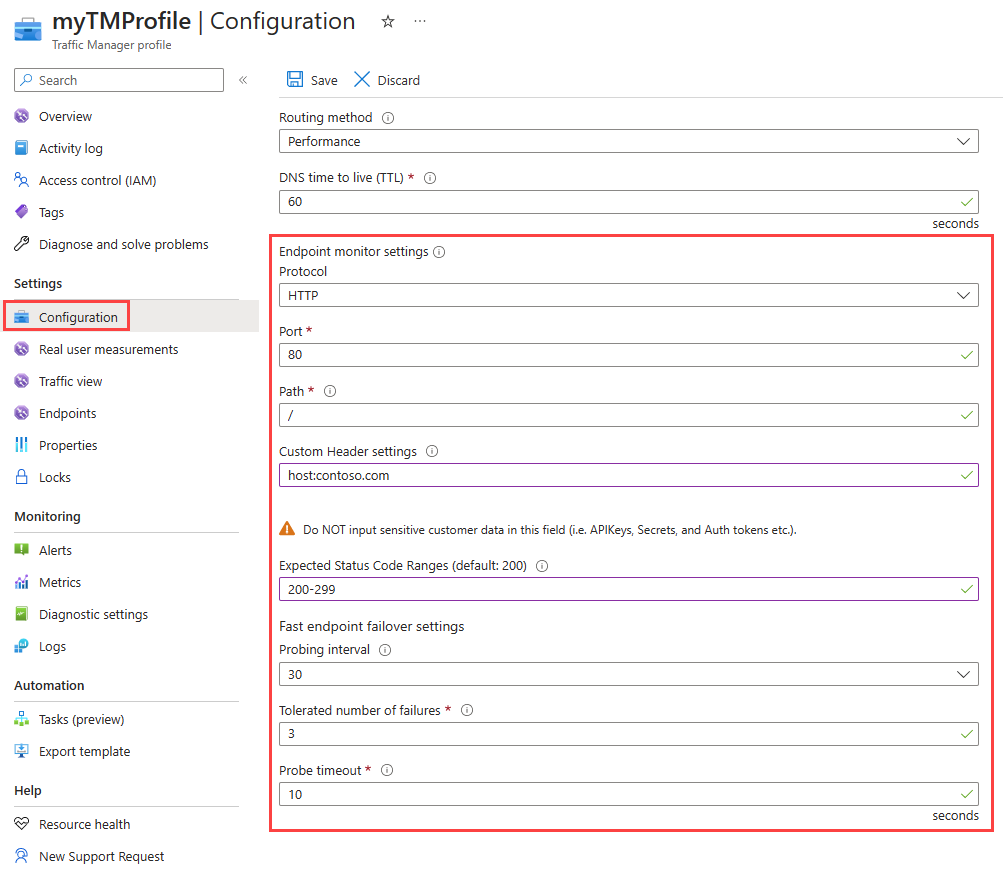
Figure: Traffic Manager endpoint monitoring

How endpoint monitoring works
When the monitoring protocol is set as HTTP or HTTPS, the Traffic Manager probing agent makes a GET request to the endpoint using the protocol, port, and relative path given. An endpoint is considered healthy if probing agent receives a 200-OK response, or any of the responses configured in the Expected status code ranges. If the response is a different value or no response get received within the timeout period, the Traffic Manager probing agent reattempts according to the Tolerated Number of Failures setting. No reattempts are done if this setting is 0. The endpoint is marked unhealthy if the number of consecutive failures is higher than the Tolerated number of failures setting.
When the monitoring protocol is TCP, the Traffic Manager probing agent creates a TCP connection request using the port specified. If the endpoint responds to the request with a response to establish the connection, that health check is marked as a success. The Traffic Manager probing agent resets the TCP connection. In cases where the response is a different value or no response get received within the timeout period, the Traffic Manager probing agent reattempts according to the Tolerated number of failures setting. No reattempts are made if this setting is 0. If the number of consecutive failures is higher than the Tolerated number of failures setting, then that endpoint is marked unhealthy.
In all cases, Traffic Manager probes from multiple locations. The consecutive failure determines what happen within each region. That's why endpoints are receiving health probes from Traffic Manager with a higher frequency than the setting used for Probing Interval.
Note
For HTTP or HTTPS monitoring protocol, a common practice on the endpoint side is to implement a custom page within your application - for example, /health.aspx. Using this path for monitoring, you can perform application-specific checks, such as checking performance counters or verifying database availability. Based on these custom checks, the page returns an appropriate HTTP status code.
All endpoints in a Traffic Manager profile share monitoring settings. If you need to use different monitoring settings for different endpoints, you can create nested Traffic Manager profiles.
