Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
I denne hurtiginnføringen lærer du hvordan dataflyter og datasamlebånd fungerer sammen for å opprette en kraftig Data Factory-løsning. Du renser data med dataflyter og flytter dem med datasamlebånd.
Forutsetninger
Før du begynner, trenger du:
- En leierkonto med et aktivt abonnement. Opprett en gratis konto.
- Et Microsoft Fabric-aktivert arbeidsområde: Konfigurer et arbeidsområde som ikke er standard Mitt arbeidsområde.
- En Azure SQL-database med tabelldata.
- en Blob Storage-konto.
Sammenlign dataflyter og datasamlebånd
Dataflyter Gen2 gir et lavkodegrensesnitt med 300+ data- og AI-baserte transformasjoner. Du kan enkelt rense, klargjøre og transformere data med fleksibilitet. Datasamlebånd tilbyr rike dataorkestreringsfunksjoner for å komponere fleksible dataarbeidsflyter som oppfyller bedriftens behov.
I et samlebånd kan du opprette logiske grupperinger av aktiviteter som utfører en oppgave. Dette kan omfatte å kalle en dataflyt for å rense og klargjøre dataene. Selv om det er noe funksjonalitetsoverlapping mellom de to, avhenger valget av om du trenger alle funksjonene til datasamlebånd eller kan bruke de enklere funksjonene til dataflyter. Hvis du vil ha mer informasjon, kan du se beslutningsveiledningen for struktur.
Transformere data med dataflyter
Følg disse trinnene for å konfigurere dataflyten.
Opprette en dataflyt
Velg det strukturaktiverte arbeidsområdet, deretter Ny, og velg Dataflow Gen2.
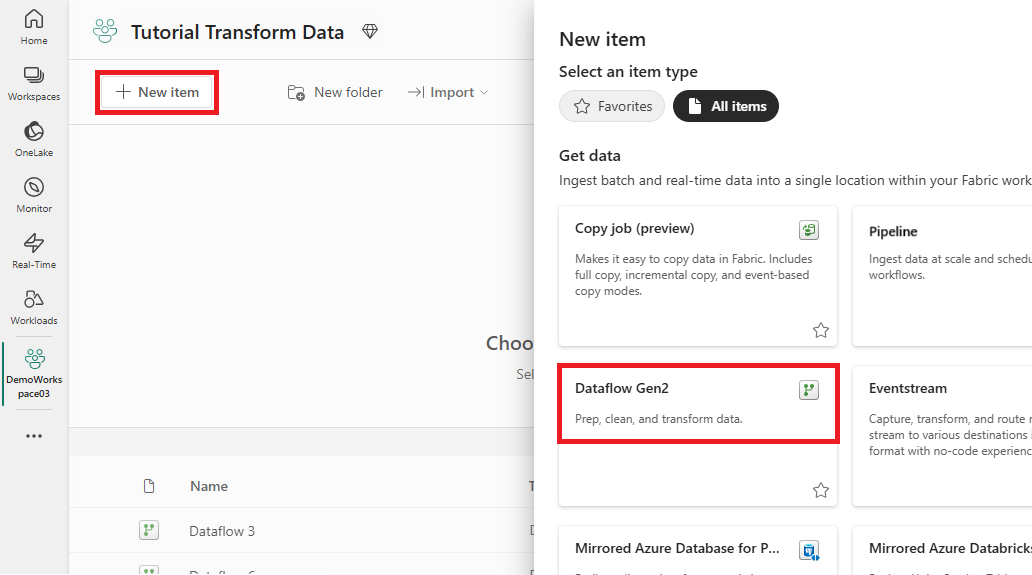
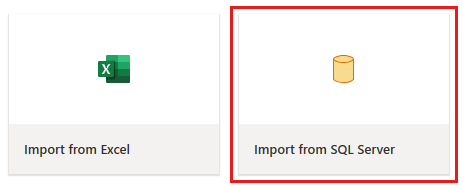
I redigeringsprogrammet for dataflyt velger du Importer fra SQL Server.


Hent data
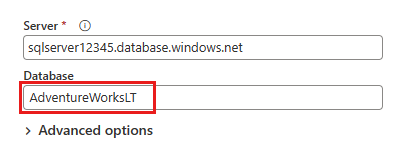
I dialogboksen Koble til datakilde angir du Azure SQL-databasedetaljene og velger Neste. Bruk AdventureWorksLT-eksempeldatabasen fra forutsetningene.
