Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Gjelder for:✅ Fabric Data Engineering og Data Science
Når du oppretter et arbeidsområde i Microsoft Fabric, opprettes en starter pool som er tilknyttet det arbeidsområdet automatisk. Med den forenklede oppsettet i Microsoft Fabric er det ikke nødvendig å velge node- eller maskinstørrelser, siden disse alternativene håndteres for deg bak kulissene. Denne konfigurasjonen gir en raskere (5–10 sekunder) Startopplevelse for Apache Spark-økt for brukere å komme i gang og kjøre Apache Spark-jobbene dine i mange vanlige scenarioer uten å måtte bekymre seg for å konfigurere databehandlingen. For avanserte scenarier med spesifikke databehandlingskrav kan brukere opprette et egendefinert Apache Spark-utvalg og endre størrelsen på nodene basert på deres ytelsesbehov.
Hvis du vil gjøre endringer i Apache Spark-innstillingene i et arbeidsområde, bør du ha administratorrollen for dette arbeidsområdet. Hvis du vil ha mer informasjon, kan du se Roller i arbeidsområder.
Slik administrerer du Spark-innstillingene for utvalget som er knyttet til arbeidsområdet:
Gå til innstillingene for arbeidsområdet i arbeidsområdet, og velg alternativet Dataingeniør ing/vitenskap for å utvide menyen:
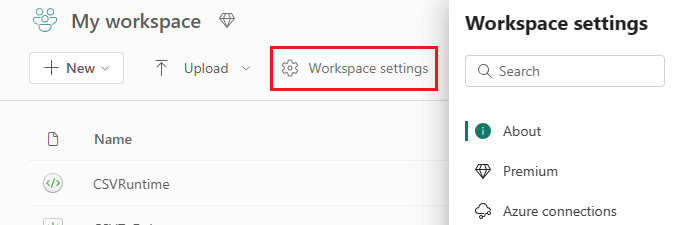
Du ser Spark Compute-alternativet i menyen til venstre:
Merk
Hvis du endrer standardutvalget fra Startutvalg til et egendefinert spark-utvalg, kan det hende du ser lengre øktstart (~3 minutter).


Utvalg
Standardutvalg for arbeidsområdet
Du kan bruke det automatisk opprettede startutvalget eller opprette egendefinerte utvalg for arbeidsområdet.
Startutvalg: Forhåndshydrerte live-bassenger opprettes automatisk for raskere opplevelse. Disse klyngene er middels store. Startutvalget er satt til en standardkonfigurasjon basert på SKU-en for stoffkapasitet som er kjøpt. Administratorer kan tilpasse maksimalt antall noder og eksekutorer basert på kravene for Spark-arbeidsbelastningsskala. Hvis du vil ha mer informasjon, kan du se Konfigurere startutvalg
Egendefinert sparkutvalg: Du kan endre størrelsen på nodene, autoskalaen og dynamisk tildele eksekutorer basert på kravene til Spark-jobben. Hvis du vil opprette et egendefinert Spark-utvalg, bør kapasitetsadministratoren aktivere alternativet Egendefinerte arbeidsområdeutvalg i Spark Compute-delen av innstillingene for kapasitetsadministrator.
Merk
Kapasitetsnivåkontrollen for egendefinerte arbeidsområdeutvalg er aktivert som standard. Hvis du vil ha mer informasjon, kan du se Konfigurere og administrere innstillinger for datateknikk og datavitenskap for stoffkapasiteter.
Administratorer kan opprette egendefinerte Spark-utvalg basert på databehandlingskravene ved å velge alternativet Nytt utvalg .

