Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Fabric User datafunksjonsprogrammeringsmodellen definerer mønstre og konsepter for å lage funksjoner i Fabric.
SDK-en fabric-user-data-functions implementerer denne programmeringsmodellen og gir nødvendig funksjonalitet for å lage og publisere kjørbare funksjoner. SDK lar deg også sømløst integrere med andre elementer i Fabric-økosystemet, for eksempel Fabric-datakilder.
Dette biblioteket er offentlig tilgjengelig i PyPI og er forhåndsinstallert i dine user data functions items.
Denne artikkelen forklarer hvordan man bruker SDK-en til å bygge funksjoner som kan kalles fra Fabric-portalen, andre Fabric-elementer eller eksterne applikasjoner som bruker REST API. Du lærer programmeringsmodellen og nøkkelkonsepter med praktiske eksempler.
Tips
For fullstendige detaljer om alle klasser, metoder og parametere, se SDK-referansedokumentasjonen.
Getting started med SDK-en
Denne delen introduserer kjernekomponentene i User Data Functions SDK og forklarer hvordan du strukturerer funksjonene dine. Du lærer om nødvendige importer, dekoratører, og hvilke typer input- og outputdata funksjonene dine kan håndtere.
SDK for brukerdatafunksjoner
SDK-en fabric-user-data-functions gir kjernekomponentene du trenger for å lage brukerdatafunksjoner i Python.
Påkrevde import og initialisering
Hver user data functions-fil må importere modulen fabric.functions og initialisere kjøringskonteksten:
import datetime
import fabric.functions as fn
import logging
udf = fn.UserDataFunctions()
Dekoratøren @udf.function()
Funksjoner merket med dekoratoren @udf.function() kan kalles fra Fabric-portalen, et annet Fabric-element eller en ekstern applikasjon. Funksjoner med denne dekoratoren må spesifisere en returtype.
Eksempel:
@udf.function()
def hello_fabric(name: str) -> str:
logging.info('Python UDF trigger function processed a request.')
logging.info('Executing hello fabric function.')
return f"Welcome to Fabric Functions, {name}, at {datetime.datetime.now()}!"
Hjelper-funksjoner
Python-metoder uten @udf.function() decorator kan ikke aktiveres direkte. De kan kun tilkalles fra dekorerte funksjoner og fungerer som hjelpefunksjoner.
Eksempel:
def uppercase_name(name: str) -> str:
return name.upper()
Støttede inndatatyper
Du kan definere inndataparametere for funksjonen, for eksempel primitive datatyper som str, int, float osv. Datatypene for inndata som støttes, er:
| JSON-type | Python-datatype |
|---|---|
| Streng | Str |
| Datetime-streng | datetime |
| Boolsk | Bool |
| tall | int, flyt |
| Matrise | list[], eksempelliste[int] |
| objekt | Diktering |
| objekt | pandaer DataFrame |
| Objekt eller matrise av objekter | pandas-serien |
Merk deg
For å bruke pandas DataFrame- og Series-typer, gå til Fabric-portalen, finn arbeidsområdet ditt, og åpne brukerdatafunksjonene dine. Velg Biblioteksadministrasjon, søk etter fabric-user-data-functions pakken, og oppdater den til versjon 1.0.0 eller nyere.
Eksempel på forespørselstekst for inndatatyper som støttes:
{
"name": "Alice", // String (str)
"signup_date": "2025-11-08T13:44:40Z", // Datetime string (datetime)
"is_active": true, // Boolean (bool)
"age": 30, // Number (int)
"height": 5.6, // Number (float)
"favorite_numbers": [3, 7, 42], // Array (list[int])
"profile": { // Object (dict)
"email": "alice@example.com",
"location": "Sammamish"
},
"sales_data": { // Object (pandas DataFrame)
"2025-11-01": {"product": "A", "units": 10},
"2025-11-02": {"product": "B", "units": 15}
},
"weekly_scores": [ // Object or Array of Objects (pandas Series)
{"week": 1, "score": 88},
{"week": 2, "score": 92},
{"week": 3, "score": 85}
]
}
Utdatatyper som støttes
Datatypene for utdata som støttes, er:
| Python-datatype |
|---|
| Str |
| datetime |
| Bool |
| int, flyt |
| list[datatype], for eksempel liste[int] |
| Diktering |
| Ingen |
| pandas-serien |
| pandaer DataFrame |
Skrivefunksjoner
Syntakskrav og begrensninger
Når du skriver User Data Functions, må du følge spesifikke syntaksregler for å sikre at funksjonene dine fungerer korrekt.
