Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
gjelder for:✅ Warehouse i Microsoft Fabric
Denne artikkelen beskriver metodene for overføring av datalagring i Azure Synapse Analytics dedikerte SQL-utvalg til Microsoft Fabric Warehouse.
Tips
Hvis du vil ha mer informasjon om strategi og planlegging av overføringen, kan du se overføringsplanlegging: Azure Synapse Analytics dedikerte SQL-utvalg til Fabric Data Warehouse.
En automatisert opplevelse for overføring fra Azure Synapse Analytics dedikerte SQL-utvalg er tilgjengelig ved hjelp av Fabric Migration Assistant for Data Warehouse. Resten av denne artikkelen inneholder flere trinn for manuell overføring.
Denne tabellen oppsummerer informasjon om dataskjema (DDL), databasekode (DML) og dataoverføringsmetoder. Vi utvider ytterligere på hvert scenario senere i denne artikkelen, koblet i Tilvalg-kolonnen .
| Alternativnummer | Alternativ | Hva det gjør | Kompetanse/preferanse | Scenario |
|---|---|---|---|---|
| 1 | Data fabrikk | Skjemakonvertering (DDL) Datauttrekking Datainntak |
ADF/pipeline | Forenklet alt i ett skjema (DDL) og dataoverføring. Anbefales for dimensjonstabeller. |
| 2 | Data Factory med partisjon | Skjemakonvertering (DDL) Datauttrekking Datainntak |
ADF/pipeline | Bruk av partisjoneringsalternativer for å øke lese-/skrive-parallellismen som gir ti ganger gjennomstrømming kontra alternativ 1, anbefalt for faktatabeller. |
| 3 | Data Factory med akselerert kode | Skjemakonvertering (DDL) | ADF/pipeline | Konverter og overfør skjemaet (DDL) først, og bruk deretter CETAS til å trekke ut og KOPIERE/Data Factory til å innta data for optimal generell inntaksytelse. |
| 4 | Akselerert kode for lagrede prosedyrer | Skjemakonvertering (DDL) Datauttrekking Kodevurdering |
T-SQL | SQL-bruker som bruker IDE med mer detaljert kontroll over hvilke oppgaver de vil arbeide med. Bruk COPY/Data Factory til å innta data. |
| 5 | SQL Database Project-utvidelse for Visual Studio Code | Skjemakonvertering (DDL) Datauttrekking Kodevurdering |
SQL-prosjekt | SQL Database Project for distribusjon med integrering av alternativ 4. Bruk COPY eller Data Factory til å innta data. |
| 6 | OPPRETT EKSTERN TABELL SOM VELG (CETAS) | Datauttrekking | T-SQL | Kostnadseffektive data og data med høy ytelse trekkes ut i Azure Data Lake Storage (ADLS) Gen2. Bruk COPY/Data Factory til å innta data. |
| 7 | Overføre ved hjelp av dbt | Skjemakonvertering (DDL) databasekodekonvertering (DML) |
dbt | Eksisterende dbt-brukere kan bruke dbt Fabric-adapteren til å konvertere DDL og DML. Deretter må du overføre data ved hjelp av andre alternativer i denne tabellen. |
Velg en arbeidsbelastning for den første overføringen
Når du bestemmer deg for hvor du skal begynne på det dedikerte SQL-utvalget synapse til Fabric Warehouse-overføringsprosjektet, velger du et arbeidsbelastningsområde der du kan:
- Bevise levedyktigheten ved å overføre til Fabric Warehouse ved raskt å levere fordelene med det nye miljøet. Start små og enkle, klargjør for flere små overføringer.
- Gi de interne tekniske ansatte tid til å få relevant erfaring med prosessene og verktøyene de bruker når de overfører til andre områder.
- Opprett en mal for videre overføringer som er spesifikke for synapsemiljøet for kilden, og verktøyene og prosessene som er på plass for å hjelpe.
Tips
Opprett en beholdning av objekter som må overføres, og dokumenter overføringsprosessen fra start til slutt, slik at den kan gjentas for andre dedikerte SQL-utvalg eller arbeidsbelastninger.
Volumet av overførte data i en innledende overføring bør være stort nok til å demonstrere egenskapene og fordelene ved Fabric Warehouse-miljøet, men ikke for stort til raskt å demonstrere verdi. En størrelse i området 1-10 terabyte er typisk.
