Obs!
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
I denne opplæringen kan du lære hvordan du leser/skriver data inn i Fabric Lakehouse med en notatblokk. Fabric støtter Spark API og Pandas API er å nå dette målet.
Laste inn data med en Apache Spark-API
Bruk følgende kodeeksempel i kodecellen i notatblokken til å lese data fra kilden og laste dem inn i Filer, Tabeller eller begge delene av lakehouse.
Hvis du vil angi plasseringen du vil lese fra, kan du bruke den relative banen hvis dataene er fra standard lakehouse i gjeldende notatblokk. Hvis dataene er fra et annet lakehouse, kan du også bruke den absolutte Azure Blob File System (ABFS)-banen. Kopier denne banen fra hurtigmenyen for dataene.
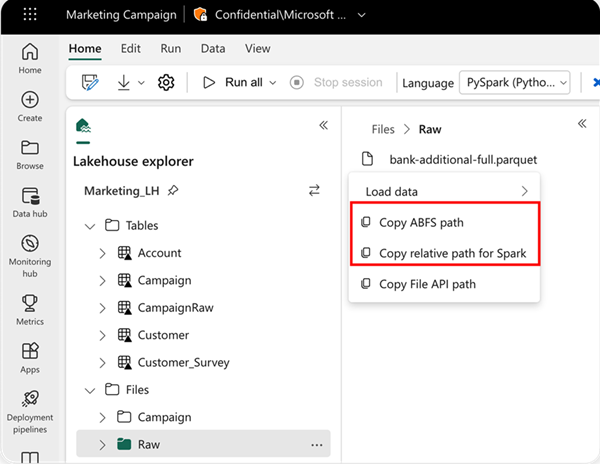
Kopier ABFS-bane: Dette alternativet returnerer den absolutte banen til filen.
Kopier relativ bane for Spark: Dette alternativet returnerer den relative banen til filen i standard lakehouse.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Laste inn data med Pandas API
For å støtte Pandas API monteres standard lakehouse automatisk i notatblokken. Monteringspunktet er /lakehouse/default/. Du kan bruke dette monteringspunktet til å lese/skrive data fra/til standard lakehouse. Alternativet Kopier fil-API-bane fra hurtigmenyen returnerer Fil-API-banen fra dette monteringspunktet. Banen som returneres fra alternativet Kopier ABFS-bane fungerer også for Pandas API.
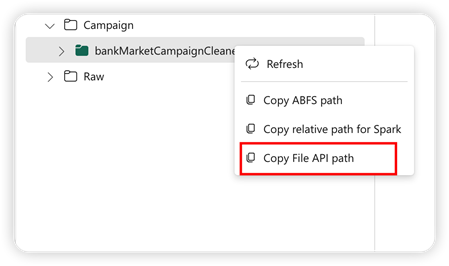
Kopier fil-API-bane: Dette alternativet returnerer banen under monteringspunktet for standard lakehouse.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Tips
For Spark API kan du bruke alternativet Kopier ABFS-bane eller Kopier relativ bane for Spark for å få banen til filen. For Pandas API kan du bruke alternativet Kopier ABFS-bane eller Kopier fil-API-bane for å hente banen til filen.
Den raskeste måten å få koden til å fungere med Spark API eller Pandas API på, er å bruke alternativet Last inn data og velge API-en du vil bruke. Koden genereres automatisk i en ny kodecelle i notatblokken.
