Oversikt over dataimport- og -eksportjobber
For å opprette og administrere dataimport- og -eksportjobber bruker du arbeidsområdet Dataadministrasjon. Som standard oppretter dataimporterings- og eksportprosessen et oppstartstabell for hver enhet i måldatabasen. Staging-tabeller lar deg verifisere, rydde opp eller konvertere data før du flytter den.
Notat
Denne artikkelen forutsetter at du er kjent med dataenheter.
Prosess for dataimport/-eksport
Her er fremgangsmåten for å importere eller eksportere data.
Opprett en import- eller eksportjobb der du fullfører følgende oppgaver:
- Definer prosjektkategori.
- Identifiser enhetene som skal importeres eller eksporteres.
- Sett dataformatet for jobben.
- Sekvenser enhetene, slik at de blir behandlet i logiske grupper og i en rekkefølge som gir mening.
- Bestem deg for om du skal bruke staging-tabeller.
Bekreft at kildedataene og måldataene er tilordnet riktig.
Bekreft sikkerheten for import- eller eksportjobben.
Kjør import- eller eksportjobben.
Bekreft at jobben løp som forventet ved å se gjennom jobbhistorikken.
Rydd opp i staging-tabellene.
De gjenværende delene av denne artikkelen gir mer informasjon om hvert trinn i prosessen.
Obs!
Hvis du vil oppdatere dataimport/-eksportskjemaet for å se siste fremdrift, kan du bruke ikonet for skjemaoppdatering. Oppdatering på lesernivå anbefales ikke fordi det forstyrrer import- og eksportjobber som ikke kjøres satsvis.
Opprett en import- eller eksportjobb
En import- eller eksportjobb kan kjøres én eller flere ganger.
Definer prosjektkategori
Vi anbefaler at du tar deg tid til å velge en passende prosjektkategori for import- eller eksportjobben. Prosjektkategorier kan hjelpe deg å håndtere tilknyttede jobber.
Identifiser enhetene som skal importeres eller eksporteres
Du kan legge til spesifikke enheter for en import- eller eksportjobb eller velge en mal å bruke. Maler fyller en jobb med en liste over enheter. Alternativet Bruk mal er tilgjengelig etter at du har gitt jobben et navn og lagret jobben.
Sett dataformatet for jobben
Når du velger et foretak, må du velge formatet for dataene som skal eksporteres eller importeres. Du kan definere formatet ved å bruke Oppsett for datakilder-flisen. Et kildedataformat er en kombinasjon av type, filformat, radskilletegn og kolonneskilletegn. Det finnes andre, men disse attributtene er de viktigste attributtene å forstå. I tabellen nedenfor finner du en oversikt over gyldige kombinasjoner.
| Filformat | Rad-/kolonneskilletegn | XML-stil |
|---|---|---|
| Excel | Excel | -NA- |
| XML | -NA- | XML-attributt for XML-element |
| Skilletegn, fastsatt bredde | Komma, semikolon, tab, loddrett strek, kolon | -NA- |
Obs!
Det er viktig å velge riktig verdi for Radskilletegn, Kolonneskilletegn og Tekstkvalifikator hvis Filformat-alternativet er satt til Avgrenset. Kontroller at dataene ikke inneholder tegnet som brukes som skilletegn eller kvalifikator, da dette kan føre til feil under import og eksport.
Notat
For XML-baserte filformater må du huske å bare bruke lovlige tegn. Hvis du vil ha mer informasjon om gyldige tegn, kan du se Gyldige tegn i XML 1.0. XML 1.0 tillater ikke kontrolltegn, bortsett fra faner, vognreturer og linjeskift. Eksempler på ulovlige tegn er klammeparenteser, parenteser og skråstreker.
Bruk Unicode i stedet for en bestemt tegntabell til å importere eller eksportere data. Dette bidrar til de mest konsistente resultatene og forhindrer at dataadministrasjonsjobber mislykkes fordi de inneholder Unicode-tegn. De systemdefinerte kildedataformatene som bruker Unicode, har alle Unicode i kildenavnet. Du bruker Unicode-formatet ved å velge en UNICODE-kodende ANSI-tegntabell som Tegntabell i fanen Regionale innstillinger. Velg en av de følgende tegntabellene for Unicode:
| Tegntabell | Visningsnavn |
|---|---|
| 1200 | Unicode |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
Hvis du vil ha mer informasjon om tegntabeller, kan du se Identifikatorer for tegntabell.