Overføring med Fabric Data Factory
I denne delen diskuterer vi alternativene ved hjelp av Data Factory for lavkode-/no-code-personen som er kjent med Azure Data Factory og Synapse Pipeline. Dette alternativet dra og slipp brukergrensesnittet gir et enkelt trinn for å konvertere DDL og overføre dataene.
Fabric Data Factory kan utføre følgende oppgaver:
- Konverter skjemaet (DDL) til Fabric Warehouse-syntaks.
- Opprett skjemaet (DDL) på Fabric Warehouse.
- Overføre dataene til Fabric Warehouse.
Alternativ 1. Skjema-/dataoverføring – Kopier veiviser og Foreach-kopieringsaktivitet
Denne metoden bruker Data Factory Copy assistant til å koble til det dedikerte SQL-utvalget for kilde, konvertere den dedikerte SQL Pool DDL-syntaksen til Fabric og kopiere data til Fabric Warehouse. Du kan velge én eller flere måltabeller (for TPC-DS datasett er det 22 tabeller). Den genererer ForEach for å gå gjennom listen over tabeller som er valgt i brukergrensesnittet, og gyte 22 parallelle kopier aktivitetstråder.
- 22 SELECT-spørringer (én for hver valgte tabell) ble generert og utført i det dedikerte SQL-utvalget.
- Kontroller at du har riktig DWU- og ressursklasse slik at spørringene som genereres, kan utføres. I dette tilfellet trenger du minimum DWU1000 med
staticrc10for å tillate maksimalt 32 spørringer å håndtere 22 spørringer som er sendt inn. - Data Factory direkte kopiering av data fra det dedikerte SQL-utvalget til Fabric Warehouse krever oppsamling. Inntaksprosessen besto av to faser.
- Den første fasen består av å trekke ut dataene fra det dedikerte SQL-utvalget i ADLS og kalles oppsamling.
- Den andre fasen består av inntak av data fra oppsamling i Fabric Warehouse. Mesteparten av tidsberegningen for datainntak er i oppsamlingsfasen. Oppsummert har iscenesettelse en stor innvirkning på inntaksytelsen.
Anbefalt bruk
Hvis du bruker kopieringsveiviseren til å generere en ForEach, kan du konvertere DDL og innta de valgte tabellene fra det dedikerte SQL-utvalget til Fabric Warehouse i ett trinn.
Det er imidlertid ikke optimalt med den generelle gjennomstrømmingen. Kravet om å bruke oppsamling, behovet for å parallellisere lese og skrive for trinnet «Kilde til fase» er de viktigste faktorene for ytelsesventetid. Det anbefales å bare bruke dette alternativet for dimensjonstabeller.
Alternativ 2. DDL/dataoverføring – datasamlebånd ved hjelp av partisjonsalternativ
For å håndtere forbedring av gjennomstrømmingen for å laste inn større faktatabeller ved hjelp av Fabric-pipeline, anbefales det å bruke Kopier aktivitet for hver faktatabell med partisjonsalternativ. Dette gir best ytelse med Kopier aktivitet.
Du har muligheten til å bruke den fysiske partisjoneringen av kildetabellen, hvis tilgjengelig. Hvis tabellen ikke har fysisk partisjonering, må du angi partisjonskolonnen og angi min/maks-verdier for å bruke dynamisk partisjonering. I skjermbildet nedenfor angir kildealternativene for pipeline et dynamisk område med partisjoner basert på ws_sold_date_sk kolonnen.
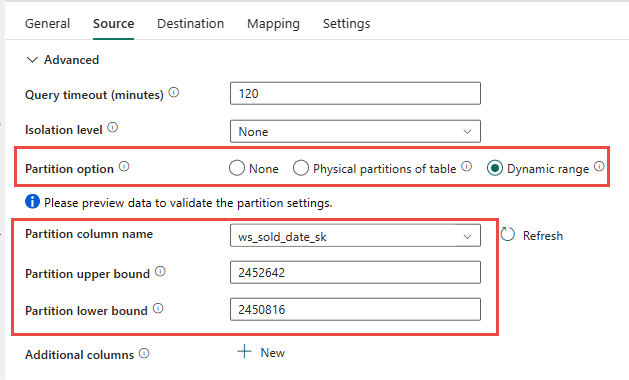
Selv om bruk av partisjon kan øke gjennomstrømmingen med oppsamlingsfasen, er det hensyn til å foreta de riktige justeringene:
- Avhengig av partisjonsområdet, kan det potensielt bruke alle samtidighetssporene, da det kan generere over 128 spørringer i det dedikerte SQL-utvalget.
