Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Microsoft Fabric er en integrert analysetjeneste som øker tiden til innsikt på tvers av datalagre og store datasystemer. Datavisualisering i notatblokker er en viktig funksjon som lar deg få innsikt i dataene dine, slik at brukerne enkelt kan identifisere mønstre, trender og ytterpunkter.
Når du arbeider med Apache Spark in Fabric, har du innebygde alternativer for visualisering av data, inkludert diagramfunksjoner for fabric-notatblokker og tilgang til populære biblioteker med åpen kildekode.
Med stoffnotatblokker kan du også konvertere tabellresultater til tilpassede diagrammer uten å skrive kode, noe som muliggjør en mer intuitiv og sømløs datautforskningsopplevelse.
Innebygd visualiseringskommando – display()-funksjon
Med den innebygde visualiseringsfunksjonen Fabric kan du transformere Apache Spark DataFrames, Pandas DataFrames og SQL-spørringsresultater til rike, interaktive datavisualiseringer.
Ved hjelp av visningsfunksjonen kan du gjengi PySpark og Scala Spark DataFrames eller Resilient Distributed Datasets (RDDs) som dynamiske tabeller eller diagrammer.
Du kan angi radantallet for datarammen som skal gjengis. Standardverdien er 1000. Notatblokk vise utdata-kontrollprogrammet støtter for å vise og profilere 10000 rader med en dataramme på det meste.

Du kan bruke filterfunksjonen på den globale verktøylinjen til å bruke tilpassede regler på dataene. Filterbetingelsen brukes på en angitt kolonne, og resultatene gjenspeiles både i tabell- og diagramvisningene.