Sekvenser enhetene
Enheter kan sekvenseres i et dataskjema, eller i import- og eksportjobber. Når du kjører en jobb som inneholder mer enn én dataenhet, må du sørge for at dataenhetene er riktig sekvensert. Du sekvenserer enhetene primært for å adressere noen funksjonelle avhengigheter mellom enheter. Hvis enheter ikke har noen funksjonelle avhengigheter, kan de planlegges for parallell import eller eksport.
Utføringsenheter, nivåer og sekvenser
Utføringsenheten, nivået i kjøringsenheten og sekvensen av en enhet, hjelper til med å kontrollere rekkefølgen dataene blir eksportert eller importert i.
- Enheter i hver utførelsesenheter behandles parallelt.
- I hver utførelsesenhet behandles enheter parallelt, hvis de har samme nivå.
- I hvert nivå behandles enheter i henhold til deres sekvensnummer i det nivået.
- Etter at ett nivå er behandlet, behandles det neste nivået.
Endre sekvens
Du vil kanskje endre sekvensen for dine enheter i følgende situasjoner:
- Hvis bare én datajobb brukes for alle endringene dine, kan du bruke alternativet for å endre sekvens for å optimalisere utføringstiden for hele jobben. I disse tilfellene kan du bruke utføringsenheten til å representere modulen, nivået som representerer funksjonsområdet i modulen, og sekvensen som representerer enheten. Ved å bruke denne tilnærmingen, kan du jobbe på tvers av moduler parallelt, men du kan fortsatt jobbe i sekvens i en modul. For å sikre at parallelle operasjoner lykkes, må du vurdere alle avhengigheter.
- Hvis flere dataposter brukes (for eksempel en jobb for hver modul), kan du bruke sekvensering for å påvirke nivået og rekkefølgen av enheter for optimal utførelse.
- Hvis det ikke er noen avhengighet i det hele tatt, kan du sekvensere enheter ved forskjellige utførelsesenheter for optimal optimalisering.
Menyen Endre sekvens er tilgjengelig når flere enheter er valgt. Du kan endre sekvens basert på eksekveringsenhet, nivå eller sekvensalternativer. Du kan angi en økning for å endre sekvens for enhetene som er valgt. Enhets-, nivå- og/eller sekvensnummeret valgt for hver enhet oppdateres av angitt økning.
Sortering
Du kan bruke alternativet Sorter etter for å vise enhetslisten i sekvensiell rekkefølge.
Avkorting
Du kan velge å avkorte poster i enheter før import for importprosjekter. Avkorting er nyttig hvis postene må importeres til et rent sett med tabeller. Denne innstillingen er av som standard.
Bekreft at kildedataene og måldataene er kartlagt riktig
Tilordning er en funksjon som gjelder for både import- og eksportjobber.
- I sammenheng med en importjobb beskriver tilordning hvilke kolonner i kildefilen som blir kolonnene i staging-tabellen. Derfor kan systemet bestemme hvilke kolonnedata i kildefilen som skal kopieres inn i hvilken kolonne på staging-tabellen.
- I sammenheng med en eksportjobb beskriver tilordning hvilke kolonner av staging-tabellen (det vil si kilden) som blir kolonnene i målfilen.