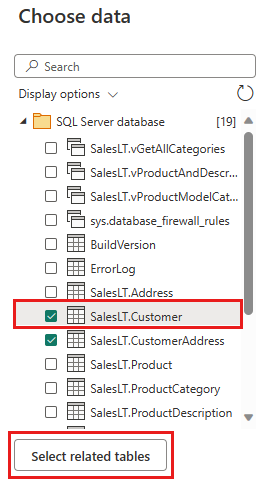
Velg dataene som skal transformeres, for eksempel SalesLT.Customer, og bruk Velg relaterte tabeller til å inkludere relaterte tabeller. Velg deretter Opprett.


Transformer dataene dine
Velg Diagramvisning fra statuslinjen eller Vis-menyen i Power Query-redigeringsprogrammet.
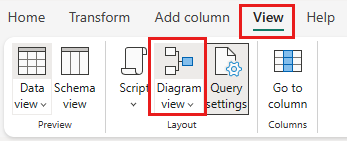
Høyrevelg SalesLT-kundespørringen , eller velg den loddrette ellipsen til høyre for spørringen, og velg deretter Slå sammen spørringer.
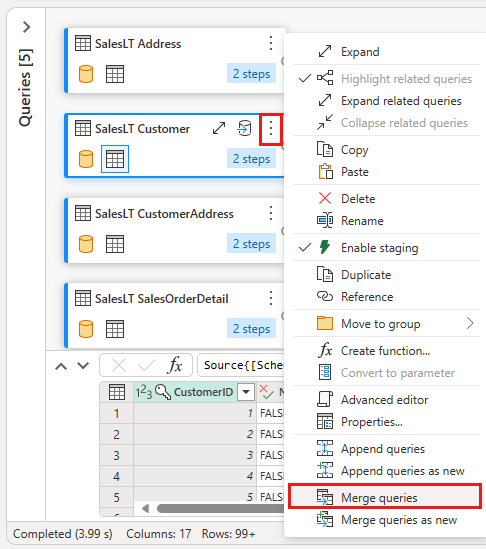
Konfigurer flettingen med SalesLTOrderHeader som høyre tabell, CustomerID som sammenføyningskolonne og Venstre ytre som sammenføyningstype. Velg OK.
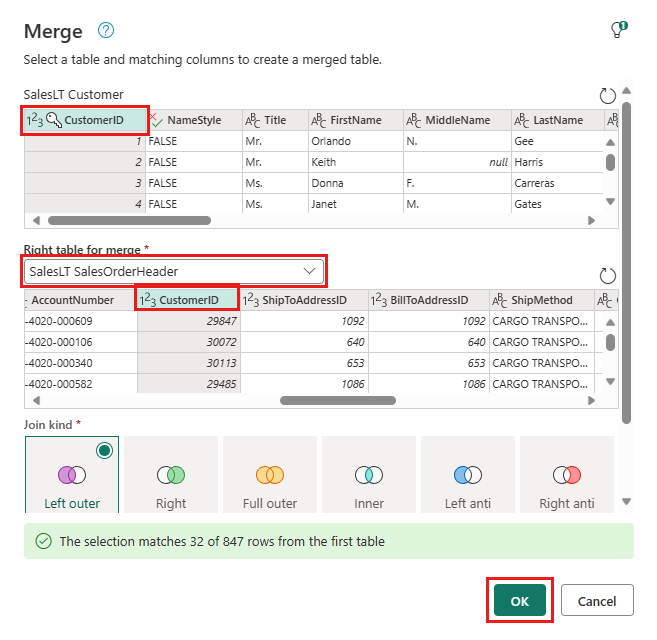
Legg til et datamål ved å velge databasesymbolet med en pil. Velg Azure SQL-database som måltype.
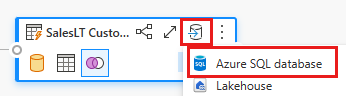
Oppgi detaljene for Azure SQL-databasetilkoblingen der flettespørringen skal publiseres. I dette eksemplet bruker vi også AdventureWorksLT-databasen vi brukte som datakilde for målet.
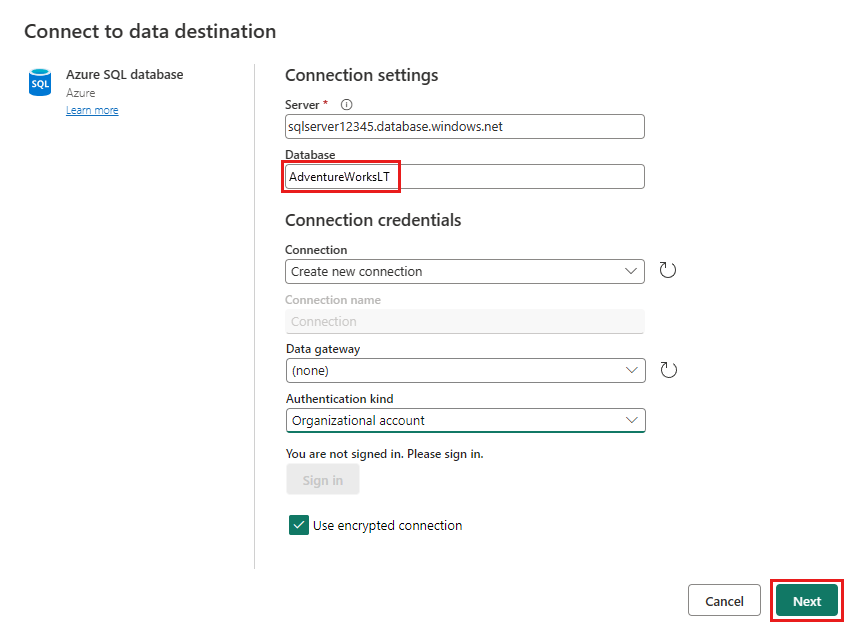
Velg en database for å lagre dataene, og angi et tabellnavn, og velg deretter Neste.