Parameternavngivning
-
Bruk camelCase: Parameternavn må bruke camelCase-navnekonvensjon og kan ikke inneholde understreker. For eksempel, bruk
productNamei stedet forproduct_name. -
Reserverte nøkkelord: Du kan ikke bruke reserverte Python-nøkkelord eller følgende Fabric-spesifikke nøkkelord som parameternavn eller funksjonsnavn:
req,context, ogreqInvocationId.
Parameterkrav
Typeannotasjoner som kreves: Alle parametere må inkludere typeannotasjoner (for eksempel
name: str).Standardverdier: Standardparameterverdier støttes. Du kan definere standardargumenter i Fabric-brukerdatafunksjoner for å gjøre koden enklere å kalle og vedlikeholde. Parametere med standardverdier er valgfrie ved innkalling; parametere uten standardverdier er nødvendige. Følgende typer støttes som standardverdier:
Standardtype Notes string Enhver JSON-serialiserbar streng. Dato-tid-streng Spesifiser som en streng i funksjonssignaturen. Kjøretiden parser strengen til ved datetimeinvokasjon. Bruk ISO 8601-formatet (for eksempel2025-12-31T23:59:59Z) for konsistent, entydig parsing.boolsk TrueellerFalse.Integer Enhver heltallsverdi. Flyttall Enhver flyttallsverdi. Liste Må være JSON-serialiserbar. Foretrekk Nonei signaturen og tildel den reelle standarden inne i funksjonen for å unngå delte, foranderlige standardinnstillinger.Ordbok Må være JSON-serialiserbar. Foretrekk Nonei signaturen og tildel den reelle standarden inne i funksjonen.pandaer DataFrame Levert som et JSON-objekt som SDK-en konverterer til en pandas-type. Krever fabric-user-data-functionsversjon 1.0.0 eller nyere.pandas-serien Leveres som et JSON-array av objekter som SDK-en konverterer til en pandas-type. Krever fabric-user-data-functionsversjon 1.0.0 eller nyere.Syntaks
@udf.function() def function_name( requiredParam: str, optionalStr: str = "hello", optionalDate: datetime.datetime = "2025-01-01T00:00:00Z", # specify as a string; the runtime parses it to datetime at invocation time optionalBool: bool = True, optionalInt: int = 10, optionalFloat: float = 1.5, optionalList: list | None = None, # assign real default inside the function optionalDict: dict | None = None, # assign real default inside the function ) -> dict: optionalList = optionalList or [1, 2, 3] optionalDict = optionalDict or {"key": "value"} return {"param": requiredParam}Standardinnstillinger må være JSON-serialiserbare (sett og tupler støttes ikke). For liste- eller ordbokstandardinnstillinger, bruk
Nonei signaturen og tildel den reelle standarden inne i funksjonen for å unngå delte, foranderlige standardinnstillinger. Bruk ISO 8601-formatet (for eksempel,2025-12-31T23:59:59Z) for dato-tid-standardinnstillinger. Å bruke pandas DataFrame eller Series som standard kreverfabric-user-data-functionsversjon 1.0.0 eller nyere.
Funksjonskrav
-
Returtype kreves: Funksjoner med dekoratoren
@udf.function()må spesifisere en returtypeannotasjon (for eksempel-> str). -
Nødvendige importer: Setningen
import fabric.functions as fnogudf = fn.UserDataFunctions()initialiseringen er nødvendige for at funksjonene dine skal fungere.
