Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Viktig!
Denne funksjonen er i forhåndsversjon.
Fabric Runtime leverer sømløs integrasjon i Microsoft Fabric-økosystemet, og tilbyr et robust miljø for dataingeniør- og datavitenskapsprosjekter drevet av Apache Spark.
Denne artikkelen introduserer Fabric Runtime 2.0 Public Preview, den nyeste runtime-versjonen designet for big data-beregninger i Microsoft Fabric. Den fremhever nøkkelfunksjonene og komponentene som gjør denne utgivelsen til et betydelig steg fremover for skalerbar analyse og avanserte arbeidsbelastninger.
Fabric Runtime 2.0 inkluderer følgende komponenter og oppgraderinger designet for å forbedre dine databehandlingsmuligheter:
- Apache Spark 4.1
- Operativsystem: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.13
- Delta Lake: 4,2
- R: 4.5.2
Viktig!
Microsoft Fabric-teamet ruller ut en oppdatering til Microsoft Fabric Runtime 2.0. Som en del av denne oppdateringen introduserer Python-oppgraderingen en avgjørende endring for kunder som bruker miljøartefakter med python og wheel-biblioteker. Kunder ser en av de to feilmeldingene ved Notebook- eller Spark Job Definition (SJD)-utførelse:
- Feil: advarsel: 1 avskrivning (siden 2.13.0); for detaljer, aktiver
:setting -deprecationeller:replay -deprecationkilde: SparkCoreService. - "LibraryManagementError": "En oppgradering av det grunnleggende Spark Python-miljøet er oppdaget. Vennligst publiser miljøet på nytt.|UserError"
Påkrevde handlinger
Publiser miljøet ditt på nytt (inkludert bibliotekene). For å gjøre dette, fjern alle biblioteker, publiser Environment, legg til alle bibliotekene på nytt, og publiser igjen. Denne prosessen gjenskaper miljøet ved å bruke den oppdaterte Python-runtimen og løser problemet.
Tips
Fabric Runtime 2.0 inkluderer støtte for Native Execution Engine, som kan forbedre ytelsen betydelig uten ekstra kostnader. Du kan aktivere den native kjøringsmotoren på miljønivå slik at alle jobber og notatbøker automatisk arver de forbedrede ytelsesmulighetene.
Aktiver Runtime 2.0
Du kan aktivere Runtime 2.0 enten på arbeidsområdenivå eller på miljøobjektnivå. Bruk arbeidsområdets innstilling for å bruke Runtime 2.0 som standard for alle Spark-arbeidsbelastninger i arbeidsområdet ditt. Alternativt kan du lage et miljøelement med Runtime 2.0 som kan brukes med spesifikke notatbøker eller Spark-jobbdefinisjoner, som overstyrer arbeidsområdets standard.
Aktiver Runtime 2.0 i arbeidsområdets innstillinger
For å sette Runtime 2.0 som standard for hele arbeidsområdet ditt:
Gå til siden for innstillinger for arbeidsområdet i Fabric-arbeidsområdet ditt.
