Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Denne opplæringen tar 15 minutter, og beskriver hvordan du trinnvis samler inn data i et lakehouse ved hjelp av Dataflow Gen2.
Trinnvis innsamling av data i et datamål krever en teknikk for å laste inn bare nye eller oppdaterte data i datamålet. Denne teknikken kan gjøres ved hjelp av en spørring for å filtrere dataene basert på datamålet. Denne opplæringen viser hvordan du oppretter en dataflyt for å laste inn data fra en OData-kilde til et lakehouse, og hvordan du legger til en spørring i dataflyten for å filtrere dataene basert på datamålet.
Trinnene på høyt nivå i denne opplæringen er som følger:
- Opprett en dataflyt for å laste inn data fra en OData-kilde til et lakehouse.
- Legg til en spørring i dataflyten for å filtrere dataene basert på datamålet.
- (Valgfritt) laster inn data på nytt ved hjelp av notatblokker og datasamlebånd.
Forutsetning
Du må ha et Microsoft Fabric-aktivert arbeidsområde. Hvis du ikke allerede har et, kan du se Opprette et arbeidsområde. Opplæringen forutsetter også at du bruker diagramvisningen i Dataflyt gen2. Hvis du vil kontrollere om du bruker diagramvisningen, går du til Vis på det øverste båndet og kontrollerer at diagramvisning er valgt.
Opprette en dataflyt for å laste inn data fra en OData-kilde til et lakehouse
I denne delen oppretter du en dataflyt for å laste inn data fra en OData-kilde til et lakehouse.
Opprett et nytt lakehouse i arbeidsområdet.
Opprett en ny Dataflyt gen2 i arbeidsområdet.
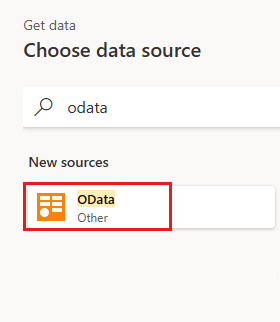
Legg til en ny kilde i dataflyten. Velg OData-kilden, og skriv inn følgende URL-adresse:
https://services.OData.org/V4/Northwind/Northwind.svc
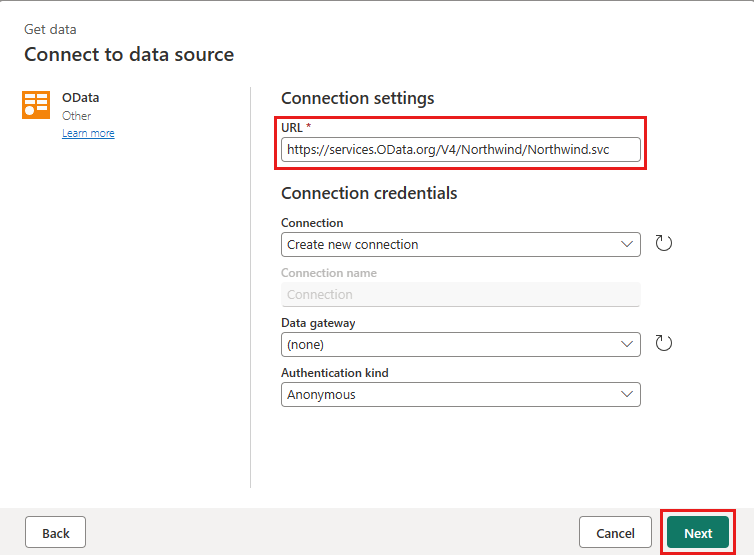
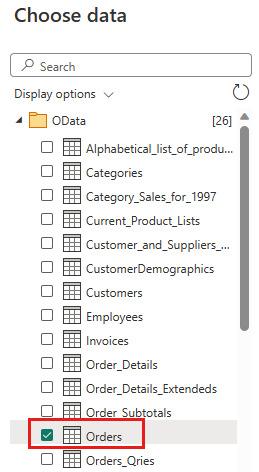
Velg Ordrer-tabellen, og velg Neste.