Eksempel på korrekt syntaks
@udf.function()
def process_order(orderNumber: int, customerName: str, orderDate: str) -> dict:
return {
"order_id": orderNumber,
"customer": customerName,
"date": orderDate,
"status": "processed"
}
Slik skriver du en asynkrone funksjon
Legg til asynkron dekoratør med funksjonsdefinisjonen i koden. Med en async funksjon kan du forbedre respons og effektivitet i programmet ved å håndtere flere oppgaver samtidig. De er ideelle for å håndtere store volumer av I/O-bundne operasjoner. Denne eksempelfunksjonen leser en CSV-fil fra et lakehouse ved hjelp av pandaer. Funksjonen tar filnavn som inndataparameter.
import pandas as pd
# Replace the alias "<My Lakehouse alias>" with your connection alias.
@udf.connection(argName="myLakehouse", alias="<My Lakehouse alias>")
@udf.function()
async def read_csv_from_lakehouse(myLakehouse: fn.FabricLakehouseClient, csvFileName: str) -> str:
# Connect to the Lakehouse
connection = myLakehouse.connectToFilesAsync()
# Download the CSV file from the Lakehouse
csvFile = connection.get_file_client(csvFileName)
downloadFile = await csvFile.download_file()
csvData = await downloadFile.readall()
# Read the CSV data into a pandas DataFrame
from io import StringIO
df = pd.read_csv(StringIO(csvData.decode('utf-8')))
# Display the DataFrame
result=""
for index, row in df.iterrows():
result=result + "["+ (",".join([str(item) for item in row]))+"]"
# Close the connection
csvFile.close()
connection.close()
return f"CSV file read successfully.{result}"
Arbeid med data
Datatilkoblinger til Fabric-datakilder
SDK-en lar deg referere til dataforbindelser uten behov for å skrive tilkoblingsstrenger i koden din. Biblioteket fabric.functions inneholder to måter å håndtere datatilkoblinger på:
- fabric.functions.FabricSqlConnection: Lar deg arbeide med SQL-databaser i Fabric, inkludert SQL Analytics-endepunkter og Fabric-lagre.
- fabric.functions.FabricLakehouseClient: Lar deg jobbe med Lakehouses, med en måte å koble til både Lakehouse-bord og Lakehouse-filer.
Hvis du vil referere til en tilkobling til en datakilde, må du bruke @udf.connection-dekoratøren. Du kan bruke den i et av følgende formater:
@udf.connection(alias="<alias for data connection>", argName="sqlDB")@udf.connection("<alias for data connection>", "<argName>")@udf.connection("<alias for data connection>")
Argumentene for @udf.connection er:
-
argName, navnet på variabelen som tilkoblingen bruker i funksjonen. -
alias, aliaset for tilkoblingen du la til med Behandle tilkoblinger-menyen. - Hvis
argNameogaliashar samme verdi, kan du bruke@udf.connection("<alias and argName for the data connection>").
Eksempel
# Where demosqldatabase is the argument name and the alias for my data connection used for this function
@udf.connection("demosqldatabase")
@udf.function()
def read_from_sql_db(demosqldatabase: fn.FabricSqlConnection)-> list:
# Connect to the SQL database
connection = demosqldatabase.connect()
cursor = connection.cursor()
# Replace with the query you want to run
query = "SELECT * FROM (VALUES ('John Smith', 31), ('Kayla Jones', 33)) AS Employee(EmpName, DepID);"
# Execute the query
cursor.execute(query)
# Fetch all results
results = cursor.fetchall()
# Close the cursor and connection
cursor.close()
connection.close()
return results
Generiske tilkoblinger for Fabric-elementer eller Azure-ressurser
SDK-en støtter generiske tilkoblinger som lar deg opprette tilkoblinger til Fabric-objekter eller Azure-ressurser ved å bruke din User Data Functions-elementeieridentitet. Denne funksjonen genererer en Microsoft Entra ID-token med eierens identitet og en oppgitt målgruppetype. Dette tokenet brukes til å autentisere med Fabric-elementer eller Azure-ressurser som støtter den målgruppetypen. Denne tilnærmingen gir en lignende programmeringsopplevelse som å bruke administrerte tilkoblingsobjekter fra funksjonen Administrer tilkoblinger , men kun for den oppgitte målgruppetypen i forbindelsen.
