Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Shift right is the practice of moving some testing later in the DevOps process to test in production. Testing in production uses real deployments to validate and measure an application's behavior and performance in the production environment.
One way DevOps teams can improve velocity is with a shift-left test strategy. Shift left pushes most testing earlier in the DevOps pipeline, to reduce the amount of time for new code to reach production and operate reliably.
But while many kinds of tests, such as unit tests, can easily shift left, some classes of tests can't run without deploying part or all of a solution. Deploying to a QA or staging service can simulate a comparable environment, but there's no full substitute for the production environment. Teams find that certain types of testing need to happen in production.
Testing in production provides:
- The full breadth and diversity of the production environment.
- The real workload of customer traffic.
- Profiles and behaviors as production demand evolves over time.
The production environment keeps changing. Even if an app doesn't change, the infrastructure it relies on changes constantly. Testing in production validates the health and quality of a given production deployment and of the constantly changing production environment.
Shifting right to test in production is especially important for the following scenarios:
Microservices deployments
Microservices-based solutions can have a large number of microservices that are developed, deployed, and managed independently. Shifting testing right is especially important for these projects, because different versions and configurations can reach production in many ways. Regardless of pre-production test coverage, it's necessary to test compatibility in production.
Ensuring quality post-deployment
Releasing to production is just half of delivering software. The other half is ensuring quality at scale with a real workload in production. Because the environment keeps changing, a team is never done with testing in production.
Test data from production is literally the test results from the real customer workload. Testing in production includes monitoring, failover testing, and fault injection. This testing tracks failures, exceptions, performance metrics, and security events. The test telemetry also helps detect anomalies.
Deployment tiers
To safeguard the production environment, teams can roll out changes in a progressive and controlled way by using tier-based deployments and feature flags. For example, it's better to catch a bug that prevents a shopper from completing their purchase when less than 1% of customers are on that deployment tier, than after switching all customers at once. The feature value with detected failures must exceed the net losses of those failures, measured in a meaningful way for the given business.
The first tier should be the smallest size necessary to run the standard integration suite. The tests might be similar to those already run earlier in the pipeline against other environments, but testing validates that the behavior is the same in the production environment. This tier identifies obvious errors, such as misconfigurations, before they impact any customers.
After the initial tier validates, the next tier can broaden to include a subset of real users for the test run. If everything looks good, the deployment can progress through further tiers and tests until everyone is using it. Full deployment doesn't mean that testing is over. Tracking telemetry is critically important for testing in production.
Fault injection
Teams often employ fault injection and chaos engineering to see how a system behaves under failure conditions. These practices help to:
- Validate that implemented resiliency mechanisms actually work.
- Validate that a failure in one subsystem is contained within that subsystem and doesn't cascade to produce a major outage.
- Prove that repair work for a prior incident has the desired effect, without having to wait for another incident to occur.
- Create more realistic training drills for live site engineers so they can better prepare to deal with incidents.
It's a good practice to automate fault injection experiments, because they are expensive tests that must run on ever-changing systems.
Chaos engineering can be an effective tool, but should be limited to canary environments that have little or no customer impact.
Failover testing
One form of fault injection is failover testing to support business continuity and disaster recovery (BCDR). Teams should have failover plans for all services and subsystems. The plans should include:
- A clear explanation of the business impact of the service going down.
- A map of all the dependencies in terms of platform, technology, and people devising the BCDR plans.
- Formal documentation of disaster recovery procedures.
- A cadence to regularly execute disaster recovery drills.
Circuit breaker fault testing
A circuit breaker mechanism cuts off a given component from a larger system, usually to prevent failures in that component from spreading outside its boundaries. You can intentionally trigger circuit breakers to test the following scenarios:
Whether a fallback works when the circuit breaker opens. The fallback might work with unit tests, but the only way to know if it will behave as expected in production is to inject a fault to trigger it.
Whether the circuit breaker has the right sensitivity threshold to open when it needs to. Fault injection can force latency or disconnect dependencies to observe breaker responsiveness. It's important to verify not only that the correct behavior occurs, but that it happens quickly enough.