Utdataene fra SQL-setningen bruker samme utdata-kontrollprogram med display() som standard.
Visning av rik datarammetabell
Støtte for gratisvalg i tabellvisning
Tabellvisningen gjengis som standard når du bruker kommandoen display() i en Fabric-notatblokk. Forhåndsvisningen av rik dataramme tilbyr en intuitiv funksjon for fritt valg, som er utformet for å forbedre dataanalyseopplevelsen ved å aktivere fleksible, interaktive valgalternativer. Denne funksjonen gjør det enkelt for brukere å navigere og utforske datarammer effektivt.
kolonnevalg
- enkel kolonne: Klikk kolonneoverskriften for å merke hele kolonnen.
- Flere kolonner: Når du har valgt én kolonne, trykker og holder du nede Skift-tasten og klikker deretter en annen kolonneoverskrift for å merke flere kolonner.
radvalg
- enkel rad: Klikk på en radoverskrift for å merke hele raden.
- flere rader: Når du har merket én rad, trykker og holder du nede SKIFT, og deretter klikker du en annen radoverskrift for å merke flere rader.
forhåndsvisning av celleinnhold: Forhåndsvis innholdet i enkeltceller for å få en rask og detaljert titt på dataene uten å måtte skrive ekstra kode.
kolonnesammendrag: Få et sammendrag av hver kolonne, inkludert datadistribusjon og nøkkelstatistikk, for raskt å forstå egenskapene til dataene.
valg av ledig område: Velg et hvilket som helst kontinuerlig segment av tabellen for å få en oversikt over de totale merkede cellene og de numeriske verdiene i det merkede området.