Denne funksjonen bruker dekoratøren @udf.generic_connection() med følgende parametere:
| Parameter | Beskrivelse | Verdi |
|---|---|---|
argName |
Navnet på variabelen som sendes til funksjonen. Brukeren må spesifisere denne variabelen i argumentene til funksjonen og bruke typen fn.FabricItem for den |
Hvis for eksempel argName=CosmosDb, skal funksjonen inneholde dette argumentet cosmosDb: fn.FabricItem |
audienceType |
Målgruppetypen som tilkoblingen er opprettet for. Denne parameteren er knyttet til typen Fabric-element eller Azure-tjeneste og bestemmer klienten som brukes for tilkoblingen. | De tillatte verdiene for denne parameteren er CosmosDb eller KeyVault. |
Koble til Fabric Cosmos DB-beholder ved hjelp av en generisk tilkobling
Generelle tilkoblinger støtter opprinnelige Fabric Cosmos DB-elementer ved hjelp av målgruppetypen CosmosDB . Den inkluderte SDK-en for brukerdatafunksjoner gir en hjelpemetode kalt get_cosmos_client som henter en singleton Cosmos DB-klient for hvert anrop.
Du kan koble til et Fabric Cosmos DB-element ved hjelp av en generisk tilkobling ved å følge disse trinnene:
Gå til Fabric-portalen, finn arbeidsområdet ditt, og åpne elementet for brukerdatafunksjoner. Velg Library management, søk etter biblioteket
azure-cosmos, og installer det. For mer informasjon, se Administrer biblioteker.Gå til elementinnstillingene for Fabric Cosmos DB .
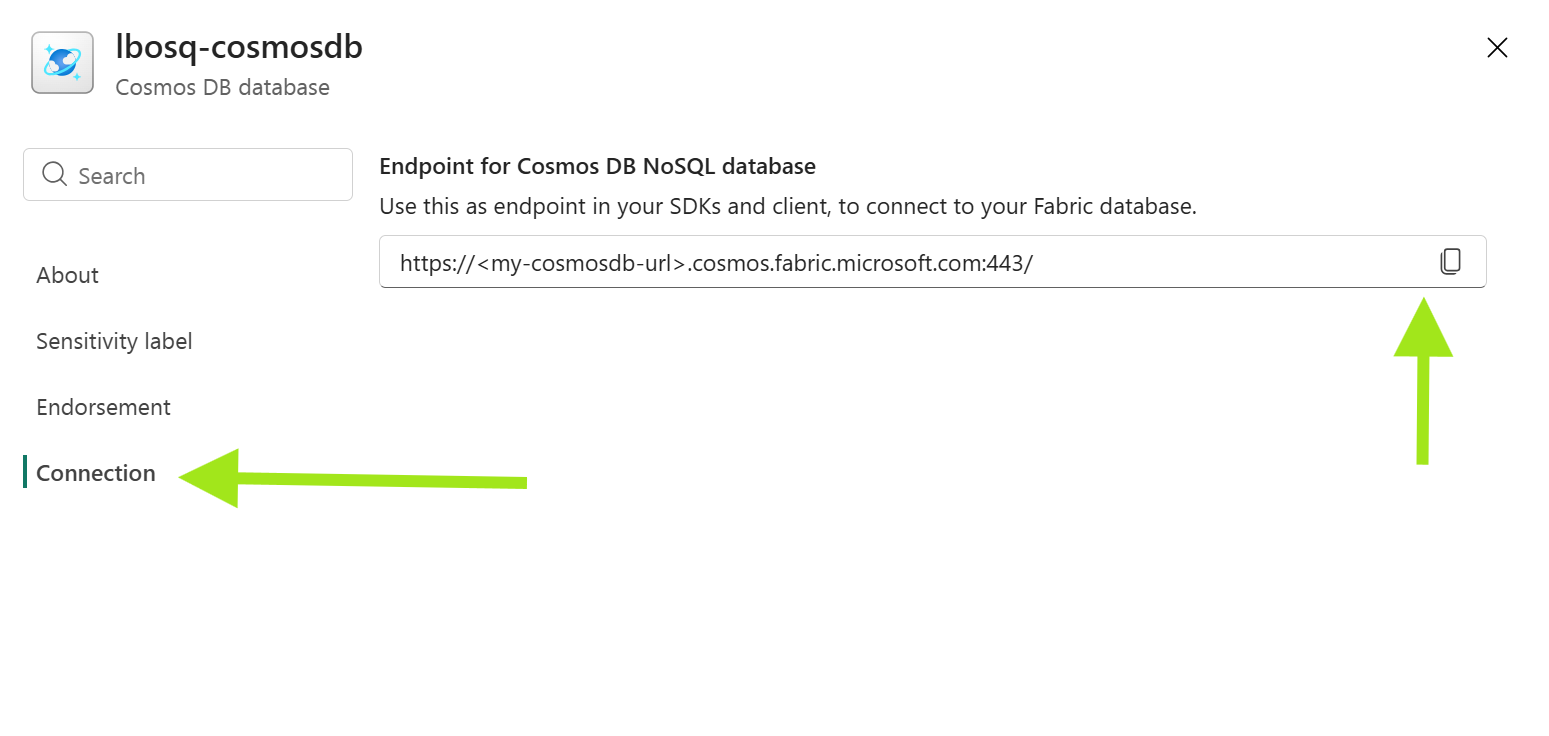
Hent URL-adressen for Fabric Cosmos DB-endepunktet.
Gå til elementet Brukerdatafunksjoner. Bruk følgende eksempelkode til å koble til Fabric Cosmos DB-beholderen og kjøre en lesespørring ved hjelp av Cosmos DB-eksempeldatasettet. Erstatt verdiene for følgende variabler:
-
COSMOS_DB_URImed Fabric Cosmos DB-endepunktet. -