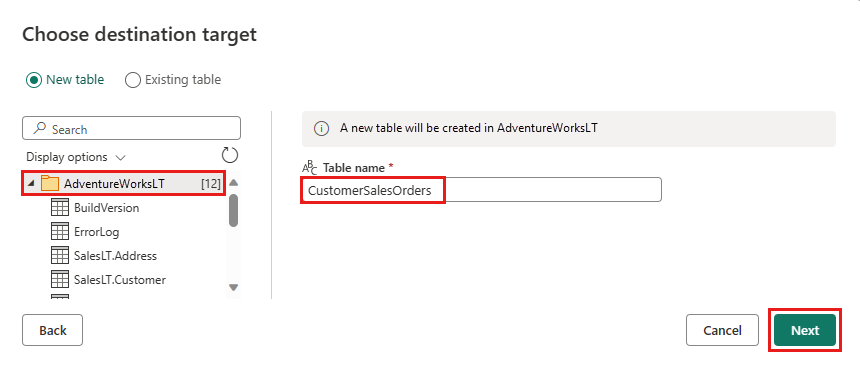
Godta standardinnstillingene i dialogboksen Velg destinasjonsinnstillinger , og velg Lagre innstillinger.
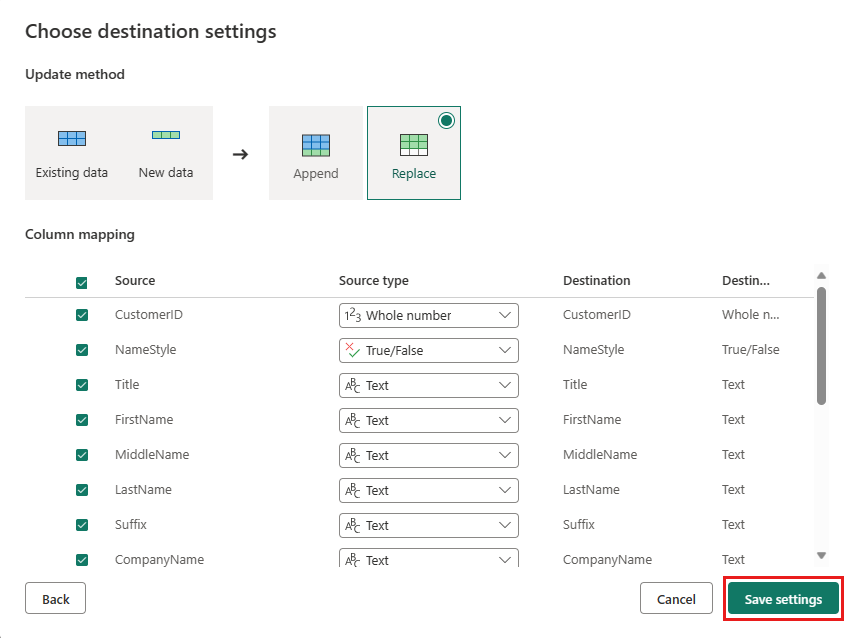
Velg Publiser i redigeringsprogrammet for dataflyt for å publisere dataflyten.



Flytt data med datasamlebånd
Nå som du har opprettet en Dataflow Gen2, kan du operere på den i et datasamlebånd. I dette eksemplet kopierer du dataene som genereres fra dataflyten, til tekstformat i en Azure Blob Storage-konto.
