Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
En maskinlæringsmodell er en fil som er opplært til å gjenkjenne visse typer mønstre. Du lærer opp en modell over et sett med data, og du gir den en algoritme som bruker til å resonnere og lære av det datasettet. Når du har kalibrert modellen, kan du bruke den til å tenke over data som den aldri har sett før, og lage prognoser om disse dataene.
I MLflow-kan en maskinlæringsmodell inneholde flere modellversjoner. Her kan hver versjon representere en modell gjentakelse. I denne artikkelen lærer du hvordan du kan samhandle med ML-modeller for å spore og sammenligne modelliterasjoner.
I denne artikkelen lærer du hvordan du:
- Lag maskinlæringsmodeller i Microsoft Fabric
- Administrere og spore modellversjoner
- Sammenlign modellens ytelse på tvers av versjoner
- Bruk modeller for poengberegning og slutning
Opprette en maskinlæringsmodell
Du kan lage en maskinlæringsmodell fra Fabric UI eller programmatisk med MLflow API. I MLflow bruker modellene et standard pakkeformat som fungerer med ulike nedstrøms verktøy, inkludert batch-inferensering på Apache Spark. Formatet lagrer en modell i ulike "varianter" som ulike nedstrømsverktøy kan forstå.
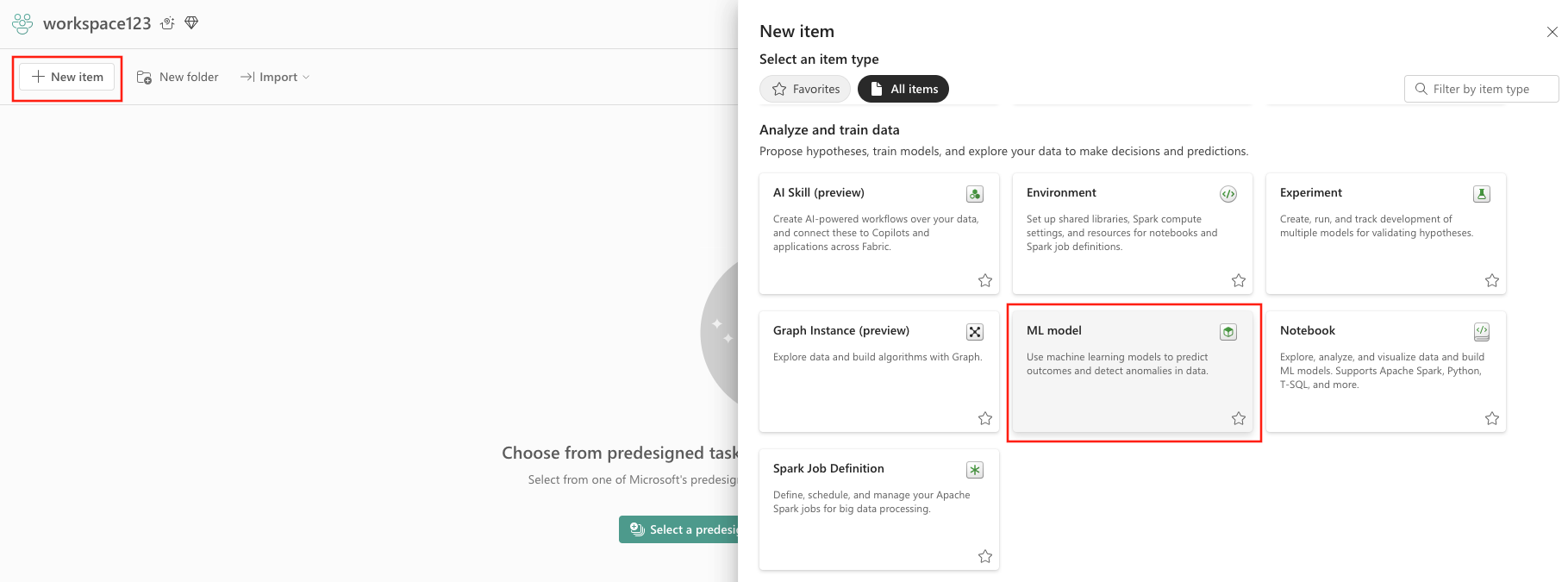
For å lage en maskinlæringsmodell fra brukergrensesnittet:
- Velg et eksisterende data science-arbeidsområde, eller opprett et nytt arbeidsområde.
