Opprett et lakehouse for Direct Lake
Denne artikkelen beskriver hvordan du oppretter et lakehouse, oppretter et Delta-bord i lakehouse, og deretter oppretter du en grunnleggende semantisk modell for lakehouse i et Microsoft Fabric-arbeidsområde.
Før du begynner å opprette et lakehouse for Direct Lake, må du lese Oversikt over Direct Lake.
Opprett et innsjøhus
Velg Nye>Flere alternativeri Microsoft Fabric-arbeidsområdet, og velg deretter flisen LakehouseiData Engineering.

Skriv inn et navn i dialogboksen New Lakehouse, og velg deretter Opprett. Navnet kan bare inneholde alfanumeriske tegn og understrekingstegn.

Kontroller at det nye lakehouse er opprettet og åpnes.

Opprette et Delta-bord i lakehouse
Når du har opprettet et nytt lakehouse, må du deretter opprette minst én Delta-tabell, slik at Direct Lake kan få tilgang til noen data. Direct Lake kan lese parkettformaterte filer, men for best ytelse er det best å komprimere dataene ved hjelp av VORDER-komprimeringsmetoden. VORDER komprimerer dataene ved hjelp av Power BI-motorens opprinnelige komprimeringsalgoritme. På denne måten kan motoren laste inn dataene i minnet så raskt som mulig.
Det finnes flere alternativer for å laste inn data i et lakehouse, inkludert datasamlebånd og skript. Følgende trinn bruker PySpark til å legge til en Delta-tabell i et lakehouse basert på en Azure Open Dataset:
Velg Åpne notatblokki det nyopprettede lakehouse, og velg deretter Ny notatblokk.

Kopier og lim inn følgende kodesnutt i den første kodecellen for å gi SPARK tilgang til den åpne modellen, og trykk deretter på SKIFT + ENTER for å kjøre koden.
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)Kontroller at koden sender ut en ekstern BLOB-bane.
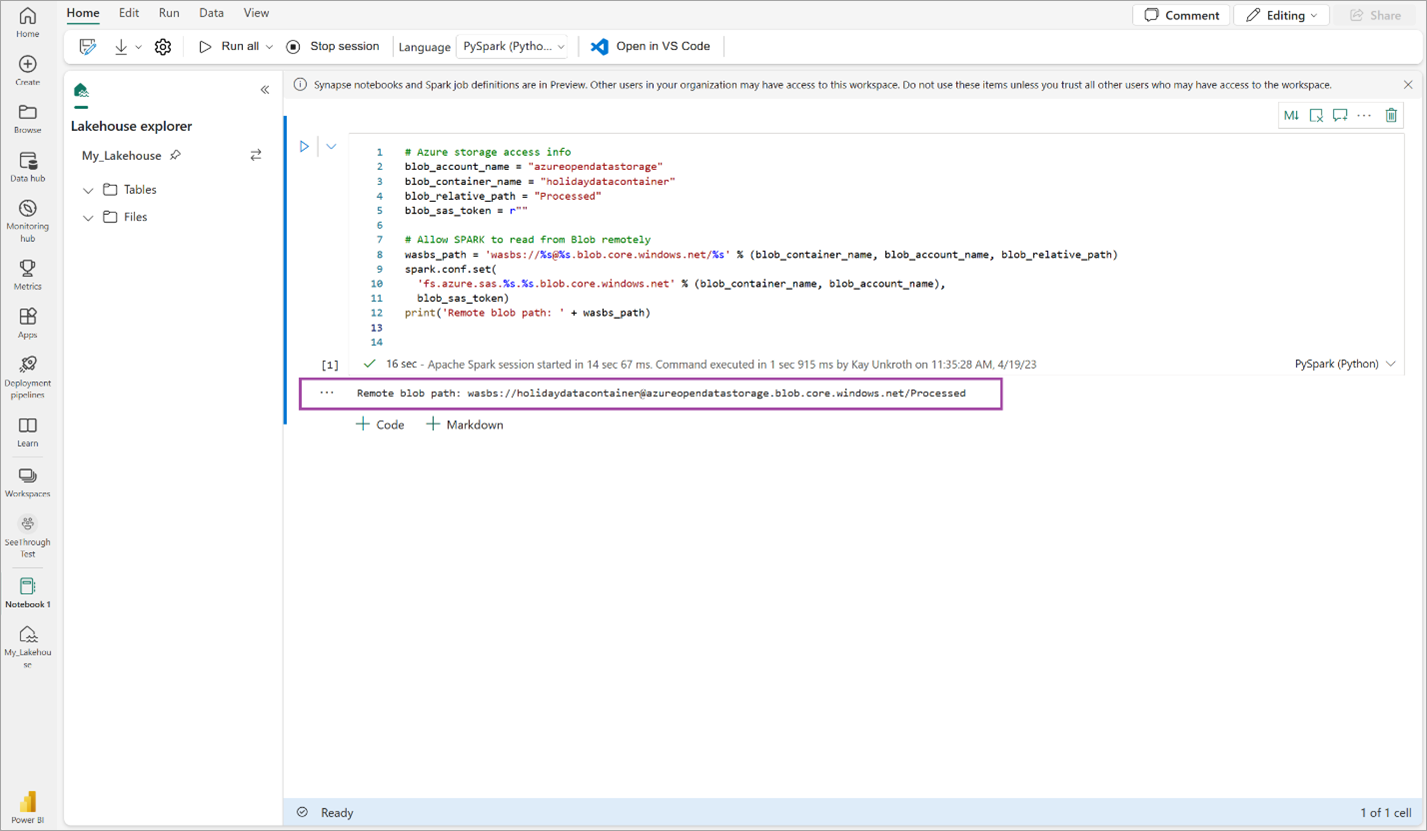
Kopier og lim inn følgende kode i neste celle, og trykk deretter på SKIFT + ENTER.
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())Kontroller at koden sender DataFrame-skjemaet.