Kopier merket innhold: I alle utvalgstilfeller kan du raskt kopiere det merkede innholdet ved hjelp av snarveien Ctrl + C. De valgte dataene kopieres i CSV-format, noe som gjør det enkelt å behandle i andre programmer.

Støtte for dataprofilering via Undersøk-ruten

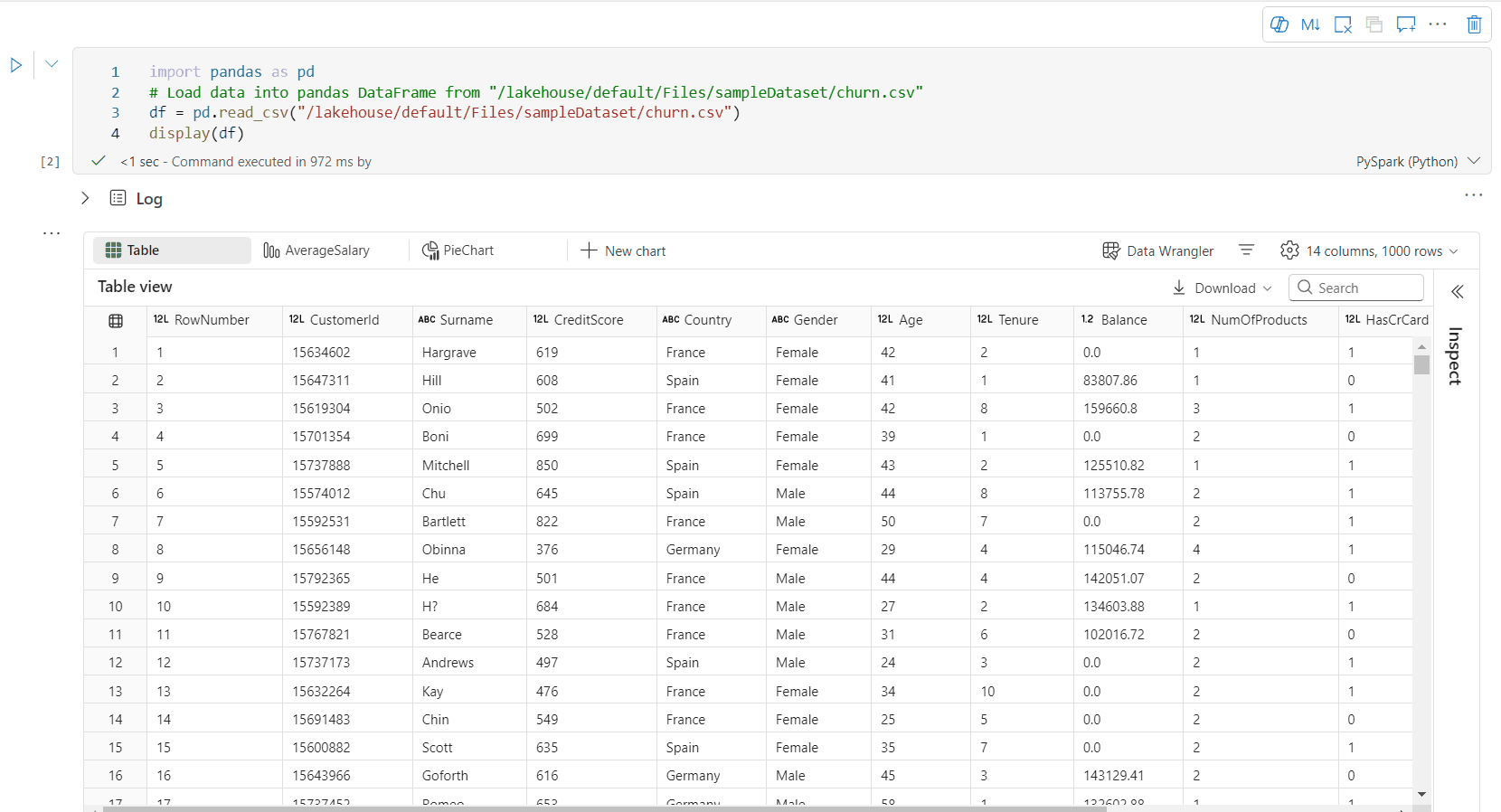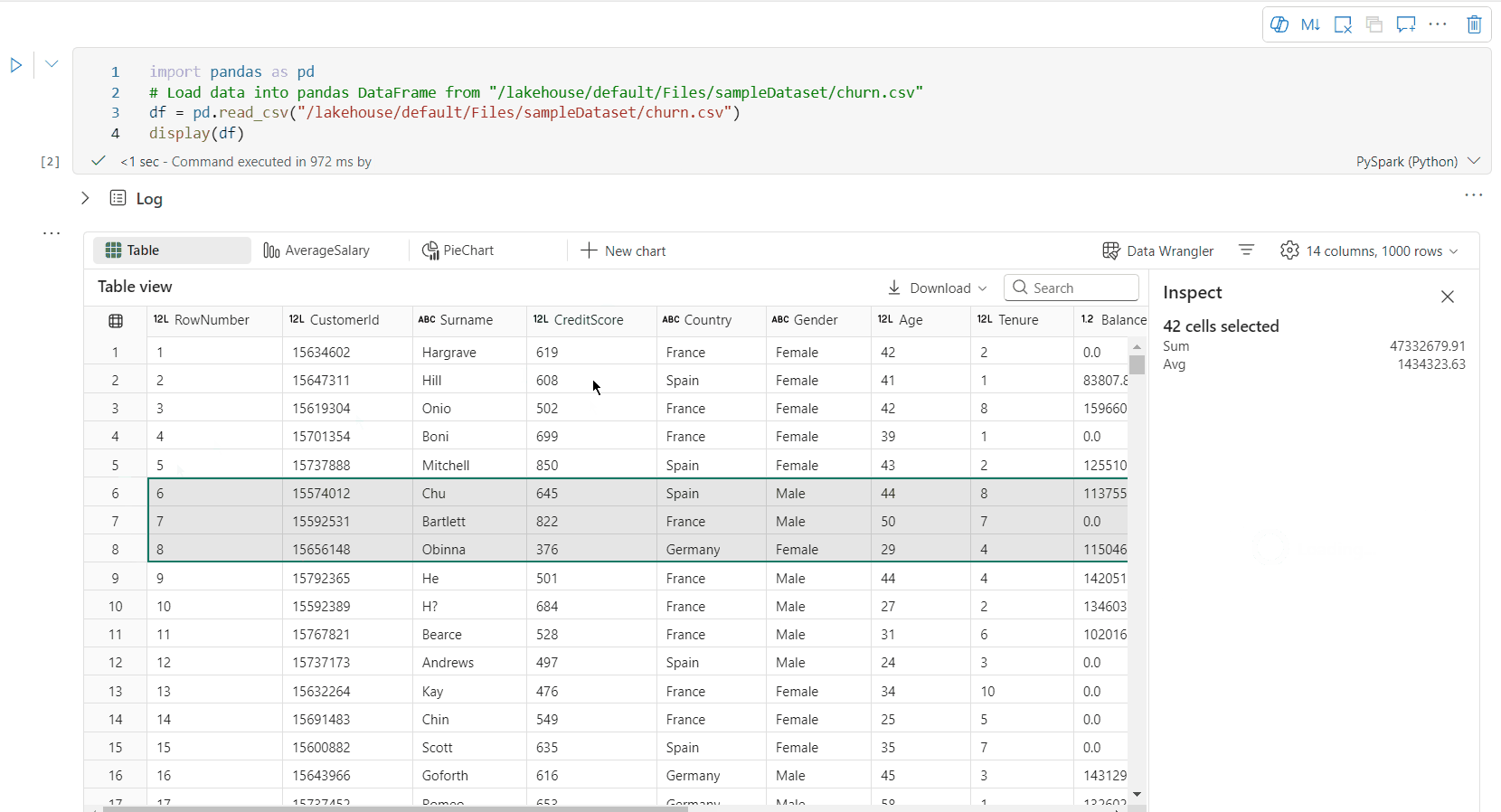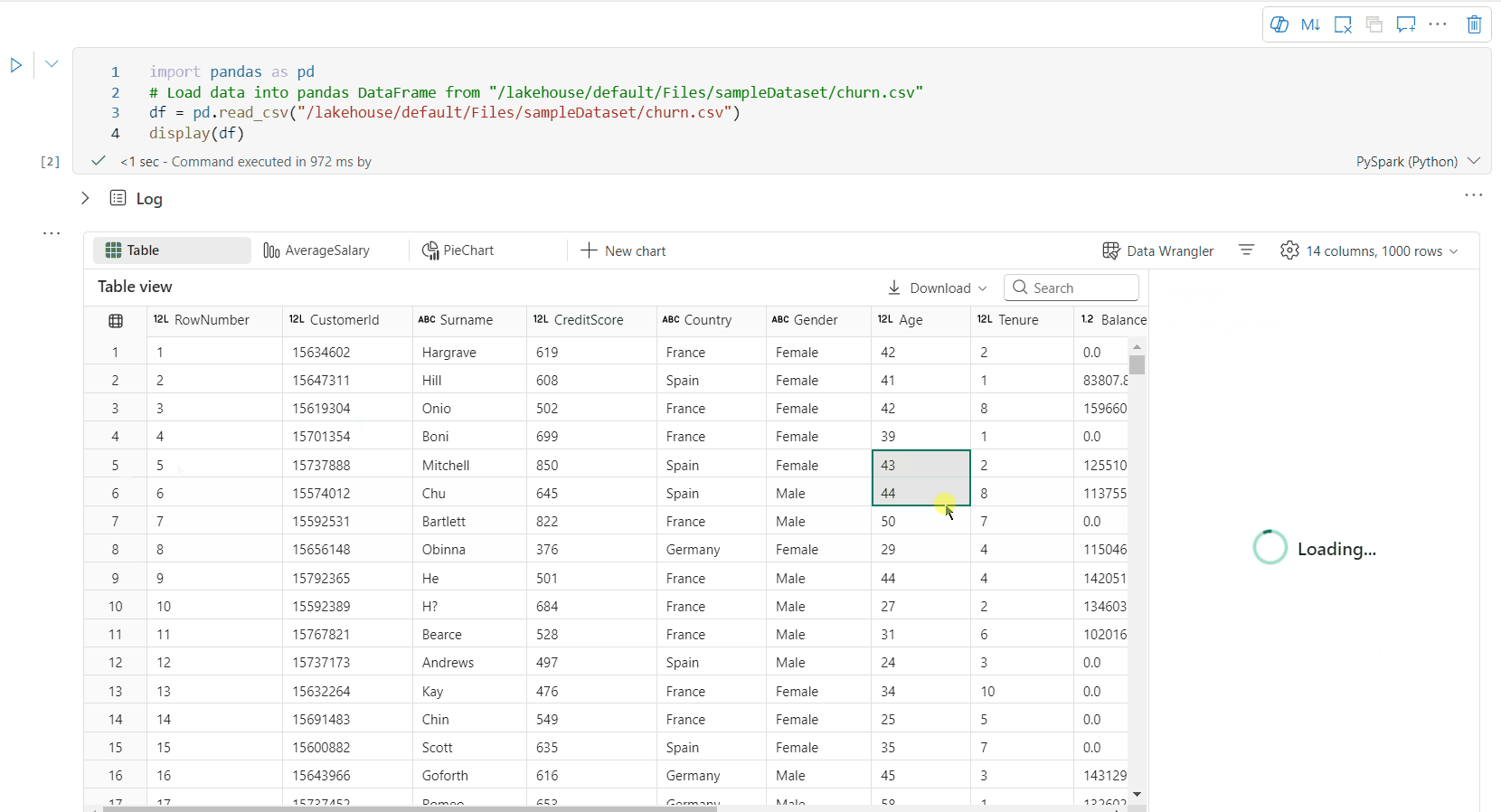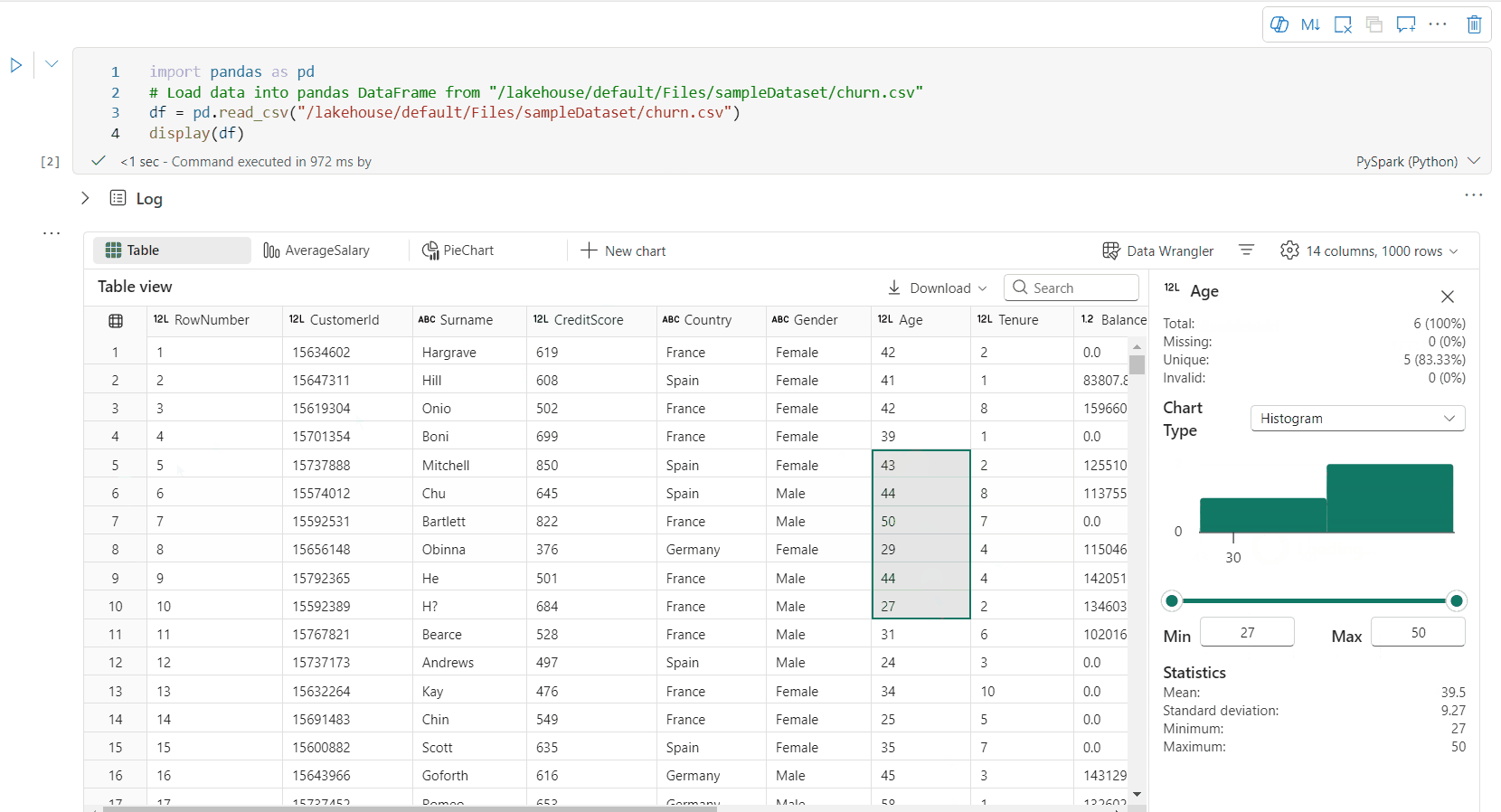
Du kan profilere datarammen ved å klikke Undersøk-knappen. Den gir den summerte datadistribusjonen og viser statistikk for hver kolonne.
Hvert kort i «Undersøk»-sideruten tilordnes til en kolonne i datarammen, du kan vise flere detaljer ved å klikke på kortet eller velge en kolonne i tabellen.
Du kan vise celledetaljene ved å klikke på cellen i tabellen. Denne funksjonen er nyttig når datarammen inneholder en lang strengtype med innhold.
Utvidet visning av rikt datarammediagram
Den forbedrede diagramvisningen i display() -kommandoen gir en mer intuitiv og dynamisk måte å visualisere dataene på.
Viktige forbedringer:
Støtte for flere diagrammer: Legg til opptil fem diagrammer i et enkelt kontrollprogram for visningsutdata ved å velge Nytt diagram, slik at det blir enklere sammenligninger på tvers av ulike kolonner.
Anbefalinger for smartdiagram: Få en liste over foreslåtte diagrammer basert på datarammen. Velg å redigere en anbefalt visualisering eller opprette et egendefinert diagram fra grunnen av.