- Du må skalere til minimum DWU6000 slik at alle spørringer kan utføres.
- For TPC-DS-tabellen
web_salesble for eksempel 163 spørringer sendt til det dedikerte SQL-utvalget. Ved DWU6000 ble 128 spørringer utført mens 35 spørringer ble satt i kø. - Dynamisk partisjon velger automatisk områdepartisjonen. I dette tilfellet er det et 11-dagers område for hver SELECT-spørring som sendes til det dedikerte SQL-utvalget. Eksempel:
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
Anbefalt bruk
For faktatabeller anbefalte vi å bruke Data Factory med partisjoneringsalternativ for å øke gjennomstrømmingen.
De økte parallelliserte lesingene krever imidlertid dedikert SQL-utvalg for å skalere til høyere DWU for å tillate at uttrekkingsspørringene utføres. Hvis du bruker partisjonering, forbedres satsen ti ganger over et ikke-partisjonsalternativ. Du kan øke DWU-en for å få ekstra gjennomstrømming via databehandlingsressurser, men det dedikerte SQL-utvalget har maksimalt 128 aktive spørringer.
Hvis du vil ha mer informasjon om Synapse DWU til Fabric-tilordning, kan du se Blogg: Tilordne Azure Synapse dedikerte SQL-utvalg til datalagerdatabehandling for Fabric.
Alternativ 3. DDL-overføring – Kopier kopieringsaktivitet for veiviseren
De to foregående alternativene er gode alternativer for dataoverføring for mindre databaser. Men hvis du trenger høyere gjennomstrømming, anbefaler vi et alternativ:
- Trekk ut dataene fra det dedikerte SQL-utvalget til ADLS, og reduserer derfor ytelsesoversikten for fasen.
- Bruk enten Data Factory eller COPY-kommandoen til å innta dataene i Fabric Warehouse.
Anbefalt bruk
Du kan fortsette å bruke Data Factory til å konvertere skjemaet (DDL). Ved hjelp av kopieringsveiviseren kan du velge den bestemte tabellen eller Alle tabeller. Utforming overfører dette skjemaet og dataene i ett trinn, og trekker ut skjemaet uten rader, ved hjelp av den falske betingelsen, TOP 0 i spørringssetningen.
Følgende kodeeksempel dekker skjemaoverføring (DDL) med Data Factory.
Kodeeksempel: Skjemaoverføring (DDL) med Data Factory
Du kan bruke Fabric Pipelines til enkelt å overføre DDL (skjemaer) for tabellobjekter fra en hvilken som helst kilde, Azure SQL Database eller dedikert SQL-utvalg. Denne pipelinen overføres over skjemaet (DDL) for de dedikerte kildetabellene for SQL-utvalg til Fabric Warehouse.
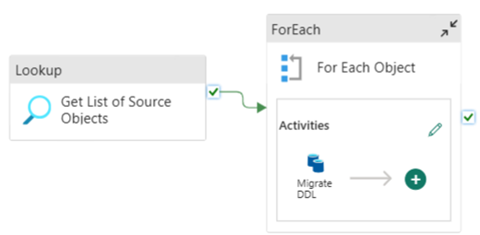
Utforming av datasamlebånd: parametere
Denne pipelinen godtar en parameter SchemaName, som lar deg spesifisere hvilke skjemaer som skal overføres over. Skjemaet dbo er standard.
Angi en kommadelt liste over tabellskjema som angir hvilke skjemaer som skal overføres, i standardverdifeltet: 'dbo','tpch' for å angi to skjemaer og dbotpch.