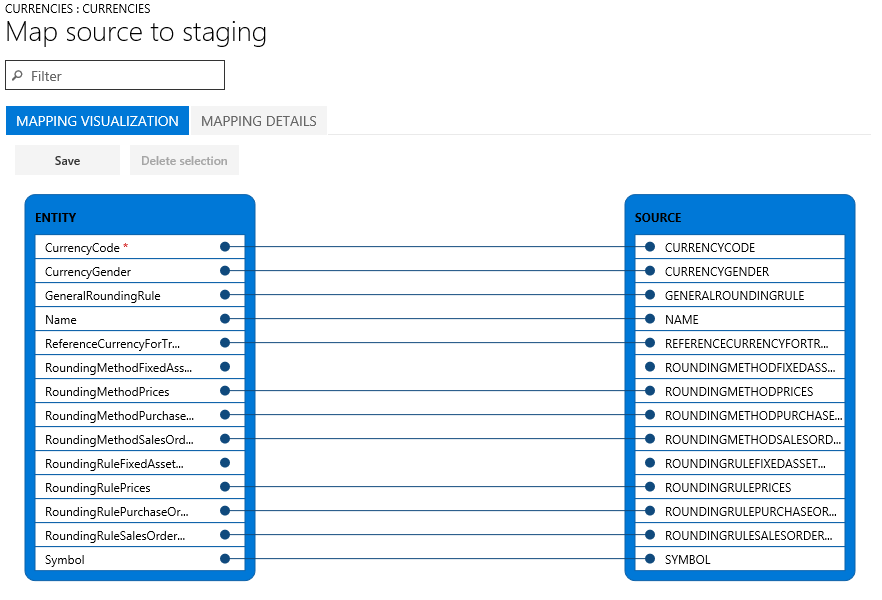
Hvis kolonnene i staging-tabellen og filen matcher, etablerer systemet automatisk tilordningen, basert på navnene. Men hvis navnene er forskjellige, tilordnes ikke kolonner automatisk. I disse tilfellene må du fullføre tilordningen ved å velge Vis tilordning-alternativet for enheten i datajobben.
Det er to tilordningsvisninger: Tilordningsvisualisering, som er standard visning, og Tilordningsdetaljer. En rød stjerne (*) identifiserer eventuelle obligatoriske felt i enheten. Disse feltene må tilordnes før du kan jobbe med enheten. Du kan frakoble andre felt som du trenger når du jobber med enheten. For å frakoble et felt, velg feltet i enten kolonnen Enhet eller kolonnen Kilde, og velg deretter Slett utvalg. Velg Lagre for å lagre endringene dine, og lukk deretter siden for å gå tilbake til prosjektet. Du kan bruke samme prosess for å redigere tilordning av felt fra kilde til oppstart etter importen.
Du kan generere en tilordning på siden ved å velge Generer kildetilordning. En generert tilordning oppfører seg som en automatisk tilordning. Derfor må du manuelt tilordne alle felt som ikke er tilordnet.
Bekreft sikkerheten for import- eller eksportjobben
Tilgang til arbeidsområdet Dataadministrasjon kan være begrenset, så ikke-administratorbrukere kan kun ha tilgang til spesifikke datajobber. Tilgang til et datajobb innebærer full tilgang til utførelsesloggen for den jobben og tilgang til staging-tabellene. Derfor må du sørge for at det er riktig tilgangskontroll på plass når du oppretter en datajobb.
Sikre en jobb med regler og brukere
Bruk menyen Tilgangsroller for å begrense jobben til en eller flere sikkerhetsroller. Kun brukere i disse rollene har tilgang til jobben.
Du kan også begrense en jobb til spesifikke brukere. Når du sikrer en jobb ved brukere i stedet for med roller har du mer kontroll hvis flere brukere er tildelt en rolle.
Sikre en jobb av juridisk enhet
Datajobber er globale av natur. Derfor, hvis en datajobb ble opprettet og brukt i en juridisk enhet, er jobben synlig i andre juridiske enheter i systemet. Denne standardoppførelsen kan foretrekkes i enkelte applikasjonsscenarier. For eksempel kan en organisasjon som importerer fakturaer ved hjelp av dataenheter gi et sentralisert fakturabehandlingslag som har ansvaret for å håndtere fakturafeil for alle divisjoner i organisasjonen. I dette scenariet er det nyttig for det sentraliserte fakturabehandlingsteam å få tilgang til fakturaimport av jobber fra alle juridiske enheter. Derfor oppfyller standardoppførselen kravet fra et juridisk enhetsperspektiv.