Apache Spark for Microsoft Fabric støtter enkeltnodeklynger, som lar brukere velge en minimumsnodekonfigurasjon på 1, i så fall kjører driveren og executoren i én node. Disse enkeltnodeklyngene tilbyr gjenopprettelig høy tilgjengelighet under nodefeil og bedre jobbpålitelighet for arbeidsbelastninger med mindre databehandlingskrav. Du kan også aktivere eller deaktivere alternativet for autoskalering for de egendefinerte Spark-bassengene. Når det er aktivert med autoskala, henter utvalget nye noder innenfor den maksimale nodegrensen som er angitt av brukeren, og trekker dem tilbake etter jobbkjøringen for bedre ytelse.
Du kan også velge alternativet for dynamisk tildeling av eksekutorer til å samle automatisk optimalt antall eksekutorer innenfor den maksimale grensen som er angitt basert på datavolumet for bedre ytelse.

Mer informasjon om Apache Spark-databehandling for Stoff.
- Tilpass beregningskonfigurasjon for elementer: Som administrator for arbeidsområdet kan du tillate brukere å justere beregningskonfigurasjoner (egenskaper på øktnivå som inkluderer Driver/Executor Core, Driver/Executor Memory) for individuelle elementer, for eksempel notatblokker, Spark-jobbdefinisjoner ved hjelp av Miljø.

Hvis innstillingen er deaktivert av administratoren for arbeidsområdet, brukes standardutvalget og databehandlingskonfigurasjonene for alle miljøer i arbeidsområdet.
Miljø
Miljøet gir fleksible konfigurasjoner for å kjøre Spark-jobber (notatblokker, Spark-jobbdefinisjoner). I et miljø kan du konfigurere beregningsegenskaper, velge ulike kjøretids-, installasjonsbibliotekpakkeavhengigheter basert på arbeidsbelastningskravene dine.
I miljøfanen har du muligheten til å angi standardmiljøet. Du kan velge hvilken versjon av Spark du vil bruke for arbeidsområdet.
Som administrator for fabric-arbeidsområdet kan du velge et miljø som standardmiljø for arbeidsområdet.
Du kan også opprette en ny gjennom rullegardinlisten Miljø .

Hvis du deaktiverer alternativet for å ha et standardmiljø, kan du velge Fabric Runtime-versjonen fra de tilgjengelige kjøretidsversjonene som er oppført i rullegardinlisten.

Mer informasjon om Apache Spark runtimes.
Prosjekter
Jobbinnstillinger gjør det mulig for administratorer å kontrollere jobbopptakslogikken for alle Spark-jobbene i arbeidsområdet.

Som standard er alle arbeidsområder aktivert med optimistisk jobbopptak. Lær mer om Jobbopptak for Spark i Microsoft Fabric.
Du kan gjøre det mulig for reserven maksimale kjerner for aktive Spark-jobber å slå av optimistisk jobbopptaksbasert tilnærming og reservere maksimale kjerner for Spark-jobbene sine.
Du kan også angi tidsavbruddet for Spark-økten for å tilpasse utløpsdatoen for økten for alle interaktive økter for notatblokken.
Merk
Standard øktutløp er satt til 20 minutter for de interaktive Spark-øktene.
Høy samtidighet
Med høy samtidighetsmodus kan brukere dele de samme Spark-øktene i Apache Spark for Fabric-datateknikk og datavitenskapelige arbeidsbelastninger. Et element som en notatblokk bruker en Spark-økt for kjøringen, og når det er aktivert, kan brukere dele én enkelt Spark-økt på tvers av flere notatblokker.

Mer informasjon om Høy samtidighet i Apache Spark for Fabric.
Automatisk logging for Machine Learning-modeller og eksperimenter
Administratorer kan nå aktivere autologging for maskinlæringsmodeller og eksperimenter. Dette alternativet registrerer automatisk verdiene for inndataparametere, utdatadata og utdataelementer i en maskinlæringsmodell etter hvert som den blir opplært. Mer informasjon om autologging.

Relatert innhold
- Les om Apache Spark Runtimes in Fabric – Oversikt, versjonskontroll, støtte for flere kjøretider og oppgradering av Delta Lake Protocol.
- Mer informasjon fra den offentlige Apache Spark-dokumentasjonen.
- Finn svar på vanlige spørsmål: Vanlige spørsmål om administrasjon av Apache Spark-arbeidsområder.