Endpoint and profile status
You can enable and disable Traffic Manager profiles and endpoints. However, a change in endpoint status also might occur because of the Traffic Manager automated settings and processes.
Endpoint status
You can enable or disable a specific endpoint. The underlying service, which might still be healthy, is unaffected. Changing the endpoint status controls the availability of the endpoint in the Traffic Manager profile. When an endpoint status is disabled, Traffic Manager doesn't check its health, and the endpoint isn't included in a DNS response.
Profile status
Using the profile status setting, you can enable or disable a specific profile. While endpoint status affects a single endpoint, profile status affects the entire profile, including all endpoints. When you disable a profile, the endpoints aren't checked for health, and no endpoints are included in a DNS response. An NXDOMAIN response code is returned for the DNS query.
Endpoint monitor status
Endpoint monitor status is a Traffic Manager-generated value that shows the status of the endpoint. You can't change this setting manually. The endpoint monitor status is a combination of the results of endpoint monitoring and the configured endpoint status. The possible values of endpoint monitor status are shown in the following table:
| Profile status | Endpoint status | Endpoint monitor status | Notes |
|---|---|---|---|
| Disabled | Enabled | Inactive | The profile has been disabled. Although the endpoint status is Enabled, the profile status (Disabled) takes precedence. Endpoints in disabled profiles aren't monitored. An NXDOMAIN response code is returned for the DNS query. |
| <any> | Disabled | Disabled | The endpoint has been disabled. Disabled endpoints aren't monitored. The endpoint isn't included in DNS responses, as such it doesn't receive traffic. |
| Enabled | Enabled | Online | The endpoint is monitored and is healthy. It's included in DNS responses and can receive traffic. |
| Enabled | Enabled | Degraded | Endpoint monitoring health checks are failing. The endpoint isn't included in DNS responses and doesn't receive traffic. An exception is if all endpoints are degraded. In which case all of them are considered to be returned in the query response. |
| Enabled | Enabled | CheckingEndpoint | The endpoint is monitored, but the results of the first probe haven't been received yet. CheckingEndpoint is a temporary state that usually occurs immediately after adding or enabling an endpoint in the profile. An endpoint in this state is included in DNS responses and can receive traffic. |
| Enabled | Enabled | Stopped | The web app that the endpoint points to isn't running. Check the web app settings. This status can also happen if the endpoint is of type nested endpoint and the child profile get disabled or is inactive. An endpoint with a Stopped status isn't monitored. It isn't included in DNS responses and doesn't receive traffic. An exception is if all endpoints are degraded. In which case all of them are considered to be returned in the query response. |
| Enabled | Enabled | Not monitored | The endpoint is configured to always serve traffic. Health checks aren't enabled. |
For details about how endpoint monitor status is calculated for nested endpoints, see Nested Traffic Manager profiles.
Note
A Stopped Endpoint monitor status can happen on App Service if your web application is not running in the Standard tier or above. For more information, see Traffic Manager integration with App Service.
Profile monitor status
The profile monitor status is a combination of the configured profile status and the endpoint monitor status values for all endpoints. The possible values are described in the following table:
| Profile status (as configured) | Endpoint monitor status | Profile monitor status | Notes |
|---|---|---|---|
| Disabled | <any> or a profile with no defined endpoints. | Disabled | The profile has been disabled. |
| Enabled | The status of at least one endpoint is Degraded. | Degraded | Review the individual endpoint status values to determine which endpoints require further attention. |
| Enabled | The status of at least one endpoint is Online. No endpoints have a Degraded status. | Online | The service is accepting traffic. No further action is required. |
| Enabled | The status of at least one endpoint is CheckingEndpoint. No endpoints are in Online or Degraded status. | CheckingEndpoints | This transition state occurs when a profile if created or enabled. The endpoint health is being checked for the first time. |
| Enabled | The statuses of all endpoints in the profile are either Disabled or Stopped, or the profile has no defined endpoints. | Inactive | No endpoints are active, but the profile is still Enabled. |
Endpoint failover and recovery
Traffic Manager periodically checks the health of every endpoint, including unhealthy endpoints. Traffic Manager detects when an endpoint becomes healthy and brings it back into rotation.
An endpoint is unhealthy when any of the following events occur:
- If the monitoring protocol is HTTP or HTTPS:
- A non-200 response, or a response that doesn't include the status range specified in the Expected status code ranges setting get received. (Including a different 2xx code, or a 301/302 redirect).
- If the monitoring protocol is TCP:
- A response other than ACK or SYN-ACK gets received in response to the SYN request sent by Traffic Manager to attempt a connection establishment.
- Timeout.
- Any other connection issue resulting in the endpoint being not reachable.
For more information about troubleshooting failed checks, see Troubleshooting degraded status on Azure Traffic Manager.