Opprett et nytt datasamlebånd
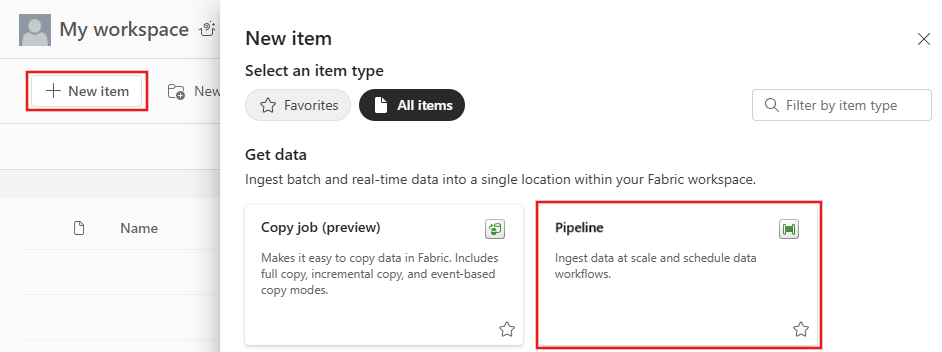
I arbeidsområdet velger du Ny og deretter Pipeline.
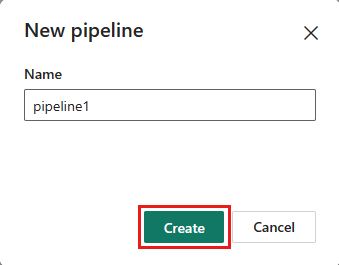
Gi datasamlebåndet et navn, og velg Opprett.
Konfigurer dataflyten
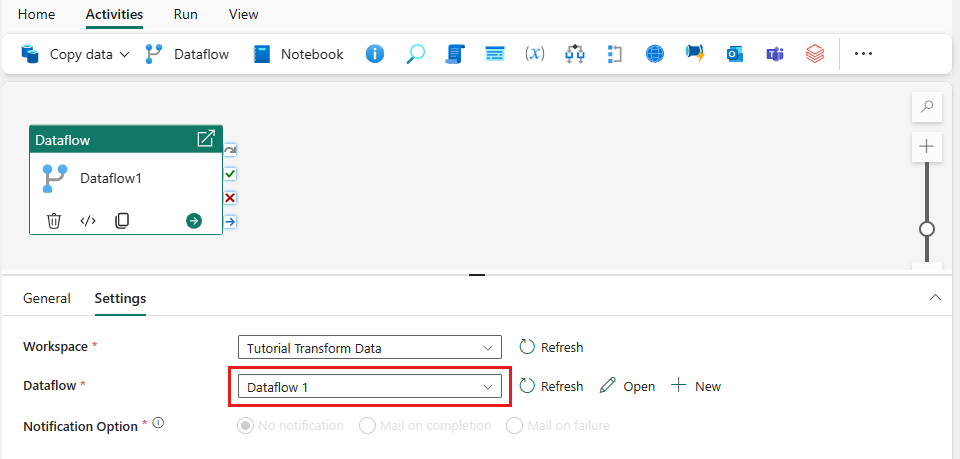
Legg til en dataflytaktivitet i datasamlebåndet ved å velge Dataflyt i Aktiviteter-fanen .

Velg dataflyten på pipelinelerretet, gå til Innstillinger-fanen , og velg dataflyten du opprettet tidligere.
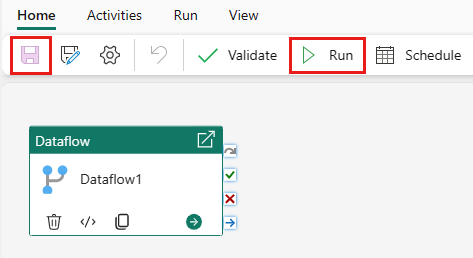
Velg Lagre og deretter Kjør for å fylle ut den sammenslåtte spørringstabellen.
Legge til en kopiaktivitet
Velg Kopier data på lerretet, eller bruk kopieringsassistenten fra Aktiviteter-fanen .
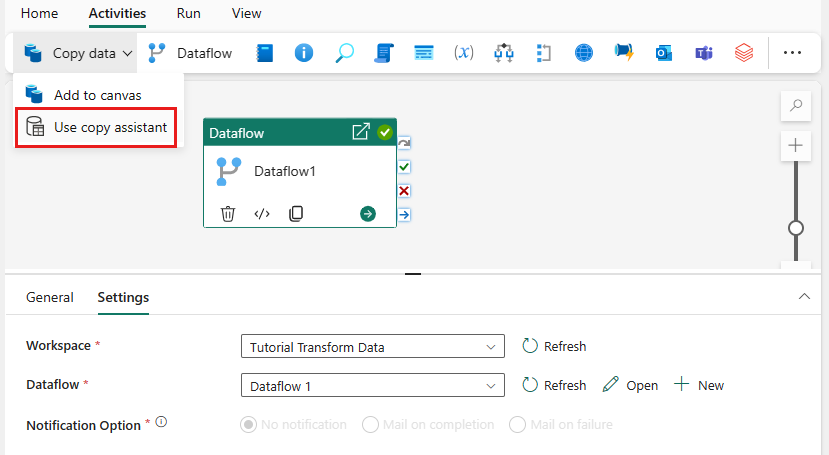
Velg Azure SQL Database som datakilde, og velg Neste.