Fleksibel tilpassing: Tilpass visualiseringene med justerbare innstillinger som tilpasses basert på den valgte diagramtypen.
Kategori Grunnleggende innstillinger Beskrivelse Diagramtype Visningsfunksjonen støtter et bredt spekter av diagramtyper, inkludert stolpediagrammer, punktplott, linjegrafer, pivottabell og mer. Stilling Stilling Tittelen på diagrammet. Stilling Undertittel Undertittelen på diagrammet med flere beskrivelser. Data X-akse Angi nøkkelen for diagrammet. Data Y-akse Angi verdiene i diagrammet. Forklaring Vis forklaring Aktiver/deaktiver forklaringen. Forklaring Posisjon Tilpass plasseringen av forklaringen. Annet Seriegruppe Bruk denne konfigurasjonen til å bestemme gruppene for aggregasjonen. Annet Aggregasjon Bruk denne metoden til å aggregere data i visualiseringen. Annet Stablet Konfigurer visningsstilen for resultatet. Annet Manglende og NULL-verdier Konfigurer hvordan manglende eller NULL-diagramverdier vises. Merk
I tillegg kan du angi antall rader som vises, med en standardinnstilling på 1000. Kontrollprogrammet for utdata for notatblokkvisning støtter visning og profilering av opptil 10 000 rader i en DataFrame. Velg Aggregasjon over alle resultatene , og velg deretter Bruk for å bruke diagramgenereringen fra hele datarammen. En Spark-jobb utløses når diagraminnstillingen endres. Det kan ta flere minutter å fullføre beregningen og gjengi diagrammet.