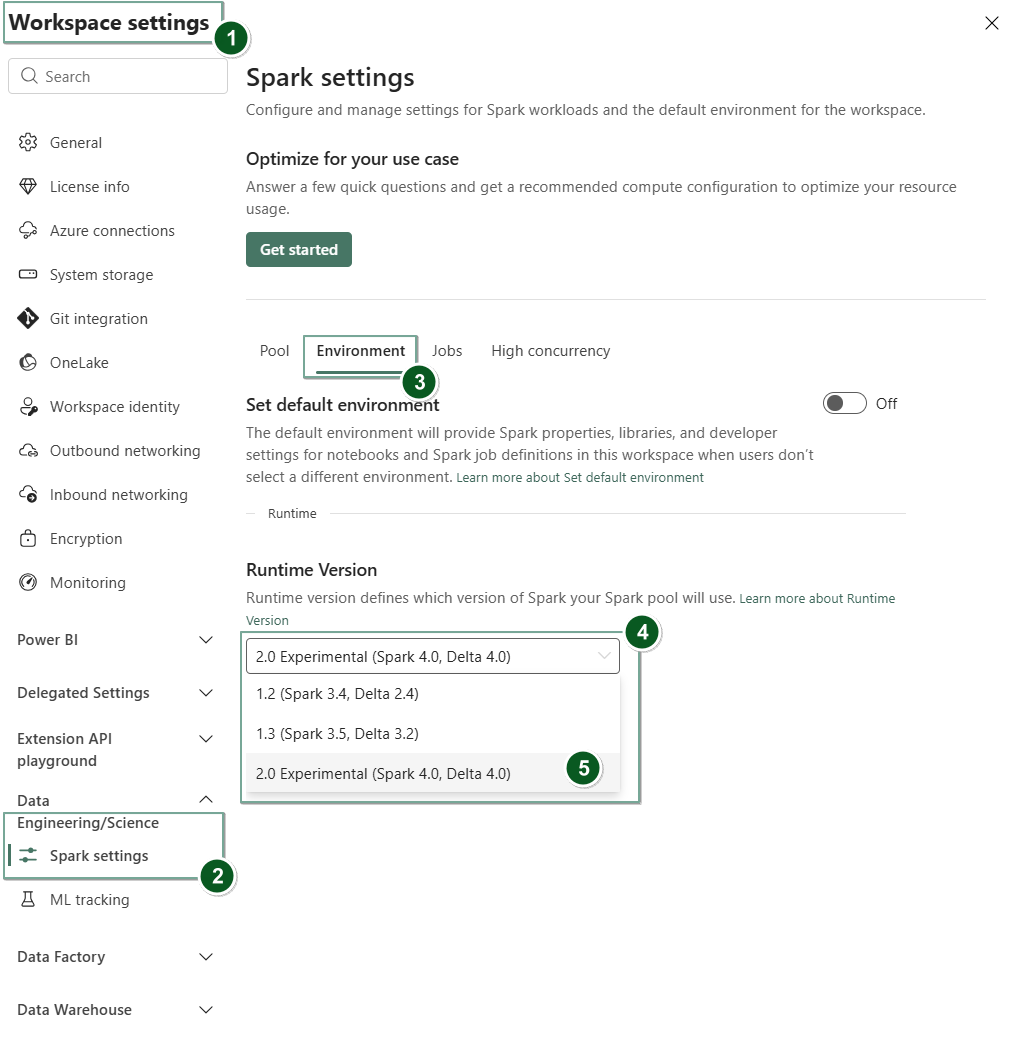
Velg fanen Data Engineering/Science og velg deretter Spark-innstillinger.
Velg Miljø-fanen.
Under nedtrekksmenyen for Runtime-versjonen , velg 2.0 Public Preview (Spark 4.1, Delta 4.2) og lagre endringene dine.
Runtime 2.0 er satt som standard kjøretid for arbeidsområdet ditt.

Aktiver kjøretid 2.0 i et miljøobjekt
For å bruke Runtime 2.0 med spesifikke notatbøker eller Spark-jobbdefinisjoner:
Opprett et nytt miljøelement eller åpne et eksisterende.
Under rullegardinen Runtime , velg 2.0 Public Preview (Spark 4.1, Delta 4.2),lagre og publiser endringene dine.