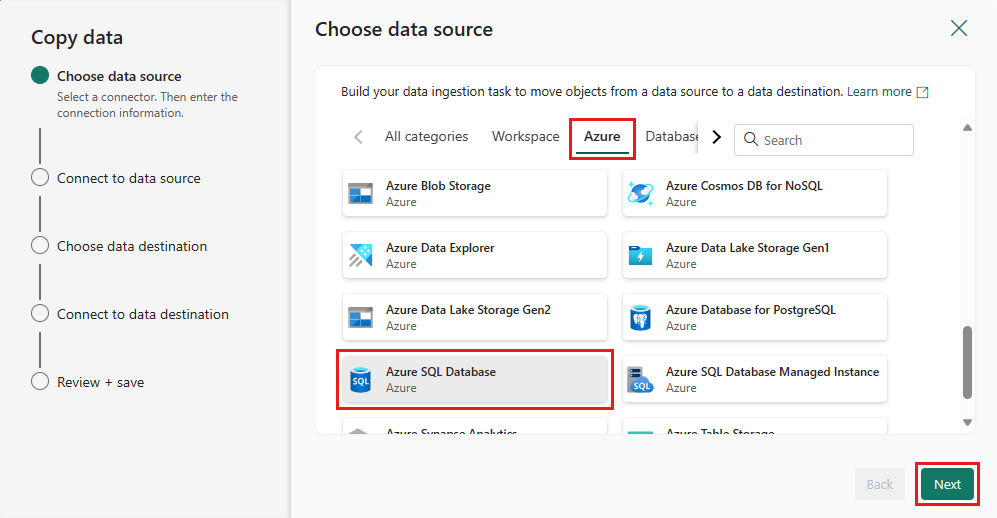
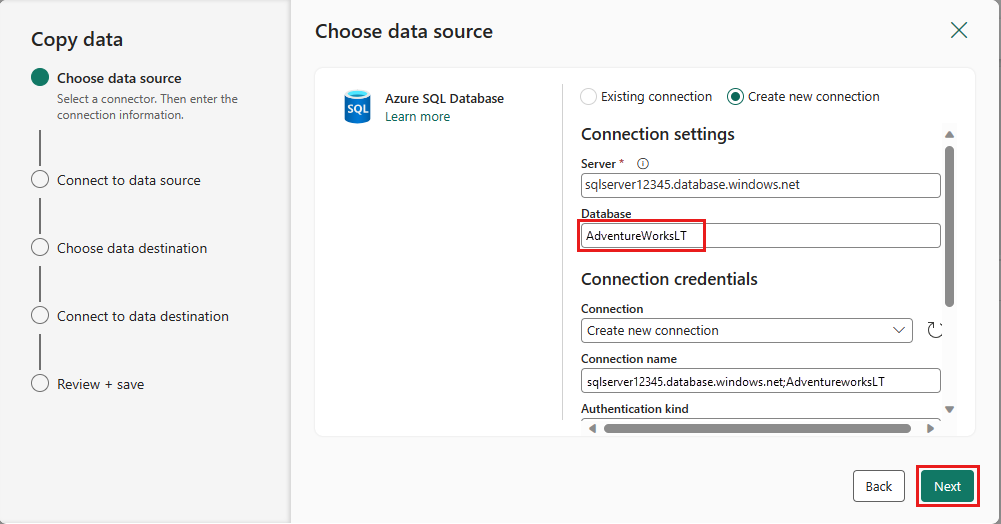
Opprett en tilkobling til datakilden ved å velge Opprett ny tilkobling. Fyll ut den nødvendige tilkoblingsinformasjonen i panelet, og skriv inn AdventureWorksLT for databasen, der vi genererte flettespørringen i dataflyten. Velg deretter Neste.
