Oppskrift: Azure AI-tjenester - Multivariate Anomaly Detection
Denne oppskriften viser hvordan du kan bruke SynapseML- og Azure AI-tjenester på Apache Spark for flervariat avviksgjenkjenning. Multivariate anomaly detection allows for the detection of anomalies among many variables or time series, taking into account all the inter-correlations and dependencies between the different variables. I dette scenarioet bruker vi SynapseML til å lære opp en modell for flervariat avviksgjenkjenning ved hjelp av Azure AI-tjenestene, og vi bruker deretter modellen til å utlede multivariate anomalier i et datasett som inneholder syntetiske målinger fra tre IoT-sensorer.
Viktig
Fra og med 20. september 2023 kan du ikke opprette nye avviksdetektor ressurser. Den avviksdetektor tjenesten blir pensjonert den 1 oktober 2026.
Hvis du vil ha mer informasjon om Azure AI-avviksdetektor, kan du se denne dokumentasjonssiden.
Forutsetning
- Et Azure-abonnement – Opprett et gratis
- Legg notatblokken til et lakehouse. På venstre side velger du Legg til for å legge til et eksisterende innsjøhus eller opprette et innsjøhus.
Oppsett
Følg instruksjonene for å opprette en Anomaly Detector ressurs ved hjelp av Azure-portalen, eller du kan også bruke Azure CLI til å opprette denne ressursen.
Når du har konfigurert en Anomaly Detector, kan du utforske metoder for å håndtere data i ulike skjemaer. Katalogen over tjenester i Azure AI gir flere alternativer: Visjon, Tale, Språk, Websøk, Beslutning, Oversettelse og Dokumentintelligens.
Opprette en avviksdetektor ressurs
- Velg Opprett i ressursgruppen i Azure-portalen, og skriv deretter inn avviksdetektor. Velg den avviksdetektor ressursen.
- Gi ressursen et navn, og bruk ideelt sett samme område som resten av ressursgruppen. Bruk standardalternativene for resten, og velg deretter Se gjennom + Opprett og opprett.
- Når avviksdetektor ressursen er opprettet, åpner du den
Keys and Endpointsog velger panelet i venstre navigasjonsrute. Kopier nøkkelen for avviksdetektor ressursen til miljøvariabelenANOMALY_API_KEY, eller lagre den i variabelenanomalyKey.
Opprette en lagringskontoressurs
Hvis du vil lagre mellomliggende data, må du opprette en Azure Blob Storage-konto. Opprett en beholder for lagring av mellomliggende data i denne lagringskontoen. Noter beholdernavnet, og kopier tilkoblingsstreng til beholderen. Du trenger den senere for å fylle ut variabelen containerName og miljøvariabelen BLOB_CONNECTION_STRING .
Skriv inn tjenestenøklene
La oss starte med å konfigurere miljøvariablene for tjenestenøklene våre. Den neste cellen angir ANOMALY_API_KEY miljøvariablene og BLOB_CONNECTION_STRING miljøvariablene basert på verdiene som er lagret i Azure Key Vault. Hvis du kjører denne opplæringen i ditt eget miljø, må du kontrollere at du angir disse miljøvariablene før du fortsetter.
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Nå kan du lese ANOMALY_API_KEY og BLOB_CONNECTION_STRING miljøvariabler og angi containerName variablene og location variablene.
# An Anomaly Dectector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Først kobler vi til lagringskontoen vår slik at avviksdetektoren kan spare mellomliggende resultater der:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
La oss importere alle nødvendige moduler.
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.cognitive import *
La oss nå lese eksempeldataene våre i en Spark DataFrame.
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
Vi kan nå opprette et estimator objekt, som brukes til å lære opp modellen vår. Vi angir start- og sluttidspunkt for opplæringsdataene. Vi angir også inndatakolonnene som skal brukes, og navnet på kolonnen som inneholder tidsstempelene. Til slutt angir vi antall datapunkter som skal brukes i glidevinduet for avviksregistrering, og vi angir tilkoblingsstreng til Azure Blob Storage-kontoen.
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Nå som vi har opprettet estimator, kan vi tilpasse det til dataene:
model = estimator.fit(df)
```parameter
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in.
```python
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
Da vi ringte .show(5) i den forrige cellen, viste den oss de fem første radene i datarammen. Resultatene var alle null fordi de ikke var inne i slutningsvinduet.