The timeline in the following figure is a detailed description of the monitoring process of Traffic Manager endpoint that has the following settings:
- Monitoring protocol is HTTP.
- Probing interval is 30 seconds.
- Number of tolerated failures is 3.
- Timeout value is 10 seconds.
- DNS TTL is 30 seconds.
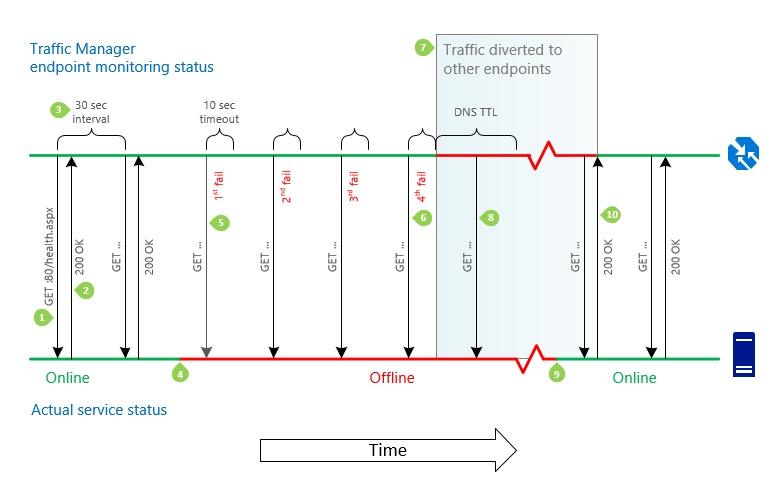 Figure: Traffic manager endpoint failover and recovery sequence
Figure: Traffic manager endpoint failover and recovery sequence
GET. For each endpoint, the Traffic Manager monitoring system does a GET request on the path specified in the monitoring settings.
200 OK or custom code range specified Traffic Manager profile monitoring settings. The monitoring system expects an HTTP 200 OK or a status code in the range specified in the monitoring settings to be returned within 10 seconds. When it receives this response, it recognizes that the service is available.
30 seconds between checks. The endpoint health check is repeated every 30 seconds.
Service unavailable. The service becomes unavailable. Traffic Manager won't know until the next health check.
Attempts to access the monitoring path. The monitoring system does a GET request, but doesn't receive a response within the timeout period of 10 seconds. It then tries three more times, at 30-second intervals. If one of the tries is successful, then the number of tries is reset.
Status set to Degraded. After a fourth consecutive failure, the monitoring system marks the unavailable endpoint status as Degraded.
Traffic is diverted to other endpoints. The Traffic Manager DNS name servers are updated and Traffic Manager no longer returns the endpoint in response to DNS queries. New connections are directed to other, available endpoints. However, previous DNS responses that include this endpoint might still be cached by recursive DNS servers and DNS clients. Clients continue to use the endpoint until the DNS cache expires. As the DNS cache expires, clients make new DNS queries and are directed to different endpoints. The cache duration is controlled by the TTL setting in the Traffic Manager profile, for example, 30 seconds.
Health checks continue. Traffic Manager continues to check the health of the endpoint while it has a Degraded status. Traffic Manager detects when the endpoint returns to health.
Service comes back online. The service becomes available. The endpoint keeps its Degraded status in Traffic Manager until the monitoring system does its next health check.
Traffic to service resumes. Traffic Manager sends a GET request and receives a 200 OK status response. The service has returned to a healthy state. The Traffic Manager name servers are updated, and they begin to hand out the service's DNS name in DNS responses. Traffic returns to the endpoint as cached DNS responses that return other endpoints expire, and as existing connections to other endpoints are ending.
Important
Traffic manager deploys multiple probes from multiple locations for each endpoint. Multiple probes increase resiliency for endpoint monitoring. Traffic manager aggregates the average health of the probes rather than rely on a singular probe instance. The redundancy of the probing system is by design. Endpoint values should be looked at holistically and not per probe. The number displayed for probe health is an average. The status should only be a concern if less than 50% (0.5) of probes publish an up status.
Note
Because Traffic Manager works at the DNS level, it cannot influence existing connections to any endpoint. When it directs traffic between endpoints (either by changed profile settings, or during failover or failback), Traffic Manager directs new connections to available endpoints. Other endpoints might continue to receive traffic via existing connections until those sessions are terminated. To enable traffic to drain from existing connections, applications should limit the session duration used with each endpoint.
Traffic-routing methods
When an endpoint has a Degraded status, it's no longer returned in response to DNS queries. Instead, an alternative endpoint is chosen and returned. The traffic-routing method configured in the profile determines how the alternative endpoint is chosen.