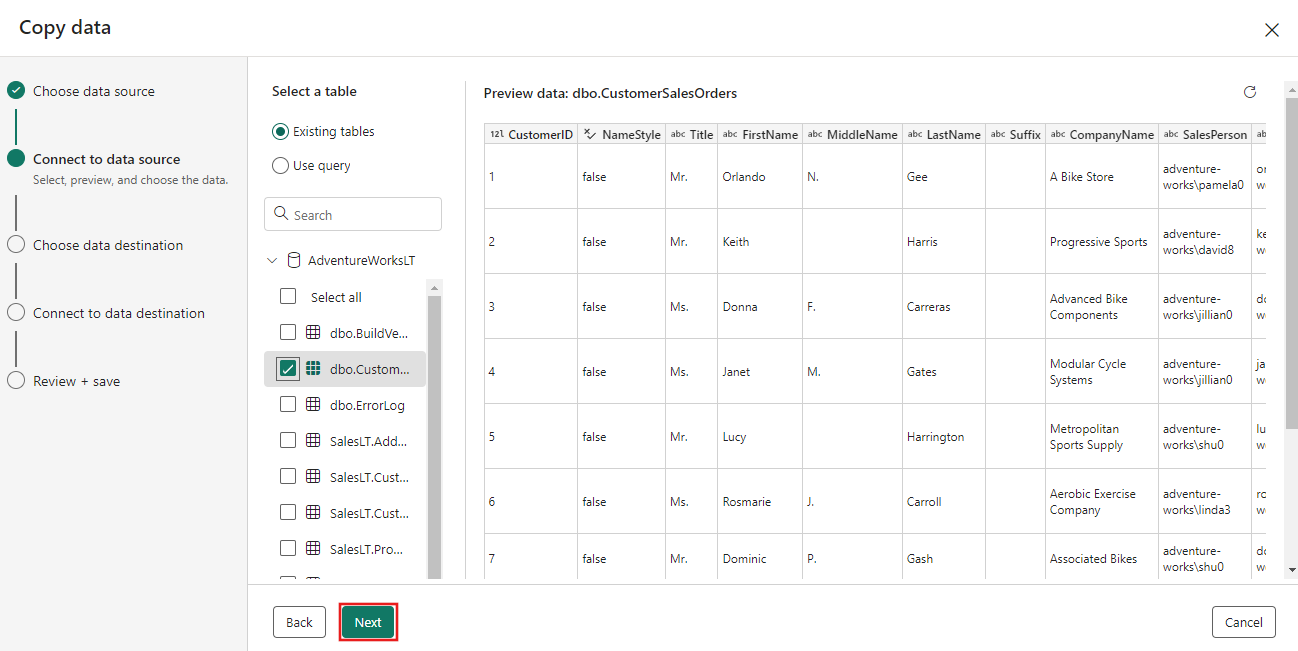
Velg tabellen du genererte i dataflyttrinnet tidligere, og velg deretter Neste.
Velg Azure Blob Storage for målet, og velg deretter Neste.
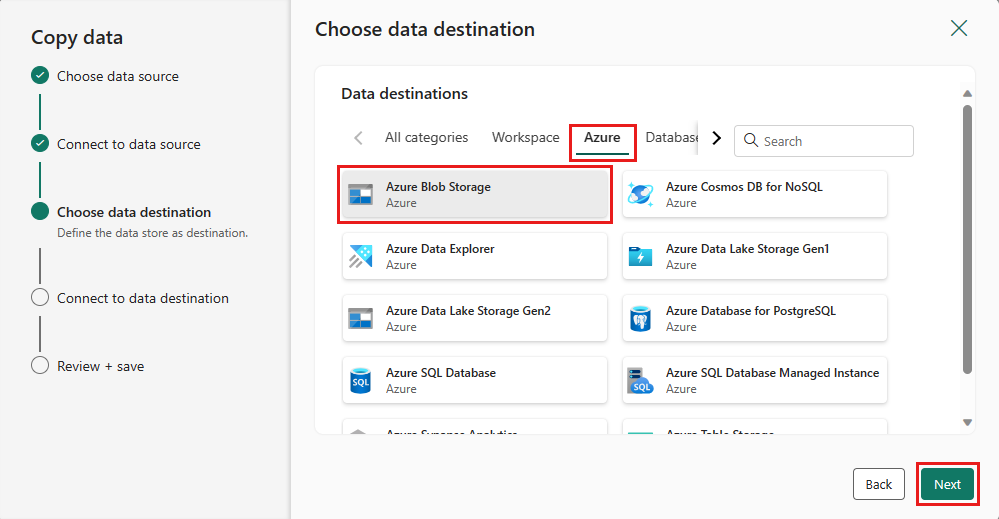
Opprett en tilkobling til målet ved å velge Opprett ny tilkobling. Angi detaljene for tilkoblingen, og velg deretter Neste.