- Opprett et nytt element via arbeidsområdet eller ved å bruke Opprett-knappen:
- Arbeidsområde:
- Velg arbeidsområdet.
- Velg Nytt element.
- Velg ML-modell under Analyser og lær opp data.
- Opprett-knapp:
- Velg Opprett, som du finner i ... fra den loddrette menyen.
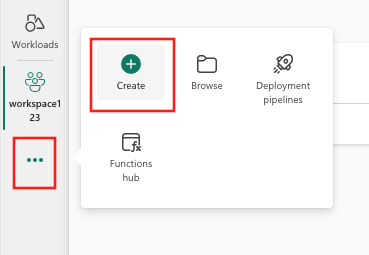
- Velg ML-modell under Data Science.

- Velg Opprett, som du finner i ... fra den loddrette menyen.
- Arbeidsområde:
- Etter at modellen er opprettet, kan du begynne å legge til modellversjoner for å spore kjøring av måledata og parametere. Registrer eller lagre eksperimentkjøringer i en eksisterende modell.



Du kan også opprette en maskinlæringsmodell direkte fra redigeringsopplevelsen med mlflow.register_model() API-en. Hvis en registrert maskinlæringsmodell med det angitte navnet ikke finnes, oppretter API-en den automatisk.
import mlflow
model_uri = "runs:/{}/model-uri-name".format(run.info.run_id)
mv = mlflow.register_model(model_uri, "model-name")
print("Name: {}".format(mv.name))
print("Version: {}".format(mv.version))
Administrere versjoner i en maskinlæringsmodell
En maskinlæringsmodell inneholder en samling modellversjoner for forenklet sporing og sammenligning. I en modell kan en dataforsker navigere på tvers av ulike modellversjoner for å utforske de underliggende parameterne og måledataene. Dataforskere kan også gjøre sammenligninger på tvers av modellversjoner for å identifisere om nyere modeller kan gi bedre resultater.
Notat
Med støtte for MLflow 3 i Fabric oppretter hver modell du logger med mlflow.<flavor>.log_model(model, name="...") en LoggedModel enhet som er koblet til kildekjøringen, parametere, metrikker, datasett og miljø. Du kan åpne en LoggedModel fra eksperimentsiden og registrere den som en ny ML-modell eller en ny versjon av en eksisterende modell. For detaljer, se MLflow 3 i Fabric Data Science.
Spor maskinlæringsmodeller
En maskinlæringsmodellversjon representerer en individuell modell som er registrert for sporing.
![]()
Hver modellversjon inneholder følgende informasjon:
| Eiendom | Beskrivelse |
|---|---|
| Tid skapt | Dato og klokkeslett for modellopprettelse. |
| Løpsnavn | Identifikatoren for eksperimentkjøringen ble brukt til å lage denne spesifikke modellversjonen. |
| Hyperparametere | Lagret som nøkkel-verdi-par. Både nøkler og verdier er strenger. |
| Beregninger | Kjør metrikker lagret som nøkkel-verdi-par. Verdien er numerisk. |
| Modellskjema/signatur | En beskrivelse av modellens input og output. |
| Loggede filer | Registrerte filer i hvilket som helst format. Du kan for eksempel ta opp bilder, miljø, modeller og datafiler. |
| Tags | Egendefinert metadata som nøkkel-verdi-par knyttet til kjøringer. Lær hvordan du påfører tagger. |
Bruke merker på maskinlæringsmodeller
MLflow-merking for modellversjoner gjør det mulig for brukere å knytte egendefinerte metadata til bestemte versjoner av en registrert modell i MLflow Model Registry. Disse kodene, som er lagret som nøkkelverdipar, hjelper deg med å organisere, spore og skille mellom modellversjoner, noe som gjør det enklere å administrere modelllivssykluser. Merker kan brukes til å angi modellens formål, distribusjonsmiljø eller annen relevant informasjon, noe som gjør det enklere å administrere og ta beslutninger i team.