En organisasjon vil imidlertid kanskje ha fakturabehandlingsteam per juridisk enhet. I dette tilfellet bør et team i en juridisk enhet kun ha tilgang til fakturaimportjobben i sin egen juridiske enhet. For å oppfylle dette kravet kan du konfigurere juridisk enhetsbasert tilgangskontroll på datajobbene ved å bruke menyen Tilgang for juridiske enheter i jobben. Etter at konfigurasjonen er ferdig, kan brukerne bare se jobber som er tilgjengelige i den juridiske enheten som de er logget på. For å se jobber fra en annen juridisk enhet, må brukerne bytte til den juridiske enheten.
En jobb kan sikres av roller, brukere og juridiske enheter samtidig.
Kjør import- eller eksportjobben
Du kan kjøre en jobb én gang ved å velge Import eller Eksport-knappen etter at du har definert jobben. For å sette opp gjentakende jobber, velg Opprett gjentakende datajobb.
Notat
En import- eller eksportjobb kan kjøres ved å velge Import- eller Eksport-knappen. Denne handlingen planlegger en satsvis jobb slik at den bare kjører én gang. Jobben utføres kanskje ikke umiddelbart hvis satsvis tjeneste begrenses på grunn av belastningen på den satsvise tjenesten. Jobbene kan også kjøres synkront ved å velge Importer nå eller Eksporter nå. Dette starter jobben umiddelbart og er nyttig hvis den satsvise jobben ikke starter på grunn av begrensning. Jobbene kan også planlegges slik at de kjøres på et senere tidspunkt. Du kan gjøre dette ved å velge alternativet Kjør satsvis. Satsvise ressurser er underlagt begrensning, slik at den satsvise jobben kanskje ikke starter umiddelbart. Det anbefales at du bruker en satsvis jobb, fordi det også hjelper med store datamengder som må importeres eller eksporteres. Satsvise jobber kan planlegges til å kjøre på en bestemt satsvis gruppe, som gir mer kontroll fra et perspektiv for belastningsfordeling.
Bekreft at jobben kjørte som forventet.
Jobbhistorikken er tilgjengelig for feilsøking og etterforskning på både import- og eksportjobber. Historiske jobber er organisert av tidsintervall.
Hver jobbkjøring gir følgende detaljer:
- Utførelsesdetaljer
- Utførelseslogg
Utførelsesdetaljer viser status for hver dataenheter som jobben behandlet. Derfor kan du raskt finne følgende informasjon:
- Enhetene som ble behandlet.
- Hvor mange oppføringer som ble behandlet og hvor mange som mislyktes for en enhet.
- De oppsamlede oppføringene for hver enhet.
Du kan laste ned staging-dataene i en fil for eksportjobber, eller du kan laste den ned som en pakke for import- og eksportjobber.
Fra utførelsesdetaljene kan du også åpne utførelsesloggen.
Parallelle importer
Hvis du vil importere data raskere, kan parallell behandling av importering av filer aktiveres hvis enheten støtter parallelle importer. Hvis du vil konfigurere den parallelle importen for en enhet, må du følge trinnene nedenfor.
Gå til Systemadministrasjon > Arbeidsområder > Dataadministrasjon.
I delen Import/eksport velger du kategorien Rammeverkparametere for å åpne siden Rammeverkparametere for dataimport/-eksport.
I kategorien Enhetsinnstillinger velger du Konfigurer parametere for utføring av enhet for å åpne siden Parametere for utføring av enhetsimport.
Angi følgende felt for å konfigurere parallell import for en enhet:
- Velg enheten i Enhet-feltet. Hvis enhetsfeltet er tomt, brukes den tomme verdien som standardinnstilling for alle etterfølgende importer, hvis enheten støtter parallell import.
- Angi antall poster for importterskel i feltet Antall poster for importterskel. Dette bestemmer antallet poster som skal behandles av en tråd. Hvis en fil har 10 K poster, betyr et postantall på 2500 med et oppgaveantall på fire at hver tråd behandler 2500 poster.
- I feltet Antall importoppgaver angir du antallet importoppgaver. Antallet må ikke overskride maksimalt antall bunketråder som er tilordnet for satsvis behandling i Systemadministrasjon >Serverkonfigurasjon.
Obs!
Hvis du legger til for mange parallelle aktiviteter, bruker den underliggende infrastrukturen ressurskapasiteten på 100 % og påvirker miljøet, ytelsen og andre operasjoner. Det anbefales at du forstår ressurskapasiteten til miljøet og forbruket basert på de parallelle importoppgavene som er konfigurert, og begrenser antall aktiviteter.