Kategori Avanserte innstillinger Beskrivelse Farge Tema Definer temafargesettet for diagrammet. X-akse Etikett Angi en etikett til X-aksen. X-akse Skala Angi skaleringsfunksjonen for X-aksen. X-akse Område Angi X-aksen for verdiområdet. Y-akse Etikett Angi en etikett til Y-aksen. Y-akse Skala Angi skaleringsfunksjonen for Y-aksen. Y-akse Område Angi Y-aksen for verdiområdet. Vis Vis etiketter Vis/skjul resultatetikettene i diagrammet. Endringene i konfigurasjonene trer i kraft umiddelbart, og alle konfigurasjonene lagres automatisk i notatblokkinnhold.
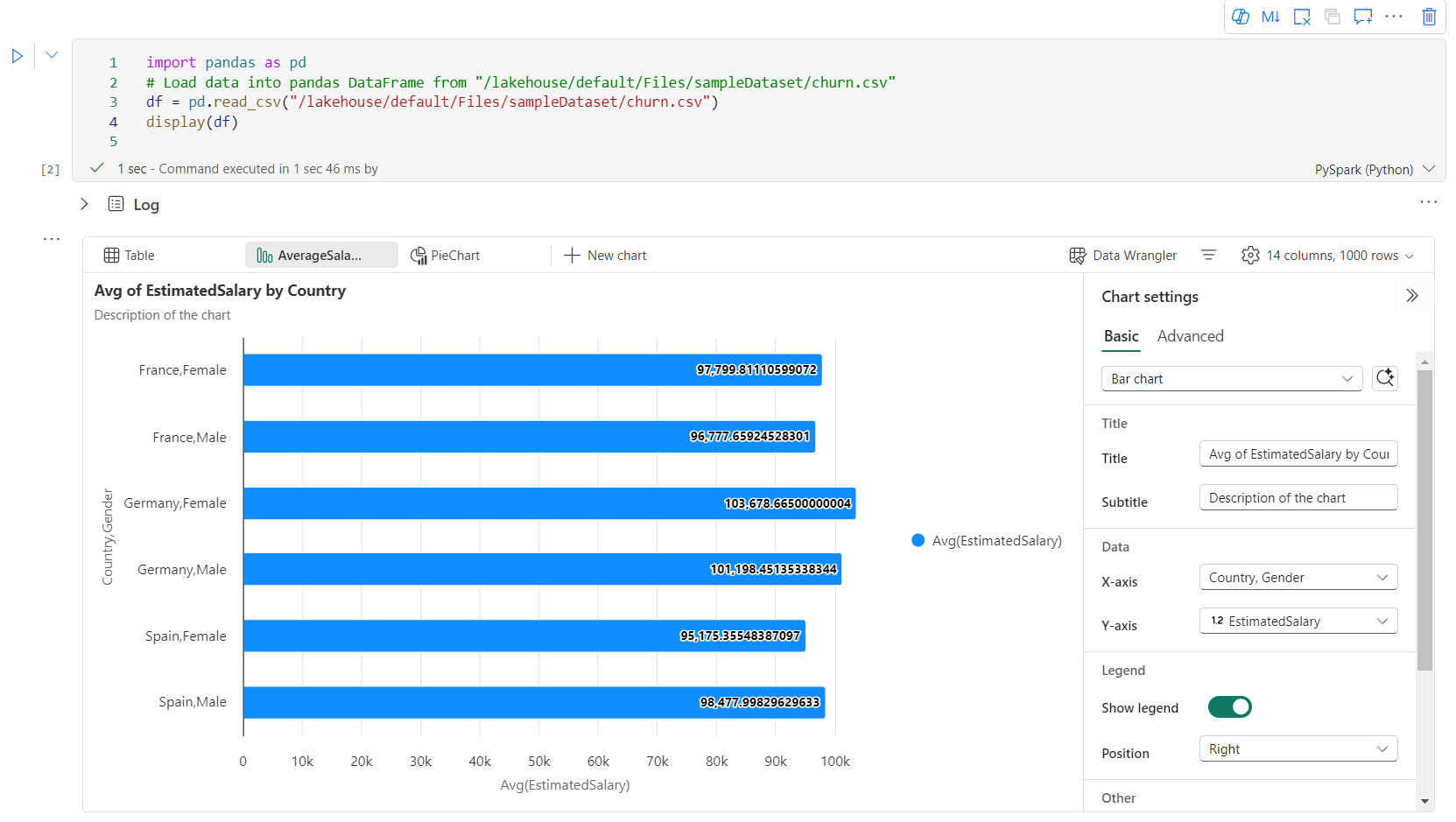
Du kan enkelt gi nytt navn til, duplisere, slette eller flytte diagrammer i diagramfanemenyen. Du kan også dra og slippe faner for å endre rekkefølgen på dem. Den første fanen vises som standard når notatblokken åpnes.