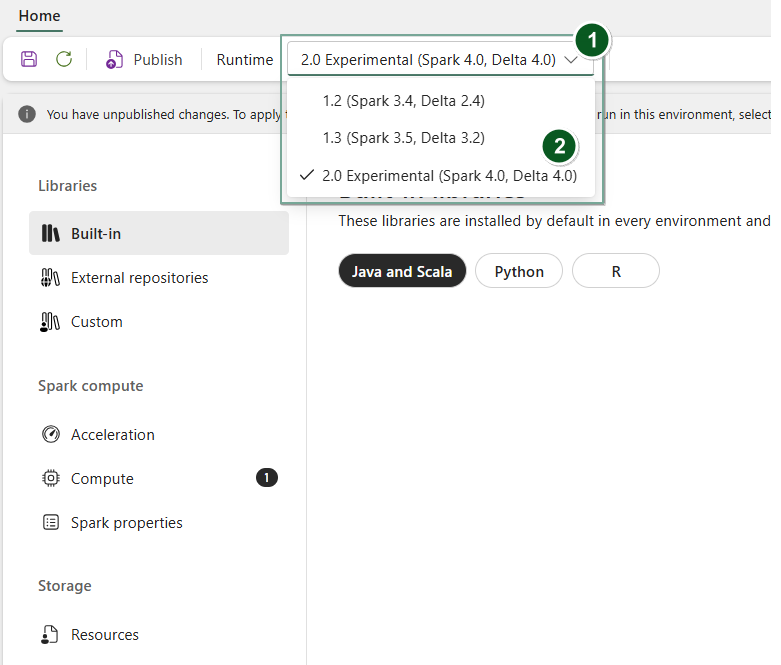
Deretter kan du bruke dette Miljø-elementet med din Notebook - eller Spark-jobbdefinisjon.

Du kan nå begynne å eksperimentere med de nyeste forbedringene og funksjonene introdusert i Fabric Runtime 2.0 (Spark 4.1 og Delta Lake 4.2).
Offentlig forhåndsversjon
Fabric Runtime 2.0 offentlig forhåndsvisningsfase gir deg tilgang til nye funksjoner og API-er fra både Spark 4.1 og Delta Lake 4.2. Forhåndsvisningen lar deg bruke de nyeste Spark- og Delta-baserte forbedringene umiddelbart, samt sikrer en smidig klarhet og overgang for forbedrede endringer som de nyere Java-, Scala- og Python-versjonene.
Tips
Hvis du vil ha oppdatert informasjon, en detaljert liste over endringer og spesifikke produktmerknader for Fabric Runtimes, kan du se og abonnere på Utgivelser og oppdateringer for Spark Runtimes.
Høydepunkter
Ytelses- og utførelsesmotorforbedringer
Fabric Runtime 2.0 inkluderer Native Execution Engine, som gir betydelige ytelsesforbedringer sammenlignet med åpen kildekode Spark. Motoren bruker vektorisert prosessering for å akselerere Spark-spørringer på lakehouse-infrastruktur uten å kreve kodeendringer.
Viktige ytelsesfunksjoner i Runtime 2.0:
- Opptil seks ganger raskere: Benchmarks viser opptil seks ganger raskere ytelse sammenlignet med åpen kildekode Spark på TPC-DS arbeidsbelastninger.
- Vektorisert CSV-parsing: Den innebygde kjøringsmotoren inkluderer en vektorisert CSV-parser som akselererer CSV-inntasting og spørringsarbeidsbelastninger. Vektorisert JSON-parsing og støtte for Spark Structured Streaming er planlagt for fremtidige oppdateringer.
For å aktivere den innebygde kjøringsmotoren, se Native utførelsesmotor for Fabric Data Engineering.
Apache Spark 4.1
Apache Spark 4.0 markerte en betydelig milepæl som den første utgivelsen i 4.x-serien, og legemliggjorde den kollektive innsatsen til det levende open source-fellesskapet. Fabric Runtime 2.0 kjører nå på Apache Spark 4.1, som bygger videre på dette grunnlaget med ytterligere forbedringer.
I denne versjonen er Spark SQL betydelig beriket med kraftige nye funksjoner designet for å øke uttrykksfullhet og allsidighet for SQL-arbeidsbelastninger, som støtte for VARIANT-datatyper, SQL-brukerdefinerte funksjoner, sesjonsvariabler, pipesyntaks og strengsortering. PySpark ser kontinuerlig dedikasjon til både sin funksjonelle bredde og den totale utvikleropplevelsen, med et innebygd plotting-API, et nytt Python Data Source API, støtte for Python UDTF-er og enhetlig profilering for PySpark UDF-er, sammen med en rekke andre forbedringer. Strukturert strømming utvikler seg med viktige tillegg som gir større kontroll og enklere feilsøking, spesielt introduksjonen av Arbitrary State API v2 for mer fleksibel tilstandshåndtering og State Data Source for enklere feilsøking.
