Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Microsoft Fabrics API for GraphQL tilbyr en kraftig måte å spørre etter data effektivt på, men ytelsesoptimalisering er nøkkelen til å sikre jevn og skalerbar ytelse. Enten du håndterer komplekse spørringer eller optimaliserer responstider, hjelper følgende anbefalte fremgangsmåter deg med å få best mulig ytelse ut av GraphQL-implementeringen og maksimere API-effektiviteten i Fabric.
Hvem trenger ytelsesoptimalisering
Ytelsesoptimalisering er avgjørende for:
- Applikasjonsutviklere som bygger applikasjoner med høy trafikk som spør Fabric lakehouses og lagre
- Dataingeniører som optimaliserer Fabric-dataaksessmønstre for storskala analyseapplikasjoner og ETL-prosesser
- Fabric workspace-administratorer styrer kapasitetsforbruk og sikrer effektiv ressursutnyttelse
- BI-utviklere som forbedrer responstidene for tilpassede analyseapplikasjoner bygget på Fabric-data
- DevOps-team som feilsøker forsinkelsesproblemer i produksjonsapplikasjoner som bruker Fabric-API-er
Bruk disse beste praksisene når GraphQL-API-et ditt trenger å håndtere produksjonsarbeidsbelastninger effektivt eller når du opplever ytelsesproblemer.
Regionjustering
API-kall på tvers av regioner er en vanlig årsak til høy forsinkelse. For optimal ytelse, sørg for at klientapplikasjonene, Fabric-leietakeren, kapasiteten og datakildene alle befinner seg i samme Azure-region.
Sjekk leietakerregionen din
For å finne din tekstilleietakers region:
- Logg inn på Microsoft Fabric-portalen med en administratorkonto
- Velg Hjelp-ikonet (?) øverst til høyre
- Nederst i Hjelp-panelet, velg Om Stoff
- Merk regionen som vises i leietakerdetaljene
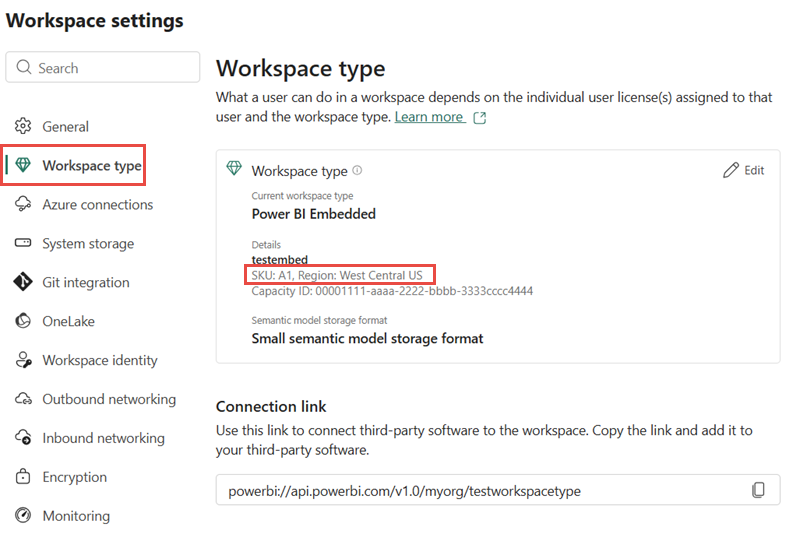
Sjekk kapasitetsområdet ditt
API-et ditt for GraphQL kjører innenfor en spesifikk kapasitet. For å finne kapasitetsområdet:
Åpne arbeidsområdet som hoster API-et ditt for GraphQL
Gå til Arbeidsområdeinnstillinger>Arbeidsområdetype
Finn regionen under lisenskapasitet

Sjekk datakilderegionen din
Plasseringen av datakildene dine påvirker også ytelsen:
- Fabric-datakilder (Lakehouse, Data Warehouse, SQL Database): Disse bruker samme region som arbeidsområdets kapasitet
- Eksterne datakilder (Azure SQL Database, osv.): Sjekk ressursplasseringen i Azure-portalen
Beste praksis: Distribuer klientapplikasjoner i samme region som din Fabric-kapasitet og datakilder for å minimere nettverksforsinkelse.
Beste praksis for ytelsestesting
Når du vurderer API-ens ytelse, følg disse retningslinjene for pålitelige og konsistente resultater.