DB_NAMEmed navnet på Fabric Cosmos DB-varen din.
from fabric.functions.cosmosdb import get_cosmos_client import json @udf.generic_connection(argName="cosmosDb", audienceType="CosmosDB") @udf.function() def get_product_by_category(cosmosDb: fn.FabricItem, category: str) -> list: COSMOS_DB_URI = "YOUR_COSMOS_DB_URL" DB_NAME = "YOUR_COSMOS_DB_NAME" # Note: This is the Fabric item name CONTAINER_NAME = "SampleData" # Note: This is your container name. In this example, we are using the SampleData container. cosmosClient = get_cosmos_client(cosmosDb, COSMOS_DB_URI) # Get the database and container database = cosmosClient.get_database_client(DB_NAME) container = database.get_container_client(CONTAINER_NAME) query = 'select * from c WHERE c.category=@category' #"select * from c where c.category=@category" parameters = [ { "name": "@category", "value": category } ] results = container.query_items(query=query, parameters=parameters) items = [item for item in results] logging.info(f"Found {len(items)} products in {category}") return json.dumps(items)-
Test eller kjør denne funksjonen ved å angi et kategorinavn, for eksempel
Accessoryi aktiveringsparameterne.


Merk deg
Du kan også bruke disse stegene for å koble til en Azure Cosmos DB-database ved å bruke konto-URL-en og databasenavnene. Eierkontoen til User Data Functions trenger access tillatelser til den Azure Cosmos DB-kontoen.
Koble til Azure Key Vault ved å bruke en generisk tilkobling
Generiske tilkoblinger støtter tilkobling til en Azure Key Vault ved å bruke målgruppetypen KeyVault. Denne typen tilkobling krever at eieren av Fabric User Data Functions har tillatelser til å koble til Azure Key Vault. Du kan bruke denne tilkoblingen til å hente nøkler, hemmeligheter eller sertifikater etter navn.