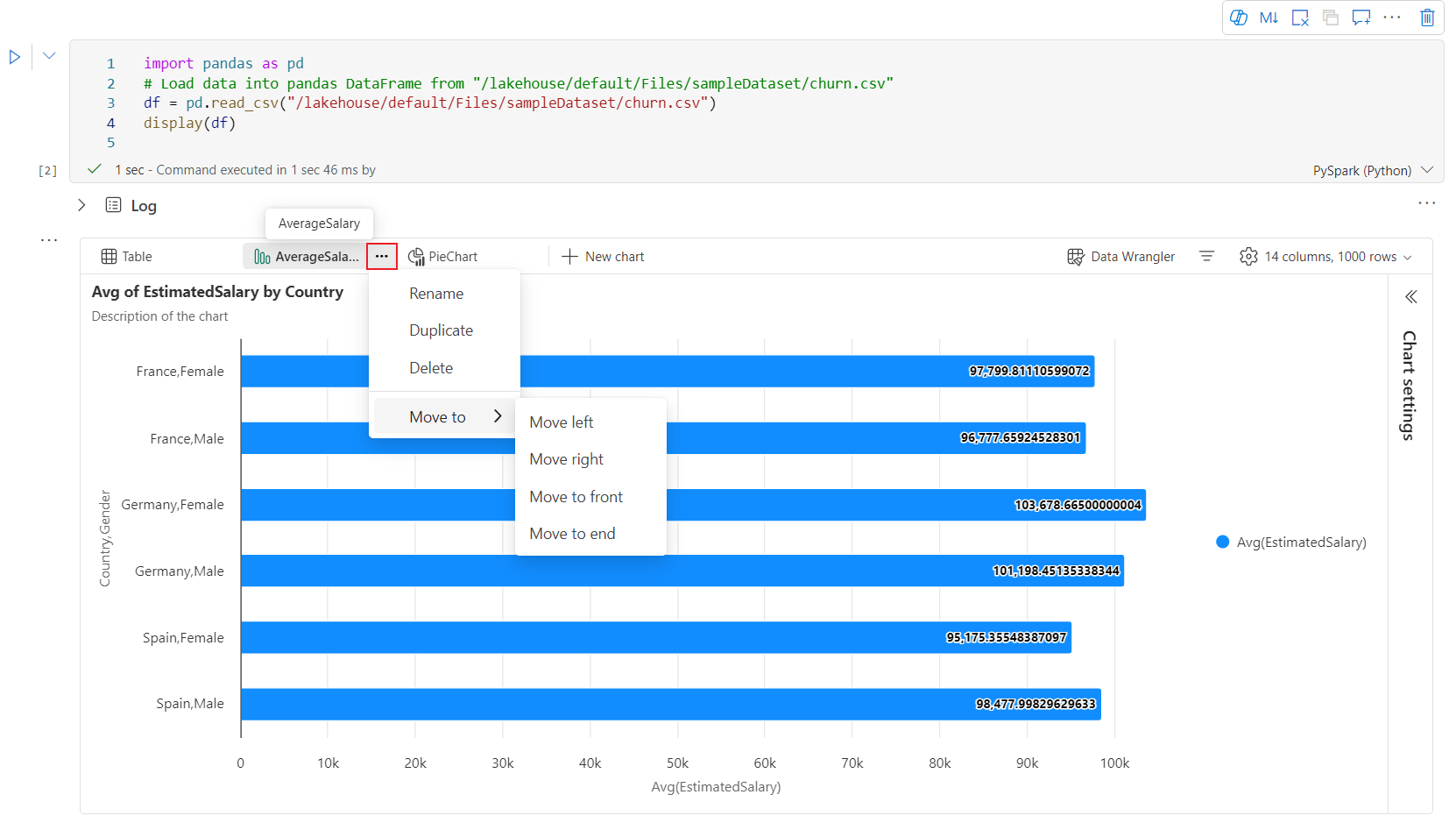
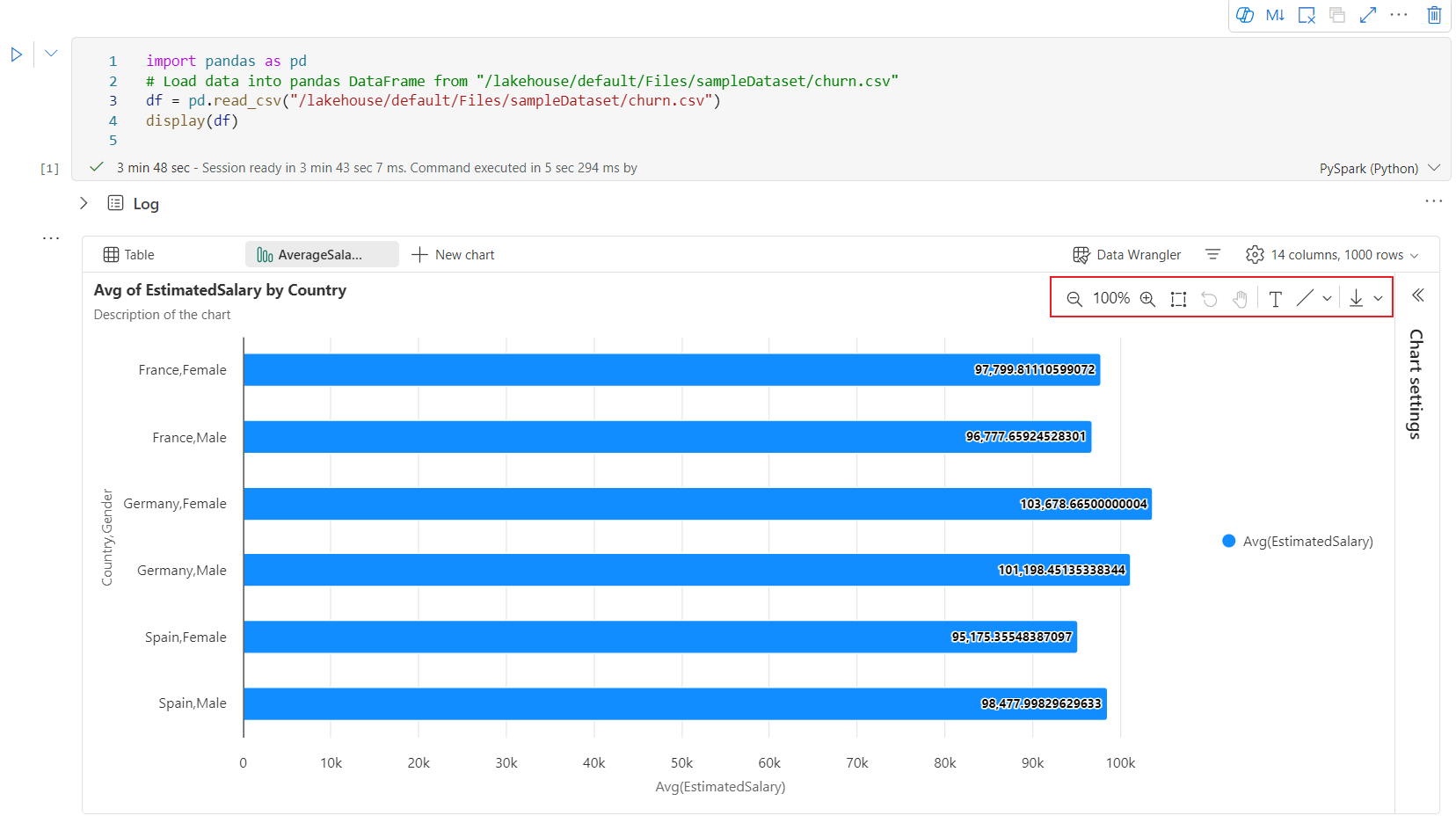
En interaktiv verktøylinje er tilgjengelig i den nye diagramopplevelsen når brukeren holder pekeren over et