Opprydding i jobblogg
Som standard slettes automatisk jobbhistorikkoppføringer og relaterte oppsamlingstabelldata som er eldre enn 90 dager. Funksjonaliteten for opprydding i logg i dataadministrasjon kan brukes til å konfigurere periodisk opprydding av kjøreloggen med en lavere oppbevaringsperiode enn denne standarden. Denne funksjonaliteten erstatter den tidligere oppryddingsfunksjonaliteten for oppsamlingstabellen, som nå er foreldet. De følgende tabellene vil bli fjernet av oppryddingsprosessen.
Alle oppsamlingstabeller
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
DMFSTAGINGLOG
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
Funksjonen Opprydding i utførelseshistorikk er tilgjengelig fra Dataadministrasjon > Opprydding i jobblogg.
Planleggingsparametere
Når du planlegger oppryddingsprosessen, må du angi følgende parametere for å definere oppryddingsskriteriene.
Antall dager for å beholde loggen – denne innstillingen brukes til å kontrollere hvor mye av kjøringsloggen som skal beholdes. Loggen angis i antall dager. Når oppryddingsjobben er planlagt som en gjentakende satsvis jobb, fungerer denne innstillingen som et kontinuerlig bevegelig vindu, og dermed blir loggen for det angitte antallet dager intakt mens du sletter resten. Standardverdien er sju dager.
Antall timer for å utføre jobben – avhengig av hvor mye av historikken som skal ryddes opp, kan den totale utførelsestiden for oppryddingsjobben variere fra noen få minutter til noen timer. Denne parameteren må settes til antall timer som jobben utføres. Når oppryddingsjobben er utført for det angitte antallet timer, avsluttes jobben og fortsetter oppryddingen neste gang den kjøres basert på tidsplanen for regelmessighet.
Du kan angi maksimal utførelsestid ved å angi en maksimumsgrense for antall timer jobben må kjøres med denne innstillingen. Oppryddingslogikken går gjennom én jobbutførelses-ID om gangen i en kronologisk ordnet rekkefølge, med eldste først for opprydding av relatert kjøreloggen. Den slutter å hente nye kjøre-ID-er for opprydding når den resterende kjørevarigheten er innen de siste 10 % av den spesifiserte varigheten. I noen tilfeller fortsetter oppryddingsjobben utover den angitte maksimumstiden. Denne varigheten avhenger i stor grad av antall poster som skal slettes for nåværende utførelses-ID som ble startet før grensen på 10 % ble nådd. Oppryddingen som ble startet, må fullføres for å sikre dataintegritet, noe som betyr at oppryddingen fortsetter til tross for overskridelse av den angitte grensen. Når dette er fullført, hentes ikke nye utførelses-ID-er, og oppryddingsjobben fullføres. Den gjenstående utførelsesloggen som ikke ble ryddet opp på grunn av mangel på nok utførelsestid, blir plukket opp neste gang oppryddingsjobben er planlagt. Standard- og minimumsverdien for denne innstillingen er satt til 2 timer.
Gjentakende parti – oppryddingsjobben kan kjøres som en engangskjøring manuelt, eller den kan også planlegges for gjentakende kjøring satsvis. Den satsvise jobben kan planlegges ved hjelp innstillingene for kjøring i bakgrunnen, som er standardpartiet som er satt opp.
Obs!
Hvis funksjonen Opprydding i jobblogg ikke brukes, blir fortsatt en utførelseslogg som er eldre enn 90 dager, slettet automatisk. Opprydding i jobblogg kan kjøres i tillegg til denne automatiske slettingen. Kontroller at oppryddingsjobben er planlagt til å kjøres i gjentakelse. Som forklart ovenfor, rydder jobben bare opp så mange utførelses-ID-er som mulig i løpet av de angitte maksimale timene, i alle oppryddingskjøringer.
Opprydding og arkivering av jobbhistorikk
Funksjonen for opprydding i og arkivering av jobblogg erstatter de tidligere versjonene av oppryddingsfunksjonen. Denne delen forklarer disse nye funksjonene.