Du kan koble til Azure Key Vault for å hente en klienthemmelighet for å kalle et API ved å bruke en generisk tilkobling ved å følge disse stegene:
Gå til Fabric-portalen, finn arbeidsområdet ditt, og åpne elementet for brukerdatafunksjoner. Velg Library Management, søk deretter etter og installer bibliotekene
requestsogazure-keyvault-secrets. For mer informasjon, se Administrer biblioteker.Gå til din Azure Key Vault ressurs i Azure portal og hent
Vault URIog navnet på nøkkelen, hemmeligheten eller sertifikatet ditt.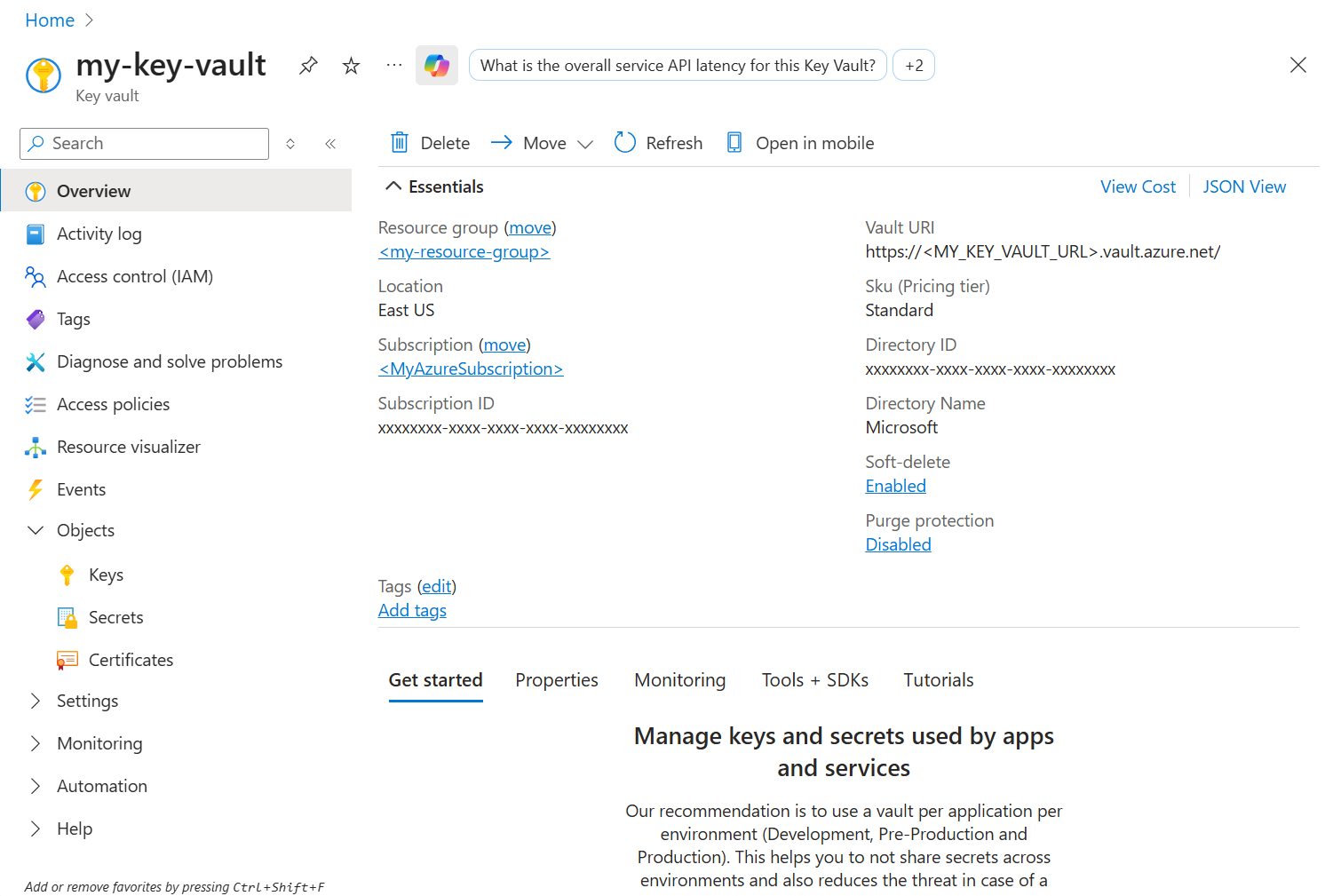
Go back til ditt Fabric User Data Functions-element og bruk dette eksempelet. I dette eksempelet henter vi en hemmelighet fra Azure Key Vault for å koble til et offentlig API. Erstatt verdien av følgende variabler:
-
KEY_VAULT_URLmed duVault URIhentet i forrige trinn. -
KEY_VAULT_SECRET_NAMEmed navnet på hemmeligheten din. -
API_URLvariabelen med nettadressen til API-et du vil koble til. Dette eksemplet forutsetter at du kobler til en offentlig API som godtar GET-forespørsler og tar følgende parametereapi-keyogrequest-body.