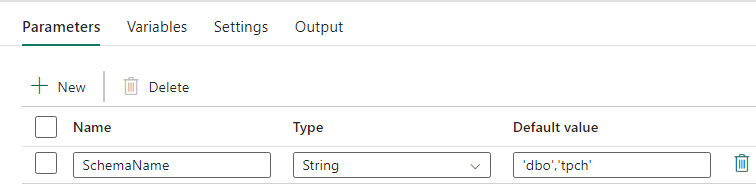
Utforming av datasamlebånd: Oppslagsaktivitet
Opprett en oppslagsaktivitet, og angi tilkoblingen til å peke til kildedatabasen.
I Innstillinger-fanen:
Angi datalagertype til Ekstern.
Tilkoblingen er azure Synapse-dedikert SQL-utvalg. Tilkoblingstypen er Azure Synapse Analytics.
Bruksspørring er satt til Spørring.
Spørringsfeltet må bygges ved hjelp av et dynamisk uttrykk, slik at parameteren SchemaName kan brukes i en spørring som returnerer en liste over målkildetabeller. Velg Spørring , og velg deretter Legg til dynamisk innhold.
Dette uttrykket i oppslagsaktiviteten genererer en SQL-setning for å spørre systemvisningene for å hente en liste over skjemaer og tabeller. Refererer til SchemaName-parameteren for å tillate filtrering på SQL-skjemaer. Utdataene for dette er en matrise med SQL-skjema og tabeller som skal brukes som inndata i ForEach-aktiviteten.
Bruk følgende kode til å returnere en liste over alle brukertabeller med skjemanavnet.
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
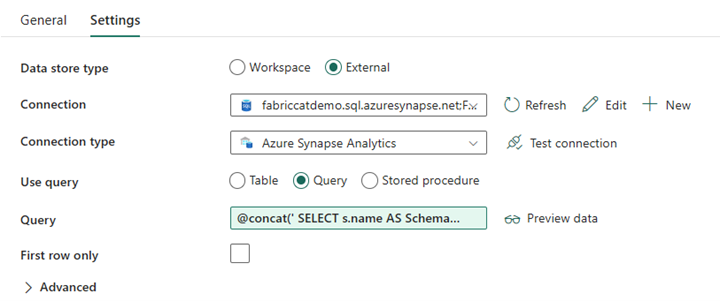
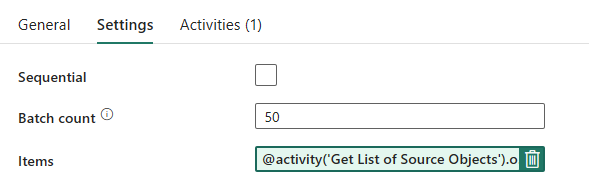
Rørledningsutforming: Forgrunnsløkke
Konfigurer følgende alternativer i Innstillinger-fanen for Foreach-løkken:
- Deaktiver sekvensiell for å tillate at flere gjentakelser kjøres samtidig.
- Angi partiantall til
50, og begrens maksimalt antall samtidige gjentakelser. - Elementer-feltet må bruke dynamisk innhold til å referere til utdataene for oppslagsaktiviteten. Bruk følgende kodesnutt:
@activity('Get List of Source Objects').output.value
Utforming av datasamlebånd: Kopier aktivitet i Foreach-løkken
Legg til en kopiaktivitet i Foreach-aktiviteten. Denne metoden bruker Dynamic Expression Language i pipeliner til å bygge et SELECT TOP 0 * FROM <TABLE> for å overføre bare skjemaet uten data til et Fabric Warehouse.
I Kilde-fanen:
- Angi datalagertype til Ekstern.
- Tilkoblingen er azure Synapse-dedikert SQL-utvalg. Tilkoblingstypen er Azure Synapse Analytics.
- Angi bruksspørring til spørring.
-
Lim inn i den dynamiske innholdsspørringen i Spørring-feltet, og bruk dette uttrykket som returnerer null rader, bare tabellskjemaet:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

På Mål-fanen:
- Angi datalagertype til arbeidsområde.
- Datalagertypen arbeidsområde er Data Warehouse, og datalageret er satt til Fabric Warehouse.
- Skjema- og tabellnavnet for måltabellen defineres ved hjelp av dynamisk innhold.
- Skjema refererer til gjeldende gjentakelsesfelt, SchemaName med kodesnutten:
@item().SchemaName - Tabellen refererer til TableName med snutten:
@item().TableName
- Skjema refererer til gjeldende gjentakelsesfelt, SchemaName med kodesnutten:

Rørledningsutforming: Vask
Pek på lageret for Sink, og referer til kildeskjemaet og tabellnavnet.