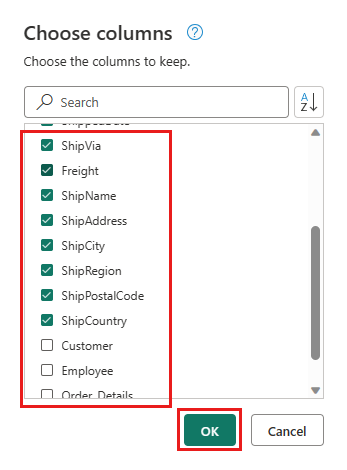
Velg følgende kolonner du vil beholde:
OrderIDCustomerIDEmployeeIDOrderDateRequiredDateShippedDateShipViaFreightShipNameShipAddressShipCityShipRegionShipPostalCodeShipCountry
Endre datatype
OrderDatefor ,RequiredDateogShippedDatetildatetime.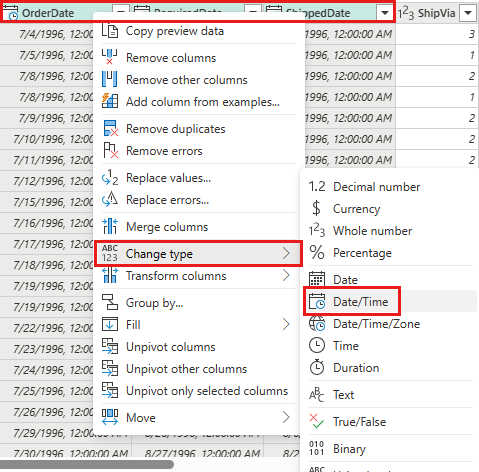
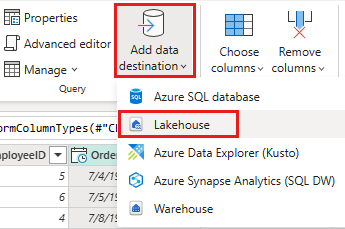
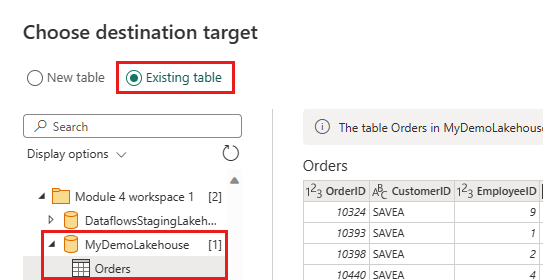
Konfigurer datamålet til lakehouse ved hjelp av følgende innstillinger:
- Datamål:
Lakehouse - Lakehouse: Velg lakehouse du opprettet i trinn 1.
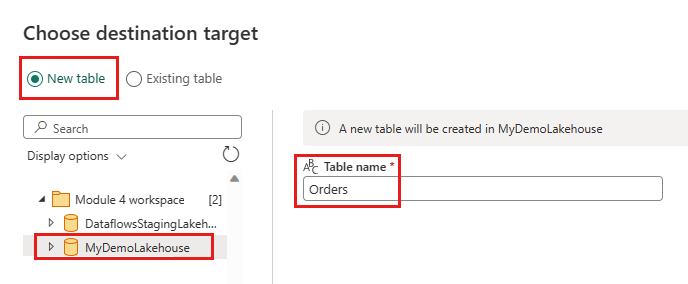
- Nytt tabellnavn:
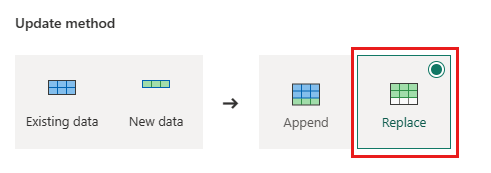
Orders - Oppdateringsmetode:
Replace
- Datamål:
velg Neste , og publiser dataflyten.