from azure.keyvault.secrets import SecretClient from azure.identity import DefaultAzureCredential import requests @udf.generic_connection(argName="keyVaultClient", audienceType="KeyVault") @udf.function() def retrieveNews(keyVaultClient: fn.FabricItem, requestBody:str) -> str: KEY_VAULT_URL = 'YOUR_KEY_VAULT_URL' KEY_VAULT_SECRET_NAME= 'YOUR_SECRET' API_URL = 'YOUR_API_URL' credential = keyVaultClient.get_access_token() client = SecretClient(vault_url=KEY_VAULT_URL, credential=credential) api_key = client.get_secret(KEY_VAULT_SECRET_NAME).value api_url = API_URL params = { "api-key": api_key, "request-body": requestBody } response = requests.get(api_url, params=params) data = "" if response.status_code == 200: data = response.json() else: print(f"Error {response.status_code}: {response.text}") return f"Response: {data}"-
Test eller kjør denne funksjonen ved å angi en forespørselstekst i koden.

Avanserte funksjoner
Programmeringsmodellen definerer avanserte mønstre som gir deg større kontroll over funksjonene dine. SDK-en implementerer disse mønstrene gjennom klasser og metoder som lar deg å:
- Access invokasjonsmetadata om hvem som kalte funksjonen din og hvordan
- Håndter tilpassede feilscenarier med strukturerte feilresponser
- Integrer med Fabric-variabelbiblioteker for sentralisert konfigurasjonsstyring
Merk deg
User Data Functions har tjenestebegrensninger for forespørselsstørrelse, utførelsestidsavbrudd og svarstørrelse. For detaljer om disse begrensningene og hvordan de håndheves, se Tjenestedetaljer og begrensninger.
Hent aktiveringsegenskaper ved hjelp av UserDataFunctionContext
SDK-en inkluderer objektet UserDataFunctionContext . Dette objektet inneholder metadata for funksjonskall og kan brukes til å lage spesifikk app-logikk for ulike kallmekanismer (som portalkall versus REST API-kall).
Tabellen nedenfor viser egenskapene for objektet UserDataFunctionContext:
| Egenskapsnavn | Datatype | Beskrivelse |
|---|---|---|
| invocation_id | streng | Den unike GUID-en som er knyttet til aktiveringen av elementet for brukerdatafunksjoner. |
| executing_user | objekt | Metadata for brukerens informasjon som brukes til å godkjenne aktiveringen. |
Objektet executing_user inneholder følgende informasjon:
| Egenskapsnavn | Datatype | Beskrivelse |
|---|---|---|
| Oid | streng (GUID) | Brukerens objekt-ID, som er en uforanderlig identifikator for forespørren. Dette er den bekreftede identiteten til brukeren eller tjenestekontohaveren som brukes til å aktivere denne funksjonen på tvers av programmer. |
| TenantId | streng (GUID) | ID-en til leieren som brukeren er logget på. |
| PreferredUsername | streng | Foretrukket brukernavn for den påkallende brukeren, som angitt av brukeren. Denne verdien kan dempes. |
For å access parameteren UserDataFunctionContext må du bruke følgende dekorator øverst i funksjonsdefinisjonen: @udf.context(argName="<parameter name>")
Eksempel
@udf.context(argName="myContext")
@udf.function()
def getContext(myContext: fabric.functions.UserDataFunctionContext)-> str:
logging.info('Python UDF trigger function processed a request.')
return f"Hello oid = {myContext.executing_user['Oid']}, TenantId = {myContext.executing_user['TenantId']}, PreferredUsername = {myContext.executing_user['PreferredUsername']}, InvocationId = {myContext.invocation_id}"
Kast en håndtert feil med UserThrownError
Når du utvikler funksjonen din, kan du kaste et forventet feilsvar ved å bruke UserThrownError klassen som er tilgjengelig i SDK-en. En bruk av denne klassen er å håndtere tilfeller der brukerinndataene ikke klarer å bestå forretningsvalideringsreglene.