Når du har kjørt dette datasamlebåndet, ser du datalageret fylt ut med hver tabell i kilden, med riktig skjema.
Overføring ved hjelp av lagrede prosedyrer i synapse dedikert SQL-utvalg
Dette alternativet bruker lagrede prosedyrer til å utføre stoffoverføringen.
Du kan få kodeeksempler på microsoft/fabric-migration på GitHub.com. Denne koden deles som åpen kilde, så du kan gjerne bidra til å samarbeide og hjelpe fellesskapet.
Hvilke lagrede prosedyrer for overføring kan gjøre:
- Konverter skjemaet (DDL) til Fabric Warehouse-syntaks.
- Opprett skjemaet (DDL) på Fabric Warehouse.
- Trekk ut data fra synapse dedikert SQL-utvalg til ADLS.
- Flagg stoffsyntaks for T-SQL-koder som ikke støttes (lagrede prosedyrer, funksjoner, visninger).
Anbefalt bruk
Dette er et flott alternativ for de som:
- Er kjent med T-SQL.
- Vil bruke et integrert utviklingsmiljø, for eksempel SQL Server Management Studio (SSMS).
- Vil ha mer detaljert kontroll over hvilke oppgaver de vil arbeide med.
Du kan utføre den spesifikke lagrede prosedyren for skjemakonvertering, datauttrekking eller T-SQL-kodevurdering.
For dataoverføringen må du bruke ENTEN COPY INTO eller Data Factory til å innta dataene til Fabric Warehouse.
Overføre ved hjelp av SQL-databaseprosjekter
Microsoft Fabric Data Warehouse støttes i SQL Database Projects-utvidelsen som er tilgjengelig i Visual Studio Code.
Denne utvidelsen er tilgjengelig i Visual Studio Code. Denne funksjonen aktiverer funksjoner for kildekontroll, databasetesting og skjemavalidering.
Hvis du vil ha mer informasjon om kildekontroll for lagre i Microsoft Fabric, inkludert Git-integrering og distribusjonssamlebånd, kan du se Kildekontroll med Lager.
Anbefalt bruk
Dette er et flott alternativ for de som foretrekker å bruke SQL Database Project for distribusjonen. Dette alternativet integrerte i hovedsak de lagrede prosedyrene for stoffoverføring i SQL Database Project for å gi en sømløs overføringsopplevelse.
Et SQL Database Project kan:
- Konverter skjemaet (DDL) til Fabric Warehouse-syntaks.
- Opprett skjemaet (DDL) på Fabric Warehouse.
- Trekk ut data fra synapse dedikert SQL-utvalg til ADLS.
- Flagg ikke-støttet syntaks for T-SQL-koder (lagrede prosedyrer, funksjoner, visninger).
Når det gjelder dataoverføringen, bruker du enten COPY INTO eller Data Factory til å innta dataene til Fabric Warehouse.
Microsoft Fabric CAT-teamet har levert et sett med PowerShell-skript for å håndtere uttrekking, oppretting og distribusjon av skjema (DDL) og databasekode (DML) via et SQL Database-prosjekt. Hvis du vil ha en gjennomgang av hvordan du bruker SQL Database-prosjektet med våre nyttige PowerShell-skript, kan du se microsoft/fabric-migration på GitHub.com.
Hvis du vil ha mer informasjon om SQL Database Projects, kan du se Komme i gang med SQL Database Projects-utvidelsen og bygge og publisere et prosjekt.
Overføring av data med CETAS
KOMMANDOEN T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) gir den mest kostnadseffektive og optimale metoden for å trekke ut data fra Synapse-dedikerte SQL-utvalg til Azure Data Lake Storage (ADLS) Gen2.
Hva CETAS kan gjøre:
- Pakk ut data i ADLS.
- Dette alternativet krever at brukere oppretter skjemaet (DDL) på Fabric Warehouse før de inntar dataene. Vurder alternativene i denne artikkelen for å overføre skjema (DDL).