Kopier og lim inn følgende linjer i neste celle, og trykk deretter SKIFT + ENTER. Den første instruksjonen aktiverer VORDER-komprimeringsmetoden, og den neste instruksjonen lagrer DataFrame som en Delta-tabell i lakehouse.
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")Kontroller at alle SPARK-jobber er fullført. Utvid SPARK-jobblisten for å vise flere detaljer.

Hvis du vil bekrefte at en tabell er opprettet, velger du ellipsen (...) øverst til venstre ved siden av Tabeller, og deretter velger du Oppdater, og deretter utvider du tabeller noden.

Bruk enten samme metode som ovenfor eller andre støttede metoder, og legg til flere Delta-tabeller for dataene du vil analysere.
Opprett en grunnleggende Direct Lake-modell for lakehouse
Velg Ny semantisk modelli lakehouse, og velg deretter tabeller som skal inkluderes i dialogboksen.
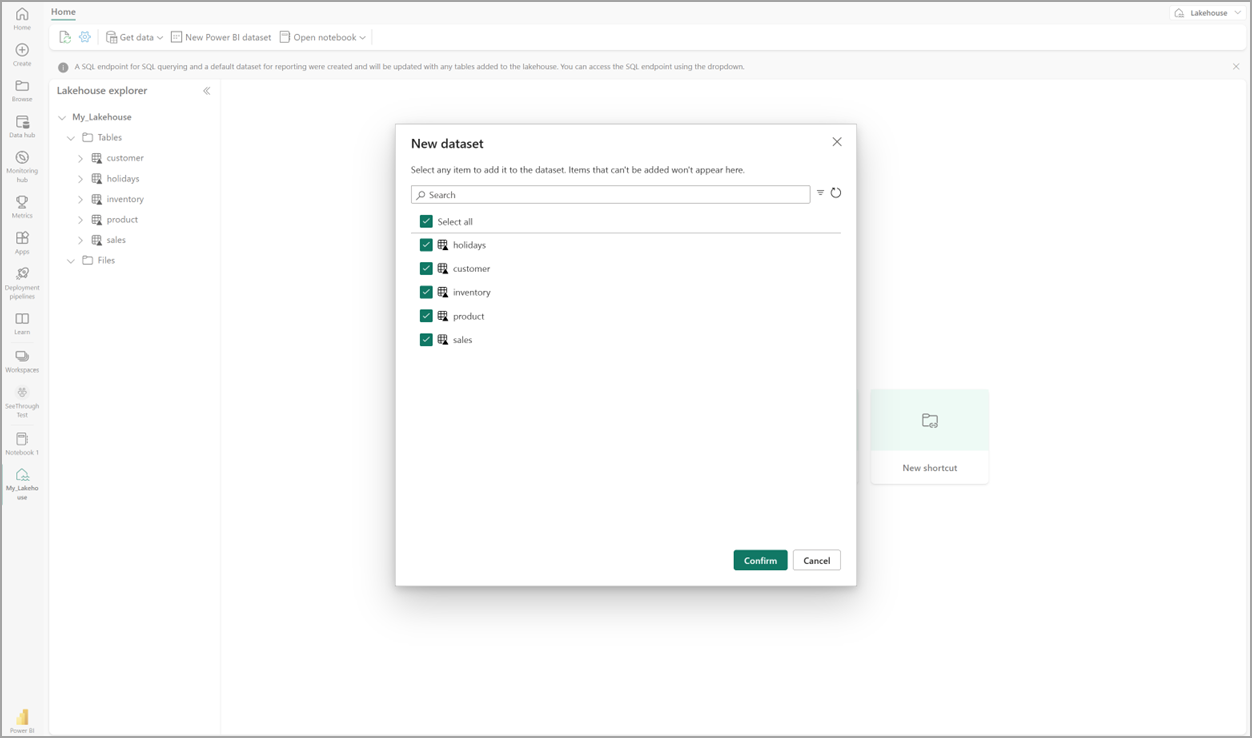
Velg Bekreft for å generere Direct Lake-modellen. Modellen lagres automatisk i arbeidsområdet basert på navnet på lakehouse, og åpner deretter modellen.

Velg Åpne datamodell for å åpne webmodelleringsopplevelsen der du kan legge til tabellrelasjoner og DAX-mål.

Når du er ferdig med å legge til relasjoner og DAX-mål, kan du deretter opprette rapporter, bygge en sammensatt modell og spørre modellen gjennom XMLA-endepunkter på omtrent samme måte som alle andre modeller.