En av hovedendringene i oppryddingsfunksjonen er bruken av systemets satsvise jobb for å rydde opp i loggen. Bruken av systemets satsvise jobb gjør at økonomi- og driftsapper kan få den satsvise jobben for opprydding planlagt automatisk så snart systemet er klart. Det er ikke lenger nødvendig å planlegge den satsvise jobben manuelt. I denne standardmodusen for kjøring kjøres den satsvise jobben hver time fra midnatt, og kjøringsloggen for de siste sju dagene beholdes. Den tømte loggen arkiveres for fremtidig henting. Fra og med versjon 10.0.20 er denne funksjonen alltid på.
Den andre endringen i oppryddingsprosessen er arkivering av den tømte kjøringsloggen. Oppryddingsjobben arkiverer de slettede postene i BLOB-lageret som DIXF bruker til vanlige integreringer. Den arkiverte filen er i DIXF-pakkeformatet, og er tilgjengelig i sju dager i BLOB-lageret, der det kan lastes ned. Standardlevetiden på sju dager for den arkiverte filen kan endres til maksimalt 90 dager i parameterne.
Endre standardinnstillingene
Denne funksjonen er for øyeblikket en forhåndsversjon, og du må aktivere den eksplisitt ved å aktivere testversjonen DMFEnableExecutionHistoryCleanupSystemJob. Oppsamlingsfunksjonen for opprydding må også være aktivert i funksjonsbehandling.
Hvis du vil endre standardinnstillingen for levetiden til den arkiverte filen, går du til arbeidsområdet for dataadministrasjon og velger Opprydding i jobblogg. Sett Antall dager å beholde pakke i BLOB til en verdi mellom 7 og 90 (inklusiv). Denne endringen trer i kraft for arkivene som er opprettet etter at denne endringen ble gjort.
Laste ned den arkiverte pakken
Denne funksjonen er for øyeblikket en forhåndsversjon, og du må aktivere den eksplisitt ved å aktivere testversjonen DMFEnableExecutionHistoryCleanupSystemJob. Oppsamlingsfunksjonen for opprydding må også være aktivert i funksjonsbehandling.
Hvis du vil laste ned den arkiverte kjøringsloggen, går du til arbeidsområdet for dataadministrasjon og velger Opprydding i jobblogg. Velg Logg for sikkerhetskopiering av pakke for å åpne loggskjemaet. Dette skjemaet viser listen over alle arkiverte pakker. Du kan velge og laste ned et arkiv ved å velge Last ned pakke. Den nedlastede pakken er i DIXF-pakkeformatet og inneholder følgende filer:
- Oppsamlingstabellfilen for enheter
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- DMFSTAGINGLOG
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG
Sorter sammensatte enhetsdata ved hjelp av xslt
Med denne funksjonaliteten kan du eksportere en sammensatt enhet og bruke xslt-fil til å sortere dataene i XML-fil.
Hvis du vil sortere sammensatte enhetsdata ved hjelp av xslt, gjør du følgende.
- Opprett en xslt-fil for å sortere dataene i XML-format. Hvis du for eksempel har en XSLT-fil for den medfølgende enheten Sammensatte bestillinger V3, kan du sortere XML-attributtformatdataene i rekkefølge etter INVOICEVENDORACCOUNTNUMBER for PURCHPURCHASEORDERHEADERV2ENTITY og sortere etter LINENUMBER for PURCHPURCHASEORDERLINEV2ENTITY.
<xsl:stylesheet version='1.0' xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/*">
<xsl:copy>
<xsl:apply-templates select="@*" />
<xsl:apply-templates>
<xsl:sort select="@INVOICEVENDORACCOUNTNUMBER" data-type="text" order="ascending" />
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="PURCHPURCHASEORDERHEADERV2ENTITY">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="*">
<xsl:sort select="@LINENUMBER" data-type="number" order="descending"/>
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
- Gå til arbeidsområdet Databehandling.
- Fra listen over dataeksportprosjekter velger du et prosjekt med XML-datakilde og velger Vil tildeling.
- Velg Vis tildeling for en hvilken som helst enhet.
- Gå til fanen Transformasjoner
- Velg Ny, og last opp xslt-filen som ble opprettet i trinn 1.