Fordelene med dette alternativet er:
- Bare én enkelt spørring per tabell sendes inn mot det dedikerte SQL-utvalget for kildesynapse. Dette vil ikke bruke opp alle samtidighetssporene, og vil derfor ikke blokkere samtidige kundeproduksjons-ETL/spørringer.
- Skalering til DWU6000 er ikke nødvendig, da bare ett enkelt samtidighetsspor brukes for hver tabell, slik at kunder kan bruke lavere DWUer.
- Ekstraktet kjøres parallelt på tvers av alle databehandlingsnodene, og dette er nøkkelen til forbedring av ytelsen.
Anbefalt bruk
Bruk CETAS til å trekke ut dataene til ADLS som parkettfiler. Parquet-filer gir fordelen av effektiv datalagring med kolonnekomprimering som vil kreve mindre båndbredde for å flytte over nettverket. I tillegg, siden Fabric lagret dataene som Delta-parkettformat, vil datainntaket være 2,5x raskere sammenlignet med tekstfilformatet, siden det ikke er noen konvertering til Delta-formatet overhead under inntak.
Slik øker du CETAS-gjennomstrømmingen:
- Legg til parallelle CETAS-operasjoner, noe som øker bruken av samtidighetsspor, men tillater mer gjennomstrømming.
- Skaler DWU på synapse dedikert SQL-utvalg.
Overføring via dbt
I denne delen diskuterer vi dbt-alternativet for de kundene som allerede bruker dbt i det gjeldende dedikerte SQL-utvalgsmiljøet for Synapse.
Hva dbt kan gjøre:
- Konverter skjemaet (DDL) til Fabric Warehouse-syntaks.
- Opprett skjemaet (DDL) på Fabric Warehouse.
- Konverter databasekode (DML) til stoffsyntaks.
DBT-rammeverket genererer DDL og DML (SQL-skript) på farten med hver kjøring. Med modellfiler uttrykt i SELECT-setninger, kan DDL/DML oversettes umiddelbart til en hvilken som helst målplattform ved å endre profilen (tilkoblingsstreng) og adaptertypen.
Anbefalt bruk
DBT-rammeverket er kode-første tilnærming. Dataene må overføres ved hjelp av alternativer som er oppført i dette dokumentet, for eksempel CETAS eller COPY/Data Factory.
DBT-adapteren for Microsoft Fabric Data Warehouse gjør at eksisterende dbt-prosjekter som var rettet mot forskjellige plattformer som Synapse-dedikerte SQL-bassenger, Snowflake, Databricks, Google Big Query eller Amazon Redshift, kan overføres til et Fabric Warehouse med en enkel konfigurasjonsendring.
Hvis du vil komme i gang med et dbt-prosjekt rettet mot Fabric Warehouse, kan du se Opplæring: Konfigurere dbt for Fabric Data Warehouse. Dette dokumentet viser også et alternativ for å flytte mellom ulike lagre/plattformer.
Datainntak i Fabric Warehouse
For inntak i Fabric Warehouse, bruk COPY INTO eller Fabric Data Factory, avhengig av hva du foretrekker. Begge metodene er de anbefalte og beste alternativene, da de har tilsvarende ytelsesgjennomstrømming, gitt forutsetningen om at filene allerede er pakket ut til Azure Data Lake Storage (ADLS) Gen2.
Flere faktorer å merke seg, slik at du kan utforme prosessen for maksimal ytelse:
- Med Fabric er det ingen ressursstrid når du laster inn flere tabeller fra ADLS til Fabric Warehouse samtidig. Derfor er det ingen ytelsesreduksjon når du laster inn parallelle tråder. Maksimal gjennomstrømming av inntak begrenses bare av databehandlingskraften til stoffkapasiteten.
- Administrasjon av stoffarbeidsbelastning gir fordeling av ressurser som er tildelt for innlasting og spørring. Det er ingen ressurskonflikt mens spørringer og datainnlasting utføres samtidig.
Relatert innhold
- Infrastrukturoverføringsassistent for datalager
- Opprette et lager i Microsoft Fabric
- Retningslinjer for fabric data warehouse-ytelse
- Sikkerhet for datalagring i Microsoft Fabric
- Blogg: Tilordne Azure Synapse dedikerte SQL-utvalg til datalagerdatabehandling for Fabric
- Oversikt over Microsoft Fabric-overføring