Bruk realistiske testverktøy
Test med verktøy som matcher produksjonsmiljøet ditt tett:
- Skript eller applikasjoner: Bruk Python-, Node.js- eller .NET-skript som simulerer faktisk klientatferd
- HTTP-tilkoblingspooling: Gjenbruk HTTP-tilkoblinger for å redusere latens, spesielt viktig for situasjoner på tvers av regioner
- Sesjonshåndtering: Oppretthold økter på tvers av forespørsler for å nøyaktig gjenspeile bruk i virkeligheten
Eksempler på ressurser:
- Eksempel på ytelsestestskript (Python-notatbok)
- HTTP-sesjonsobjekter i Python
- HttpClient-retningslinjer for .NET
Samle meningsfulle måleparametere
For nøyaktig prestasjonsvurdering:
- Automatiser testing: Bruk skript eller ytelsestestverktøy for å kjøre tester konsekvent over en definert periode
- Varm opp API-et: Kjør flere testspørringer før du måler ytelsen (se Oppvarmingskrav)
- Analyser fordelinger: Bruk prosentilbaserte metrikker (P50, P95, P99) i stedet for bare gjennomsnitt for å forstå latensmønstre
- Test under belastning: Mål ytelse med realistiske samtidige forespørslingsvolumer
- Dokumentbetingelser: Registrer tidspunkt på dagen, kapasitetsutnyttelse og eventuelle samtidige arbeidsbelastninger under testing
Vanlige ytelsesproblemer
Å forstå disse vanlige problemene hjelper deg å diagnostisere og løse ytelsesproblemer effektivt.
Oppvarmingskrav
Problem: Den første API-forespørselen tar betydelig lengre tid enn påfølgende forespørsler.
Hvorfor dette skjer:
- API-initialisering: Når API-miljøet er inaktivt, må det initialisere under det første kallet, noe som legger til noen sekunder med forsinkelse
- Oppvarming av datakilde: Mange datakilder (spesielt SQL Analytics Endpoints og datavarehus) gjennomgår en oppvarmingsfase når de aksesseres etter å ha vært inaktive
- Kombinert initialisering: Hvis både API-et og datakilden er inaktive, akkumuleres initialiseringstidene
Løsning:
- Utfør 2-3 testspørringer før du måler ytelsen
- For produksjonsapplikasjoner, implementer helsesjekkendepunkter som holder API-et varmt
- Vurder å bruke planlagte spørringer eller overvåkingsverktøy for å opprettholde en aktiv tilstand i åpningstiden.
Regional feiljustering
Problem: Konsekvent høy latens på tvers av alle forespørsler.
Hvorfor dette skjer: Nettverkskall på tvers av regioner legger til betydelig forsinkelse, spesielt når klient, API og datakilder befinner seg i forskjellige Azure-regioner.
Løsning:
- Verifiser at klientapplikasjonen, Fabric-kapasiteten og datakildene dine er i samme region
- Hvis tilgang på tvers av regioner er uunngåelig, implementer aggressive caching-strategier
- Vurder å distribuere regionale API-replikaer for globale applikasjoner
Datakildeytelse
Problem: API-forespørsler er trege selv når API-et er varmet opp og regionene er justert.
Hvorfor dette skjer: API for GraphQL fungerer som et spørringsgrensesnitt over datakildene dine. Hvis den underliggende datakilden har ytelsesproblemer – som manglende indekser, komplekse spørringer eller ressursbegrensninger – arver API-et disse begrensningene.
Løsning:
- Test direkte: Spør datakilden direkte (ved bruk av SQL eller andre native verktøy) for å etablere en baseline-ytelse
-
Optimaliser datakilden:
- Legg til passende indekser for ofte forespurte kolonner
- Vurder riktig datalager for ditt brukstilfelle: Fabric-beslutningsguide – velg en datalagring
- Gå gjennom spørringsutførelsesplaner for optimaliseringsmuligheter
- Riktig størrelse kapasitet: Sørg for at Fabric-kapasitets-SKU-en din gir tilstrekkelige beregningsressurser. Se Microsoft Fabric-konsepter for veiledning om valg av passende kapasitet.
Spørringsdesign
Problem: Noen spørringer fungerer bra, mens andre er trege.
Hvorfor dette skjer:
- Overhenting: Å be om flere felt enn nødvendig øker behandlingstiden
- Dyp nesting: Spørringer med mange nivåer av nestede relasjoner krever flere resolver-kjøringer
- Manglende filtre: Spørringer uten passende filtre kan gi for mye data
Løsning:
- Be kun om feltene du trenger i GraphQL-spørringen din
- Begrens dybden av nestede relasjoner der det er mulig
- Bruk passende filtre og paginering i spørringene dine
- Vurder å dele komplekse spørringer opp i flere enklere spørringer når det er hensiktsmessig