Eksempel
import datetime
@udf.function()
def raise_userthrownerror(age: int)-> str:
if age < 18:
raise fn.UserThrownError("You must be 18 years or older to use this service.", {"age": age})
return f"Welcome to Fabric Functions at {datetime.datetime.now()}!"
Klassekonstruktøren UserThrownError tar to parametere:
-
Message: Denne strengen returneres som feilmelding til programmet som aktiverer denne funksjonen. - En ordliste med egenskaper returneres til programmet som aktiverer denne funksjonen.
Hent variabler fra Fabric-variabelbiblioteker
Et Fabric-variabelbibliotek i Microsoft Fabric er et sentralisert arkiv for å administrere variabler som kan brukes på tvers av ulike elementer i et arbeidsområde. Det lar utviklere tilpasse og dele varekonfigurasjoner effektivt. Hvis du ikke har et variabelbibliotek ennå, se Opprett og administrer variabelbiblioteker.
For å bruke et variabelbibliotek i funksjonene dine, legger du til en tilkobling til det fra brukerdatafunksjonene dine. Variabelbiblioteker finnes i OneLake-katalogen sammen med datakilder som SQL-databaser og lakehouses.
Følg disse stegene for å bruke variabelbiblioteker i funksjonene dine:
- I brukerdatafunksjonene dine, legg til en tilkobling til variabelbiblioteket ditt. I OneLake-katalogen, finn og velg variabelbiblioteket ditt, og velg deretter Koble til. Legg merke til aliaset som Fabric genererer for tilkoblingen.
- Legg til en tilkoblingsdekorator for det variable bibliotekelementet. Du kan for eksempel
@udf.connection(argName="varLib", alias="<My Variable Library Alias>")erstatte alias til den nylig tilføyde tilkoblingen for det variable bibliotekelementet. - I funksjonsdefinisjonen tar du med et argument med typen
fn.FabricVariablesClient. Denne klienten inneholder metoder du trenger for å arbeide med variabelbibliotekelementet. - Bruk
getVariables()metoden for å hente alle variablene fra variabelbiblioteket. - For å lese verdiene til variablene bruker du enten
["variable-name"]eller.get("variable-name").
Eksempel
I dette eksempelet simulerer vi et konfigurasjonsscenario for et produksjons- og et utviklingsmiljø. Denne funksjonen setter en storage-sti avhengig av det valgte miljøet ved å bruke en verdi hentet fra variabelbiblioteket. Variabelbiblioteket inneholder en variabel kalt ENV der brukere kan angi en verdi på dev eller prod.
@udf.connection(argName="varLib", alias="<My Variable Library Alias>")
@udf.function()
def get_storage_path(dataset: str, varLib: fn.FabricVariablesClient) -> str:
"""
Description: Determine storage path for a dataset based on environment configuration from Variable Library.
Args:
dataset_name (str): Name of the dataset to store.
varLib (fn.FabricVariablesClient): Fabric Variable Library connection.
Returns:
str: Full storage path for the dataset.
"""
# Retrieve variables from Variable Library
variables = varLib.getVariables()
# Get environment and base paths
env = variables.get("ENV")
dev_path = variables.get("DEV_FILE_PATH")
prod_path = variables.get("PROD_FILE_PATH")
# Apply environment-specific logic
if env.lower() == "dev":
return f"{dev_path}{dataset}/"
elif env.lower() == "prod":
return f"{prod_path}{dataset}/"
else:
return f"incorrect settings define for ENV variable"