diagram. Støtteoperasjoner som zoome inn, zoome ut, velge å zoome, tilbakestille, panorere, merknadsredigering osv.
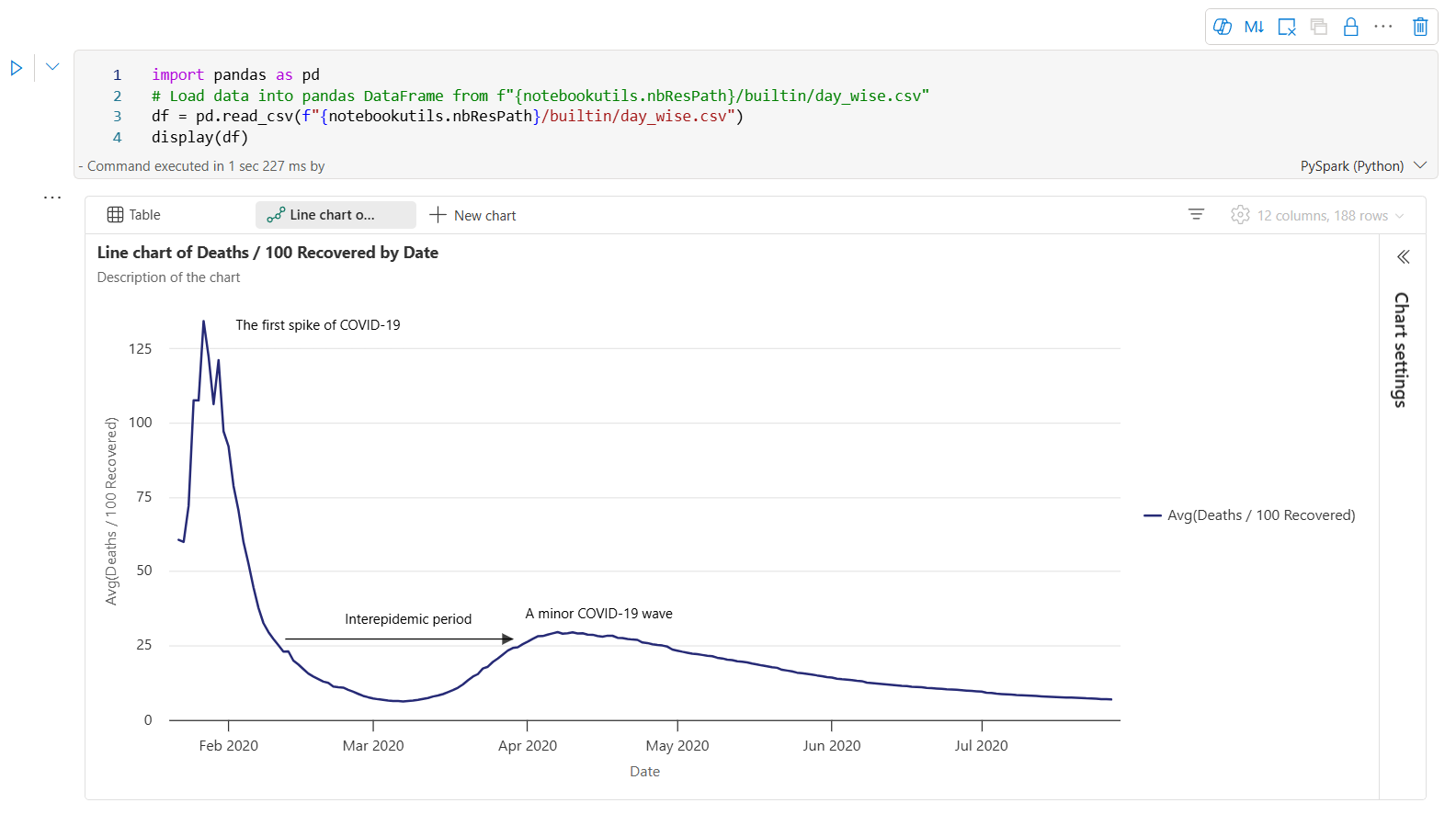
Her er et eksempel på diagrammerknader.