- Priority. Endpoints establish a prioritized list. The first available endpoint on the list is always returned. If an endpoint status is Degraded, then the next available endpoint is returned.
- Weighted. Any available endpoints get chosen at random based on their assigned weights and the weights of the other available endpoints.
- Performance. The endpoint closest to the end user is returned. If that endpoint is unavailable, Traffic Manager moves traffic to the endpoints in the next closest Azure region. You can configure alternative failover plans for performance traffic-routing by using nested Traffic Manager profiles.
- Geographic. The endpoint mapped to serve the geographic location (based on the query request IP addresses) is returned. If that endpoint is unavailable, another endpoint isn't selected to fail over to, since a geographic location can be mapped only to one endpoint in a profile. (More details are in the FAQ). As a best practice, when using geographic routing, we recommend customers to use nested Traffic Manager profiles with more than one endpoint as the endpoints of the profile.
- MultiValue Multiple endpoints mapped to IPv4/IPv6 addresses are returned. When a query is received for this profile, healthy endpoints are returned based on the Maximum record count in response value that you've specified. The default number of responses is two endpoints.
- Subnet The endpoint mapped to a set of IP address ranges is returned. When a request is received from that IP address, the endpoint returned is the one mapped for that IP address.
For more information, see Traffic Manager traffic-routing methods.
Note
One exception to normal traffic-routing behavior occurs when all eligible endpoints have a degraded status. Traffic Manager makes a "best effort" attempt and responds as if all the Degraded status endpoints actually are in an online state. This behavior is preferable to the alternative, which would be to not return any endpoint in the DNS response. Disabled or Stopped endpoints are not monitored, therefore, they are not considered eligible for traffic.
This condition is commonly caused by improper configuration of the service, such as:
- An access control list [ACL] blocking the Traffic Manager health checks.
- An improper configuration of the monitoring port or protocol in the Traffic manager profile.
The consequence of this behavior is that if Traffic Manager health checks are not configured correctly, it might appear from the traffic routing as though Traffic Manager is working properly. However, in this case, endpoint failover cannot happen which affects overall application availability. It is important to check that the profile shows an Online status, not a Degraded status. An Online status indicates that the Traffic Manager health checks are working as expected.
For more information about troubleshooting failed health checks, see Troubleshooting degraded status on Azure Traffic Manager.
Enable or disable health checks
Azure Traffic Manager also enables you to configure endpoint Health Checks to be enabled or disabled. To disable monitoring, choose the option to Always serve traffic.
There are two available settings for Health Checks:
- Enable (health checks). Traffic is served to the endpoint based on health. This setting is the default.
- Always serve traffic. This setting disables health checks.
Always Serve
When Always serve traffic is selected, monitoring is bypassed and traffic is always sent to an endpoint. The endpoint monitor status displayed is Unmonitored.
To enable Always Serve:
- Select Endpoints in the Settings section of your Traffic Manager profile blade.
- Select the endpoint that you want to configure.
- Under Health Checks, choose Always serve traffic.
- Select Save.
See the following example:

Note
- Health checks can't be disabled on nested Traffic Manager profiles.
- An endpoint must be enabled to configure health checks.
- Enabling and disabling an endpoint doesn't reset the Health Checks configuration.
- Endpoints that are configured to always serve traffic are billed for basic health checks.
FAQs
- Is Traffic Manager resilient to Azure region failures?
- How does the choice of resource group location affect Traffic Manager?
- How do I determine the current health of each endpoint?
- Can I monitor HTTPS endpoints?
- Do I use an IP address or a DNS name when adding an endpoint?
- What types of IP addresses can I use when adding an endpoint?
- Can I use different endpoint addressing types within a single profile?
- What happens when an incoming query’s record type is different from the record type associated with the addressing type of the endpoints?
- Can I use a profile with IPv4 / IPv6 addressed endpoints in a nested profile?
- I stopped a web application endpoint in my Traffic Manager profile but I'm not receiving any traffic even after I restarted it. How can I fix this issue?
- Can I use Traffic Manager even if my application doesn't have support for HTTP or HTTPS?
- What specific responses are required from the endpoint when using TCP monitoring?
- How fast does Traffic Manager move my users away from an unhealthy endpoint?
- How can I specify different monitoring settings for different endpoints in a profile?
- How can I assign HTTP headers to the Traffic Manager health checks to my endpoints?
- What host header do endpoint health checks use?
- What are the IP addresses from which the health checks originate?
- How many health checks to my endpoint can I expect from Traffic Manager?
- How can I get notified if one of my endpoints goes down?
Next steps
- Learn how Traffic Manager works
- Learn more about the traffic-routing methods supported by Traffic Manager
- Learn how to create a Traffic Manager profile
- Troubleshoot Degraded status on a Traffic Manager endpoint
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for