Denne koden viser hvordan du lærer opp en RandomForestRegressor-modell ved hjelp av Scikit-learn, logger modellen og parameterne med MLflow, og registrerer deretter modellen i MLflow Model Registry med egendefinerte koder. Disse kodene inneholder nyttige metadata, for eksempel prosjektnavn, avdeling, team og prosjektkvarter, noe som gjør det enklere å administrere og spore modellversjonen.
import mlflow.sklearn
from mlflow.models import infer_signature
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
# Generate synthetic regression data
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
# Model parameters
params = {"n_estimators": 3, "random_state": 42}
# Model tags for MLflow
model_tags = {
"project_name": "grocery-forecasting",
"store_dept": "produce",
"team": "stores-ml",
"project_quarter": "Q3-2023"
}
# Log MLflow entities
with mlflow.start_run() as run:
# Train the model
model = RandomForestRegressor(**params).fit(X, y)
# Infer the model signature
signature = infer_signature(X, model.predict(X))
# Log parameters and the model
mlflow.log_params(params)
mlflow.sklearn.log_model(model, artifact_path="sklearn-model", signature=signature)
# Register the model with tags
model_uri = f"runs:/{run.info.run_id}/sklearn-model"
model_version = mlflow.register_model(model_uri, "RandomForestRegressionModel", tags=model_tags)
# Output model registration details
print(f"Model Name: {model_version.name}")
print(f"Model Version: {model_version.version}")
Når du har brukt kodene, kan du vise dem direkte på siden for modellversjonsdetaljer. I tillegg kan merker legges til, oppdateres eller fjernes fra denne siden når som helst.

Sammenligne og filtrere maskinlæringsmodeller
Hvis du vil sammenligne og evaluere kvaliteten på maskinlæringsmodellversjoner, kan du sammenligne parametere, måledata og metadata mellom valgte versjoner.
Sammenligne maskinlæringsmodeller visuelt
Du kan visuelt sammenligne kjøringer i en eksisterende modell. Visualobjektsammenligning gir enkel navigering mellom, og sorterer på tvers, flere versjoner.

Hvis du vil sammenligne kjøringer, kan du:
- Velg en eksisterende maskinlæringsmodell som inneholder flere versjoner.
- Velg fanen Vis, og gå deretter til modellliste visning. Du kan også velge alternativet for å Vis modellliste direkte fra detaljvisningen.
- Du kan tilpasse kolonnene i tabellen. Utvid Tilpass kolonner-ruten. Derfra kan du velge egenskapene, måledataene, kodene og hyperparameterne du vil se.
- Til slutt kan du velge flere versjoner, for å sammenligne resultatene, i måledatasammenligningsruten. Fra denne ruten kan du tilpasse diagrammene med endringer i diagramtittelen, visualiseringstypen, X-aksen, Y-aksen og mer.
Sammenligne maskinlæringsmodeller ved hjelp av API-en for MLflow
Dataforskere kan også bruke MLflow til å søke blant flere modeller som er lagret i arbeidsområdet. Gå til MLflow-dokumentasjonen for å utforske andre MLflow-API-er for modellsamhandling.
from pprint import pprint
from mlflow import MlflowClient
client = MlflowClient()
for rm in client.search_registered_models():
pprint(dict(rm), indent=4)
Bruke maskinlæringsmodeller
Når du har kalibrert en modell på et datasett, kan du bruke denne modellen på data den aldri så for å generere prognoser. Vi kaller denne modellen bruk teknikk scoring eller inferencing.
Fabric støtter flere tilnærminger for å anvende dine trente modeller:
- Batch-scoring: Bruk modellen din i stor skala på store datasett ved hjelp av Apache Spark. Dette er ideelt for å generere prediksjoner basert på historiske eller planlagte data.
- Sanntidsvurdering Distribuer modellen din til et endepunkt for on-demand-prediksjoner, nyttig for applikasjoner som trenger umiddelbare resultater.
For å komme i gang med å anvende modellene dine, velg tilnærmingen som passer din situasjon: