Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Gjelder for:✅ SQL Analytics-endepunkt og Warehouse i Microsoft Fabric
Henting av data fra datasjøen er avgjørende inndata-/utdataoperasjon (IO) med betydelige konsekvenser for spørringsytelsen. Fabric Data Warehouse bruker raffinerte tilgangsmønstre for å forbedre datalesninger fra lagring og øke kjøringshastigheten for spørringer. I tillegg minimerer det intelligent behovet for ekstern lagring ved å utnytte lokale hurtigbuffere.
Hurtigbufring er en teknikk som forbedrer ytelsen til databehandlingsprogrammer ved å redusere IO-operasjonene. Hurtigbufring lagrer ofte tilgjengelige data og metadata i et raskere lagringslag, for eksempel lokalt minne eller lokal SSD-disk, slik at etterfølgende forespørsler kan serveres raskere, direkte fra hurtigbufferen. Hvis et bestemt sett med data tidligere har blitt åpnet av en spørring, henter eventuelle etterfølgende spørringer disse dataene direkte fra minnehurtigbufferen. Denne tilnærmingen reduserer IO-ventetiden betydelig, ettersom lokale minneoperasjoner er spesielt raskere sammenlignet med henting av data fra ekstern lagring.
Hurtigbufring i minnet og disken i Fabric Data Warehouse er helt gjennomsiktig for brukeren. Uavhengig av opprinnelsen, enten det er en lagertabell, en OneLake-snarvei eller til og med OneLake-snarvei som refererer til ikke-Azure-tjenester, bufrer spørringen alle dataene den får tilgang til.
Det finnes to typer hurtigbuffere som er beskrevet senere i denne artikkelen, hurtigbuffer i minnet og diskbuffer. Hurtigbufring av resultatsett dekkes i en annen artikkel.
Hurtigbuffer i minnet
Når spørringen får tilgang til og henter data fra lagring, utfører den en transformasjonsprosess som omkoder dataene fra det opprinnelige filbaserte formatet til svært optimaliserte strukturer i minnehurtigbufferen.

Data i hurtigbufferen er organisert i et komprimert kolonneformat som er optimalisert for analytiske spørringer. Hver kolonne med data lagres sammen, atskilt fra de andre, noe som gir bedre komprimering siden lignende dataverdier lagres sammen, noe som fører til redusert minneavtrykk. Når spørringer må utføre operasjoner på en bestemt kolonne, for eksempel aggregater eller filtrering, kan motoren fungere mer effektivt siden den ikke trenger å behandle unødvendige data fra andre kolonner.
I tillegg bidrar denne kolonnebaserte lagringsplassen også til parallell behandling, noe som kan gjøre spørringskjøringen betydelig raskere for store datasett. Motoren kan utføre operasjoner på flere kolonner samtidig, og dra nytte av moderne flerkjerneprosessorer.
Denne tilnærmingen er spesielt nyttig for analytiske arbeidsbelastninger der spørringer innebærer skanning av store mengder data for å utføre aggregasjoner, filtrering og andre datamanipuleringer.
Diskhurtigbuffer
Enkelte datasett er for store til å få plass i en minnehurtigbuffer. Hvis du vil opprettholde rask spørringsytelse for disse datasettene, bruker Warehouse diskplass som en komplementær utvidelse til hurtigbufferen i minnet. All informasjon som lastes inn i minnehurtigbufferen, serialiseres også til SSD-hurtigbufferen.
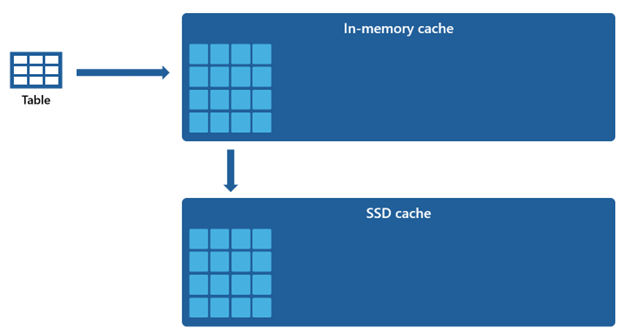
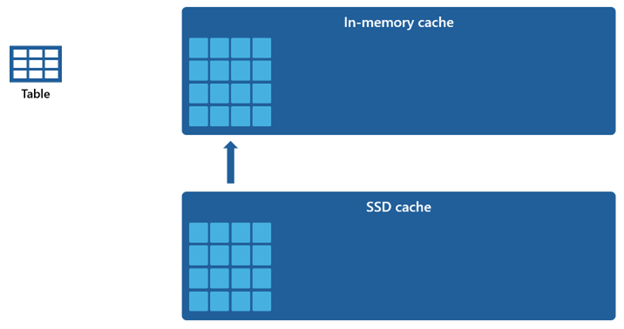
Gitt at hurtigbufferen i minnet har en mindre kapasitet sammenlignet med SSD-hurtigbufferen, forblir data som fjernes fra minnehurtigbufferen, innenfor SSD-bufferen i en lengre periode. Når etterfølgende spørring ber om disse dataene, hentes den fra SSD-hurtigbufferen til minnehurtigbufferen betydelig raskere enn hvis den hentes fra ekstern lagring, noe som til slutt gir deg mer konsekvent spørringsytelse.
Hurtigbufferbehandling
Hurtigbufring forblir konsekvent aktiv og fungerer sømløst i bakgrunnen, og krever ingen intervensjon fra din side. Deaktivering av hurtigbufring er ikke nødvendig, da dette uunngåelig vil føre til en merkbar forverring i spørringsytelsen.
Hurtigbufringsmekanismen er orkestrert og opprettholdt av Selve Microsoft Fabric, og den gir ikke brukerne muligheten til å fjerne hurtigbufferen manuelt.
Fullstendig transaksjonskonsekvens for hurtigbuffer sikrer at eventuelle endringer av dataene i lagring, for eksempel gjennom DML-operasjoner (Data Manipulation Language), etter at de først er lastet inn i minnehurtigbufferen, vil resultere i konsekvente data.
Når hurtigbufferen når kapasitetsterskelen og nye data leses for første gang, fjernes objekter som har vært ubrukt i den lengste varigheten, fra hurtigbufferen. Denne prosessen er vedtatt for å skape plass til tilstrømningen av nye data og opprettholde en optimal strategi for hurtigbufferutnyttelse.