Du har nå opprettet en dataflyt for å laste inn data fra en OData-kilde til et lakehouse. Denne dataflyten brukes i neste del til å legge til en spørring i dataflyten for å filtrere dataene basert på datamålet. Deretter kan du bruke dataflyten til å laste inn data på nytt ved hjelp av notatblokker og datasamlebånd.
Legge til en spørring i dataflyten for å filtrere dataene basert på datamålet
Denne delen legger til en spørring i dataflyten for å filtrere dataene basert på dataene i målsjøen. Spørringen får maksimalt i OrderID lakehouse i begynnelsen av dataflytoppdateringen og bruker den maksimale OrderId til å bare få ordrene med en høyere OrderId fra til kilde for å tilføye til datamålet. Dette forutsetter at ordrer legges til kilden i stigende rekkefølge av OrderID. Hvis dette ikke er tilfelle, kan du bruke en annen kolonne til å filtrere dataene. Du kan for eksempel bruke OrderDate kolonnen til å filtrere dataene.
Merk
OData-filtre brukes i Fabric etter at dataene er mottatt fra datakilden, men for databasekilder som SQL Server brukes filteret i spørringen som sendes til serverdeldatakilden, og bare filtrerte rader returneres til tjenesten.
Når dataflyten er oppdatert, åpner du dataflyten du opprettet i forrige del.
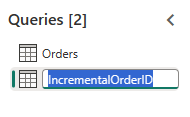
Opprett en ny spørring med navnet
IncrementalOrderIDog hent data fra Ordrer-tabellen i lakehouse du opprettet i forrige del.
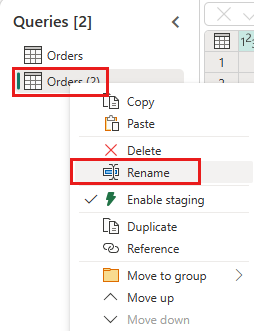
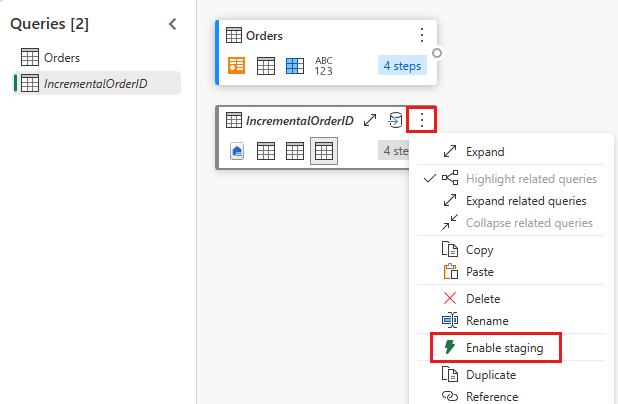
Deaktiver oppsamling av denne spørringen.
Høyreklikk kolonnen i forhåndsvisningen av
OrderIDdata, og velg Drill ned.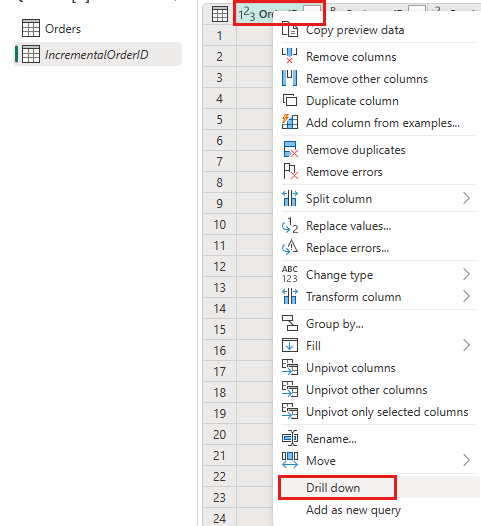
Velg Listeverktøy -Statistikk> fra båndet.