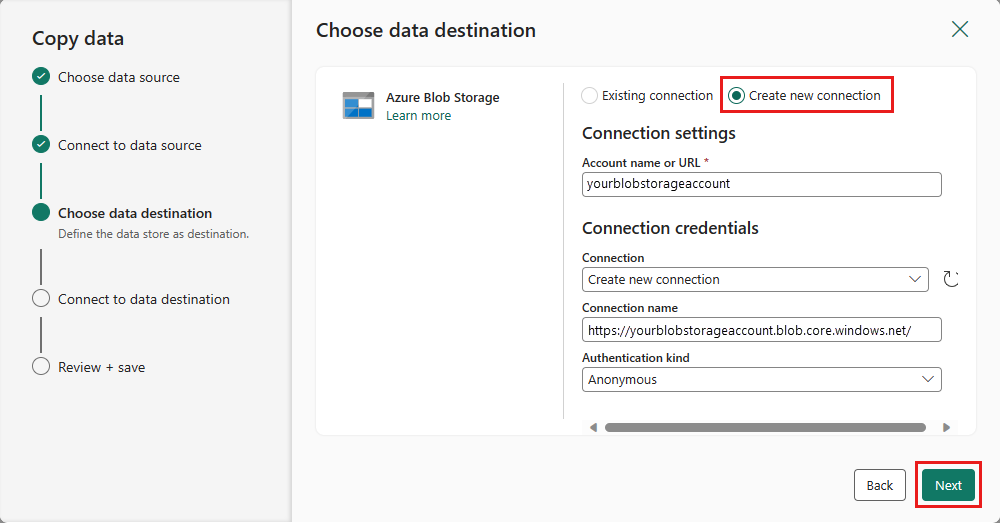
Velg mappebane, og angi et Filnavn, og velg deretter Neste.
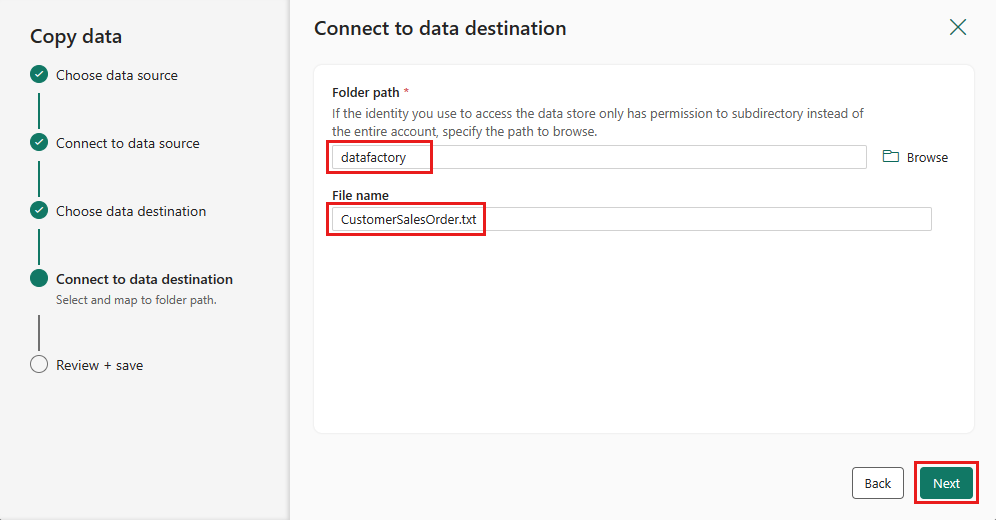
Velg Neste på nytt for å godta standard filformat, kolonneskilletegn, radskilletegn og komprimeringstype, eventuelt inkludert en overskrift.
Fullfør innstillingene. Deretter kan du se gjennom og velge Lagre + Kjør for å fullføre prosessen.
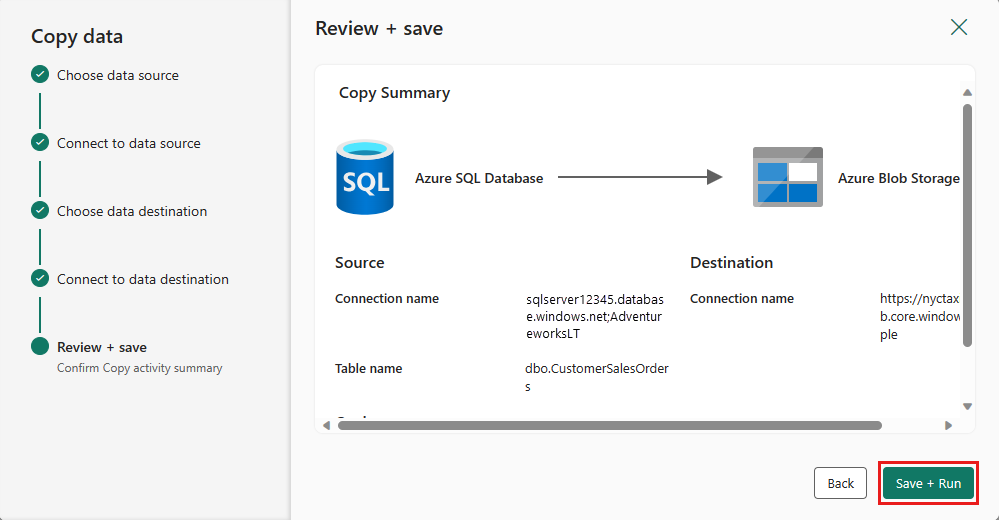
Utform datasamlebåndet og lagre for å kjøre og laste inn data
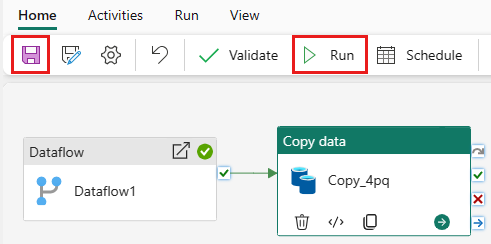
Hvis du vil kjøre aktiviteten Kopier etter dataflyt, drar du fra Vellykket på dataflytaktiviteten til aktiviteten Kopier. Aktiviteten Kopier kjører bare etter at dataflytaktiviteten lykkes.