Hvis du vil vise resultatene bare for de utsatte dataene, kan du velge kolonnene vi trenger. Vi kan deretter bestille radene i datarammen etter stigende rekkefølge, og filtrere resultatet slik at det bare viser radene som er i området i slutningsvinduet. I vårt tilfelle inferenceEndTime er det samme som den siste raden i datarammen, så det kan ignoreres.
Til slutt, for å kunne tegne inn resultatene bedre, kan du konvertere Spark-datarammen til en Pandas-dataramme.
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
contributors Formater kolonnen som lagrer bidragspoengsummen fra hver sensor til de oppdagede avvikene. Den neste cellen formaterer disse dataene, og deler bidragspoengsummen for hver sensor i sin egen kolonne.
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Flott! Vi har nå bidragsresultatene til sensorene 1, 2 og 3 i series_0henholdsvis kolonnene , series_1og .series_2
Kjør den neste cellen for å tegne inn resultatene. Parameteren minSeverity angir minimumsalvorlighetsgraden for avvikene som skal tegnes inn.
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
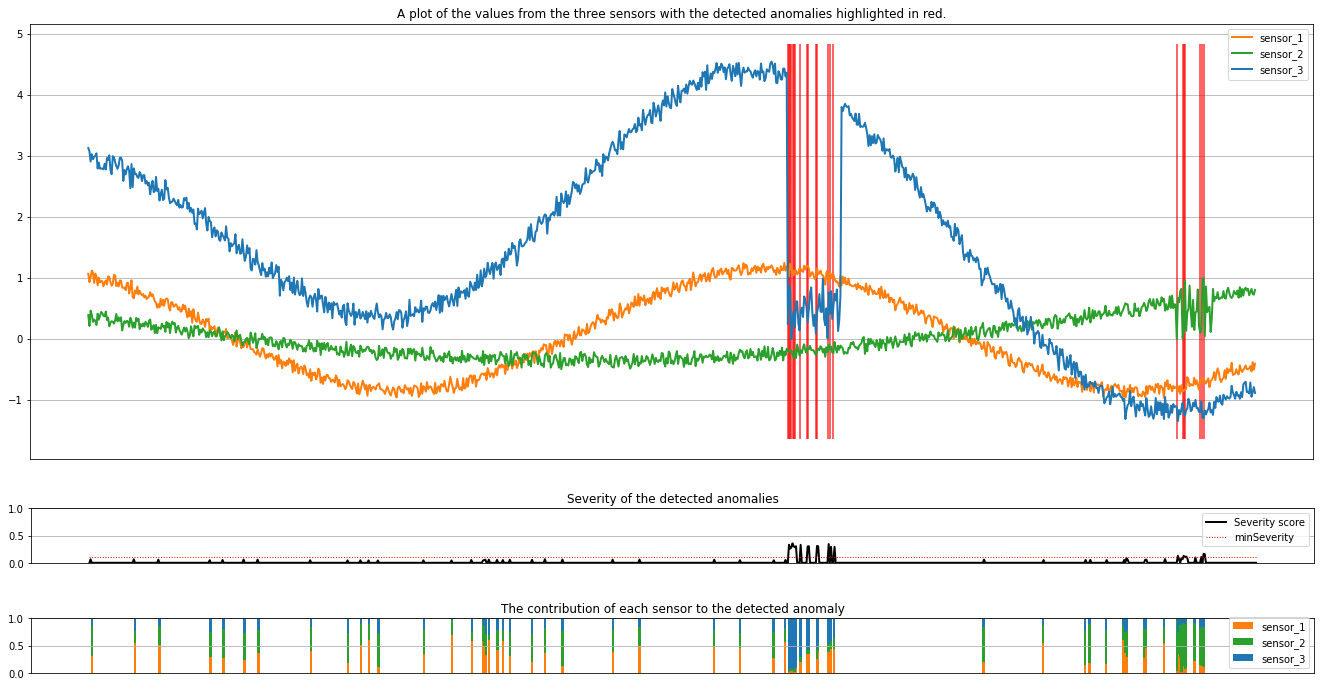
Plottene viser rådataene fra sensorene (inne i slutningsvinduet) i oransje, grønt og blått. De røde loddrette linjene i den første figuren viser de oppdagede avvikene som har en alvorlighetsgrad større enn eller lik minSeverity.
Det andre plottet viser alvorsgradspoengsummen for alle oppdagede avvik, med minSeverity terskelen vist i den prikkede røde linjen.
Til slutt viser det siste plottet bidraget fra dataene fra hver sensor til de oppdagede avvikene. Det hjelper oss å diagnostisere og forstå den mest sannsynlige årsaken til hver anomali.
Relatert innhold
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for