Du kan se hele listen og detaljerte endringer her:
Note
I Spark 4.x er SparkR utfaset og kan bli fjernet i en fremtidig versjon.
Delta Lake 4.2
Delta Lake 4.2 bygger videre på tidligere Delta Lake-utgivelser, og fortsetter forpliktelsen til å gjøre Delta Lake interoperabelt på tvers av formater, enklere å jobbe med og mer ytelsesfullt. Den inkluderer kraftige nye funksjoner, ytelsesoptimaliseringer og grunnleggende forbedringer for fremtiden til åpne data-lakehouses.
For hele listen og detaljerte endringer introdusert med Delta Lake 3.3, 4.0, 4.1 og 4.2, se:
Dataoppsett og optimalisering
Runtime 2.0 støtter dataoppsett og optimaliseringsfunksjoner for delta-tabeller:
- Z-ordning: Organiser data i Delta-tabellfiler etter angitte kolonner for å forbedre spørringsytelsen for filtrerte spørringer.
- Liquid Clustering: En fleksibel clustering-tilnærming som automatisk optimaliserer dataoppsettet uten manuelt vedlikehold.
- Parallell Delta-snapshot-lasting: Den native kjøremotoren laster Delta-tabellsnapshots parallelt, noe som reduserer oppstartstiden for store tabeller.
Viktig!
Delta Lake 4.2-spesifikke funksjoner er eksperimentelle og fungerer kun på Spark-opplevelser, som notatbøker og Spark-jobbdefinisjoner. Hvis du må bruke de samme Delta Lake-tabellene på tvers av flere Microsoft Fabric-arbeidsbelastninger, bør du ikke aktivere disse funksjonene. For å lære mer om hvilke protokollversjoner og funksjoner som er kompatible på tvers av alle Microsoft Fabric-opplevelser, se Delta Lake table format interoperability.
Beregningshåndtering i kjøretid 2.0
Runtime 2.0 støtter følgende funksjoner for databehandling:
- Ressursprofiler: Konfigurer forhåndsdefinerte ressursallokeringer for Spark-økter for å matche arbeidsbelastningens krav og kontrollere kostnader.
- Egendefinerte live pools (forhåndsvisning): Lag dedikerte, forhåndsoppvarmede Spark-pooler som reduserer oppstartstiden for økter. Egendefinerte live pools er tilgjengelige i forhåndsvisning for Runtime 2.0-arbeidsbelastninger.
Begrensninger og notater
- Delta Lake 4.x-spesifikke funksjoner er eksperimentelle og fungerer kun på Spark-opplevelser, som notatbøker og Spark-jobbdefinisjoner. Hvis du må bruke de samme Delta Lake-tabellene på tvers av flere Fabric-arbeidsbelastninger, bør du ikke aktivere disse funksjonene. For mer informasjon, se Delta Lake-tabellformatinteroperabilitet.
- Runtime 2.0 er i offentlig forhåndsvisning. Noen funksjoner og API-er kan endres før generell tilgjengelighet.
- VS Code-utvidelsen for Fabric Spark støtter Runtime 2.0 for utvikling av notebook og Spark-jobbdefinisjon.
Relatert innhold
- Apache Spark Runtimes i Fabric – Oversikt, versjonering og støtte for flere kjøretider
- Spark Core-overføringsveiledning
- Overføringsveiledninger for SQL, Datasett og DataFrame
- Strukturert overføringsveiledning for strømming
- Overføringsveiledning for MLlib (Machine Learning)
- Overføringsveiledning for PySpark (Python på Spark)
- Overføringsveiledning for SparkR (R på Spark)