Velg Lagre for å lagre datasamlebåndet. Velg deretter Kjør for å kjøre datasamlebåndet og laste inn dataene.
Planlegg kjøring av datasamlebånd
Når du er ferdig med å utvikle og teste datasamlebåndet, kan du planlegge at det skal kjøres automatisk.
Velg
Planlegg på fanen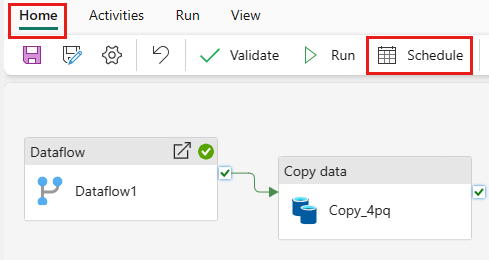
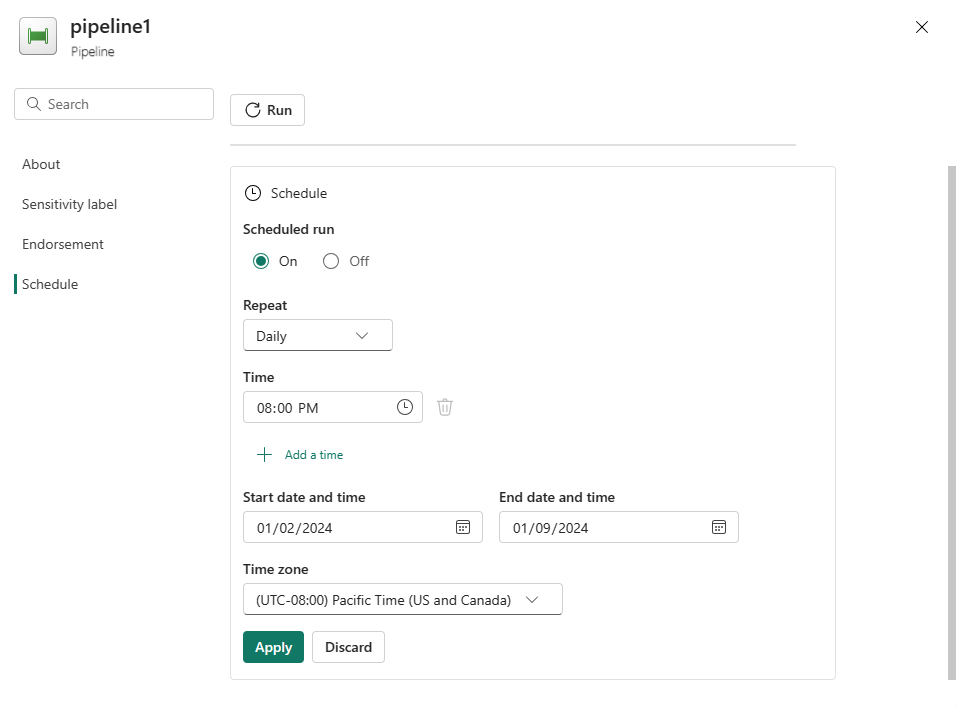
Konfigurer tidsplanen etter behov. Eksemplet her planlegger at pipelinen skal kjøre daglig kl. 20:00 til slutten av året.
Relatert innhold
Dette eksemplet viser deg hvordan du oppretter og konfigurerer en Dataflyt gen2 til å opprette en flettespørring og lagre den i en Azure SQL-database, og deretter kopiere data fra databasen til en tekstfil i Azure Blob Storage. Du lærte å gjøre følgende:
- Opprett en dataflyt.
- Transformer data med dataflyten.
- Opprett et datasamlebånd ved hjelp av dataflyten.
- Bestill utførelsen av trinnene i datasamlebåndet.
- Kopier data med kopieringsassistenten.
- Kjør og planlegg datasamlebåndet.
Deretter kan du gå videre for å lære mer om overvåking av datasamlebåndkjøringer.