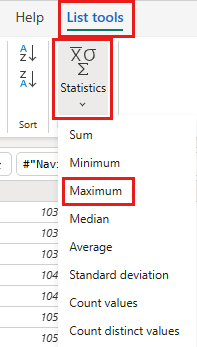
Du har nå en spørring som returnerer maksimal ordre-ID i lakehouse. Denne spørringen brukes til å filtrere dataene fra OData-kilden. Den neste delen legger til en spørring i dataflyten for å filtrere dataene fra OData-kilden basert på maksimal OrdreID i lakehouse.
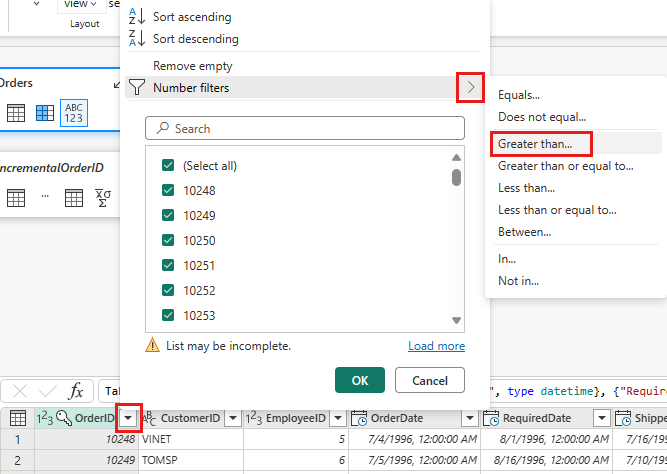
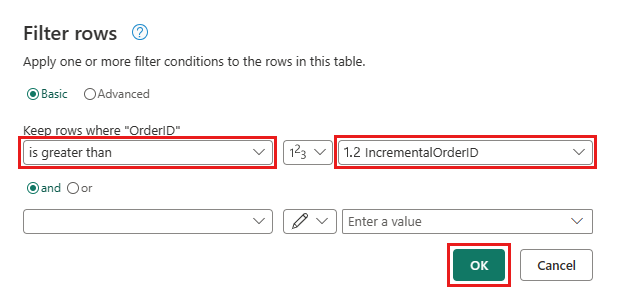
Gå tilbake til Ordrer-spørringen, og legg til et nytt trinn for å filtrere dataene. Bruk følgende innstillinger:
- Kolonne:
OrderID - Operasjon:
Greater than - Verdi: parameter
IncrementalOrderID
- Kolonne:
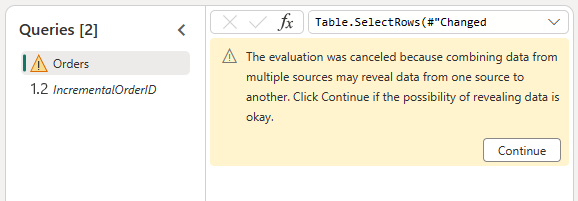
Tillat kombinasjon av data fra OData-kilden og lakehouse ved å bekrefte følgende dialogboks:
Oppdater datamålet for å bruke følgende innstillinger:
- Oppdateringsmetode:
Append

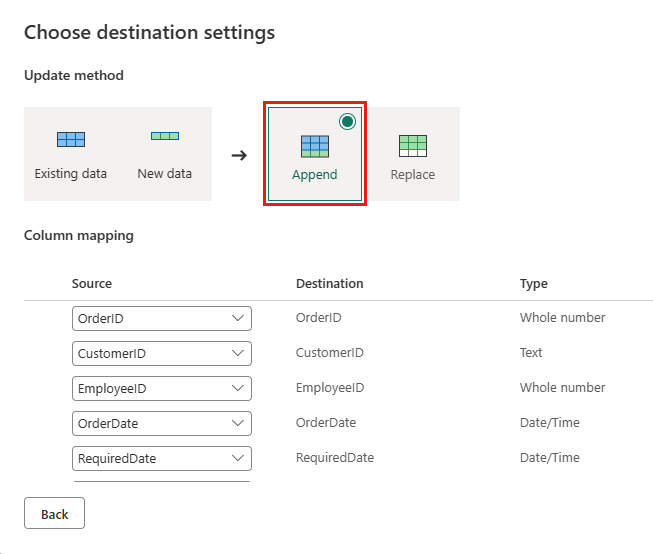
- Oppdateringsmetode:
Publiser dataflyten.