visning() sammendragsvisning
Bruk display(df, summary = true) til å kontrollere statistikksammendraget for en gitt Apache Spark DataFrame. Sammendraget inneholder kolonnenavnet, kolonnetypen, unike verdier og manglende verdier for hver kolonne. Du kan også velge en bestemt kolonne for å se minimumsverdien, maksimumsverdien, gjennomsnittsverdien og standardavviket.

displayHTML()-alternativ
Stoffnotatblokker støtter HTML-grafikk ved hjelp av displayHTML-funksjonen .
Bildet nedenfor er et eksempel på hvordan du oppretter visualiseringer ved hjelp av D3.js.

Hvis du vil opprette denne visualiseringen, kjører du følgende kode.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Bygge inn en Power BI-rapport i en notatblokk
Viktig
Denne funksjonen er i forhåndsvisning.
Powerbiclient Python-pakken støttes nå opprinnelig i Fabric-notatblokker. Du trenger ikke å gjøre noe ekstra oppsett (for eksempel godkjenningsprosess) på Fabric notebook Spark runtime 3.4. Bare importer powerbiclient , og fortsett deretter utforskingen. Hvis du vil lære mer om hvordan du bruker powerbiclient-pakken, kan du se dokumentasjonen for powerbiclient.
Powerbiclient støtter følgende viktige funksjoner.
Gjengi en eksisterende Power BI-rapport
Du kan enkelt bygge inn og samhandle med Power BI-rapporter i notatblokkene med bare noen få linjer med kode.
Bildet nedenfor er et eksempel på gjengivelse av eksisterende Power BI-rapport.

Kjør følgende kode for å gjengi en eksisterende Power BI-rapport.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Opprette rapportvisualobjekter fra en Spark DataFrame
Du kan bruke en Spark DataFrame i notatblokken til raskt å generere innsiktsfulle visualiseringer. Du kan også velge Lagre i den innebygde rapporten for å opprette et rapportelement i et målarbeidsområde.
Bildet nedenfor er et eksempel på en QuickVisualize() spark-dataramme.

Kjør følgende kode for å gjengi en rapport fra en Spark DataFrame.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Opprette rapportvisualobjekter fra en pandas DataFrame
Du kan også opprette rapporter basert på en pandas DataFrame i notatblokken.
Følgende bilde er et eksempel på en QuickVisualize() fra en pandas DataFrame.

Kjør følgende kode for å gjengi en rapport fra en Spark DataFrame.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Populære biblioteker
Når det gjelder datavisualisering, tilbyr Python flere grafbiblioteker som er pakket med mange forskjellige funksjoner. Som standard inneholder hvert Apache Spark-basseng i Stoff et sett med kuraterte og populære biblioteker med åpen kildekode.
Matplotlib
Du kan gjengi standard plottbiblioteker, for eksempel Matplotlib, ved hjelp av de innebygde gjengivelsesfunksjonene for hvert bibliotek.
Bildet nedenfor er et eksempel på hvordan du oppretter et stolpediagram ved hjelp av Matplotlib.


Kjør følgende eksempelkode for å tegne dette stolpediagrammet.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Bokeh
Du kan gjengi HTML eller interaktive biblioteker, for eksempel bokeh, ved hjelp av displayHTML(df).
Bildet nedenfor er et eksempel på å tegne tegn over et kart ved hjelp av bokeh.

Hvis du vil tegne dette bildet, kjører du følgende eksempelkode.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Tegne inn
Du kan gjengi HTML eller interaktive biblioteker som Plotly, ved hjelp av displayHTML().
Hvis du vil tegne dette bildet, kjører du følgende eksempelkode.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandaer
Du kan vise HTML-utdata for pandas DataFrames som standardutdata. Stoffnotatblokker viser automatisk det stiliserte HTML-innholdet.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df