Example: Testing a Redis cache circuit breaker
Redis cache improves product performance by speeding up access to commonly used data. Consider a scenario that takes a non-critical dependency on Redis. If Redis goes down, the system should continue to work, because it can fall back to using the original data source for requests. To confirm that a Redis failure triggers a circuit breaker and that the fallback works in production, periodically run tests against these behaviors.
The following diagram shows tests for the Redis circuit breaker fallback behavior. The goal is to make sure that when the breaker opens, calls ultimately go to SQL.
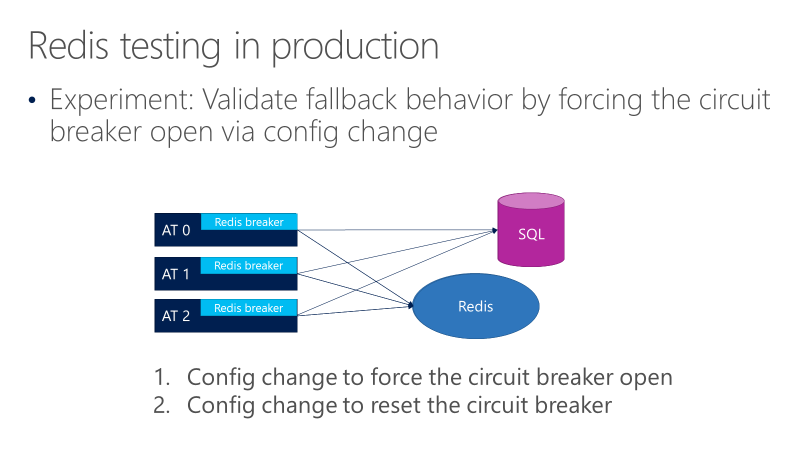
The preceding diagram shows three ATs, with the breakers in front of the calls to Redis. One test forces the circuit breaker to open through a configuration change, and then observes whether the calls go to SQL. Another test then checks the opposite configuration change, by closing the circuit breaker to confirm that calls return back to Redis.
This test validates that the fallback behavior works when the breaker opens, but it doesn't validate that the circuit breaker configuration opens the breaker when it should. Testing that behavior requires simulating actual failures.
A fault agent can introduce faults in calls going to Redis. The following diagram shows testing with fault injection.
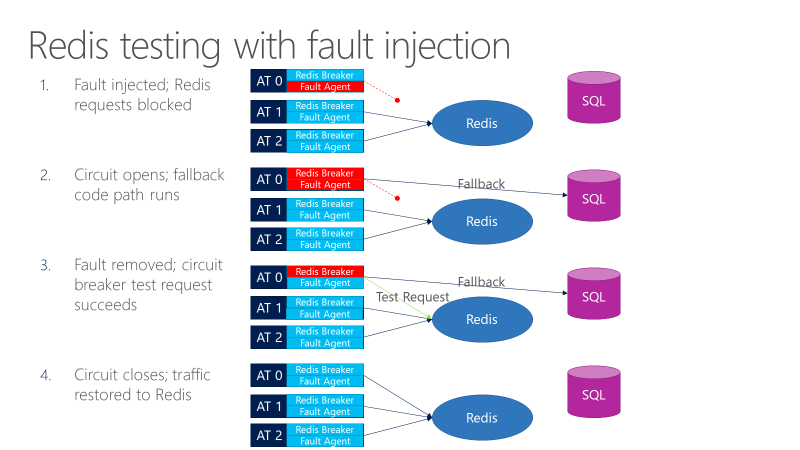
- The fault injector blocks Redis requests.
- The circuit breaker opens, and the test can observe whether fallback works.
- The fault is removed, and the circuit breaker sends a test request to Redis.
- If the request succeeds, calls revert back to Redis.
Further steps could test the sensitivity of the breaker, whether the threshold is too high or too low, and whether other system timeouts interfere with the circuit breaker behavior.
In this example, if the breaker doesn't open or close as expected, it could cause a live site incident (LSI). Without the fault injection testing, the issue might go undetected, as it's hard to do this type of testing in a lab environment.
Next steps
- [Shift testing left with unit tests]shift-left
- What are microservices?
- Run a test failover (disaster recovery drill) to Azure
- Safe deployment practices
- What is monitoring?
- What is platform engineering?