Dataflyten inneholder nå en spørring som filtrerer dataene fra OData-kilden basert på maksimal OrdreID i lakehouse. Dette betyr at bare nye eller oppdaterte data lastes inn i lakehouse. Den neste delen bruker dataflyten til å laste inn data på nytt ved hjelp av notatblokker og datasamlebånd.
(Valgfritt) laster inn data på nytt ved hjelp av notatblokker og datasamlebånd
Du kan eventuelt laste inn bestemte data på nytt ved hjelp av notatblokker og datasamlebånd. Med egendefinert python-kode i notatblokken fjerner du de gamle dataene fra lakehouse. Når du oppretter et datasamlebånd der du først kjører notatblokken og kjører dataflyten sekvensielt, laster du dataene fra OData-kilden inn i lakehouse. Notatblokker støtter flere språk, men denne opplæringen bruker PySpark. Pyspark er en Python-API for Spark og brukes i denne opplæringen til å kjøre Spark SQL-spørringer.
Opprett en ny notatblokk i arbeidsområdet.
Legg til følgende PySpark-kode i notatblokken:
### Variables LakehouseName = "YOURLAKEHOUSE" TableName = "Orders" ColName = "OrderID" NumberOfOrdersToRemove = "10" ### Remove Old Orders Reload = spark.sql("SELECT Max({0})-{1} as ReLoadValue FROM {2}.{3}".format(ColName,NumberOfOrdersToRemove,LakehouseName,TableName)).collect() Reload = Reload[0].ReLoadValue spark.sql("Delete from {0}.{1} where {2} > {3}".format(LakehouseName, TableName, ColName, Reload))Kjør notatblokken for å bekrefte at dataene er fjernet fra lakehouse.
Opprett et nytt datasamlebånd i arbeidsområdet.
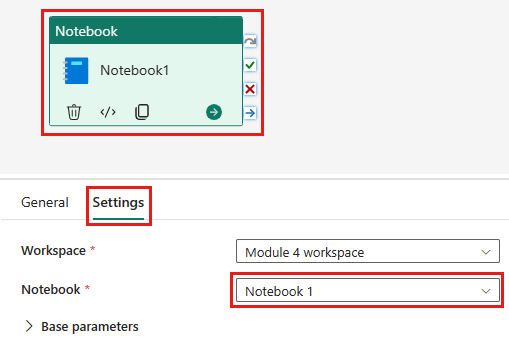
Legg til en ny notatblokkaktivitet i datasamlebåndet, og velg notatblokken du opprettet i forrige trinn.
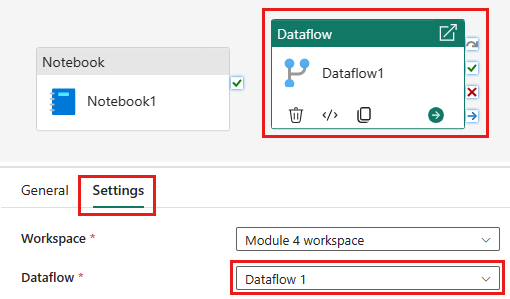
Legg til en ny dataflytaktivitet i datasamlebåndet, og velg dataflyten du opprettet i forrige del.
Koble notatblokkaktiviteten til dataflytaktiviteten med en vellykket utløser.
Lagre og kjør datasamlebåndet.


Du har nå et datasamlebånd som fjerner gamle data fra lakehouse og laster dataene fra OData-kilden inn i lakehouse. Med dette oppsettet kan du laste inn dataene fra OData-kilden regelmessig i lakehouse.