Integrere OneLake med Azure HDInsight
Azure HDInsight er en administrert skybasert tjeneste for analyse av store data som hjelper organisasjoner med å behandle data med store mengder. Denne opplæringen viser hvordan du kobler til OneLake med en Jupyter-notatblokk fra en Azure HDInsight-klynge.
Bruke Azure HDInsight
Slik kobler du til OneLake med en Jupyter-notatblokk fra en HDInsight-klynge:
Opprett en HDInsight (HDI) Apache Spark-klynge. Følg disse instruksjonene: Konfigurere klynger i HDInsight.
Når du oppgir klyngeinformasjon, må du huske brukernavnet og passordet for klyngen, siden du trenger dem for å få tilgang til klyngen senere.
Opprett en brukertilordnet administrert identitet (UAMI): Opprett for Azure HDInsight – UAMI, og velg den som identitet på lagringsskjermen.
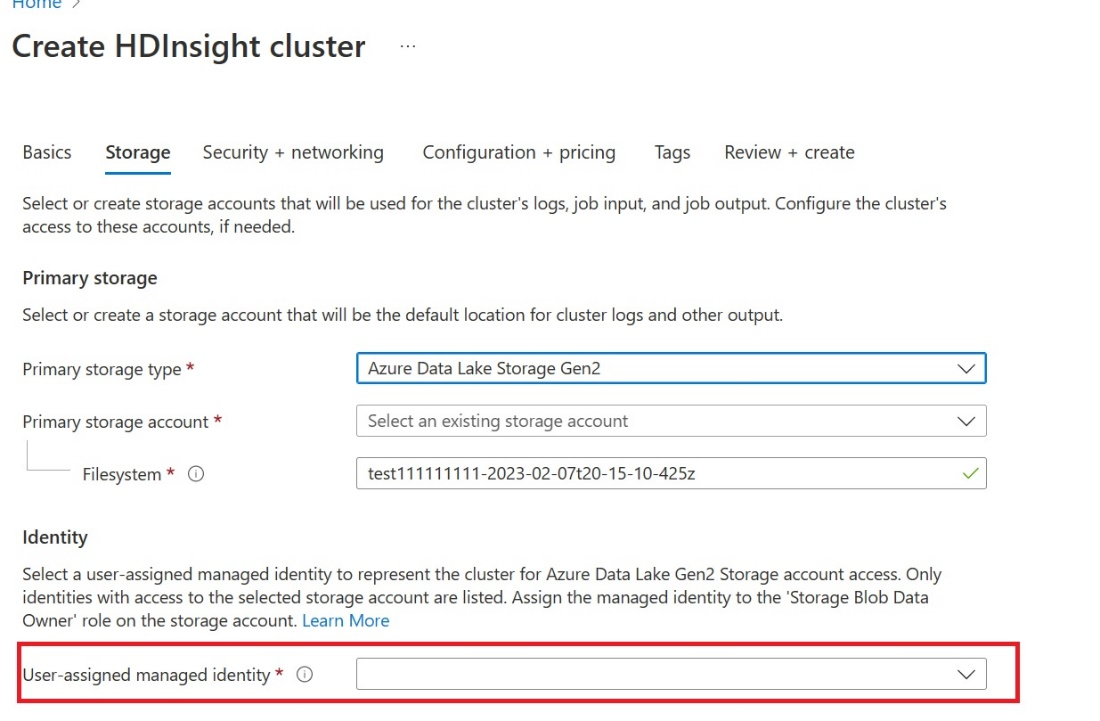
Gi denne UAMI-tilgangen til Fabric-arbeidsområdet som inneholder elementene dine. Hvis du vil ha hjelp til å bestemme hvilken rolle som er best, kan du se Arbeidsområderoller.
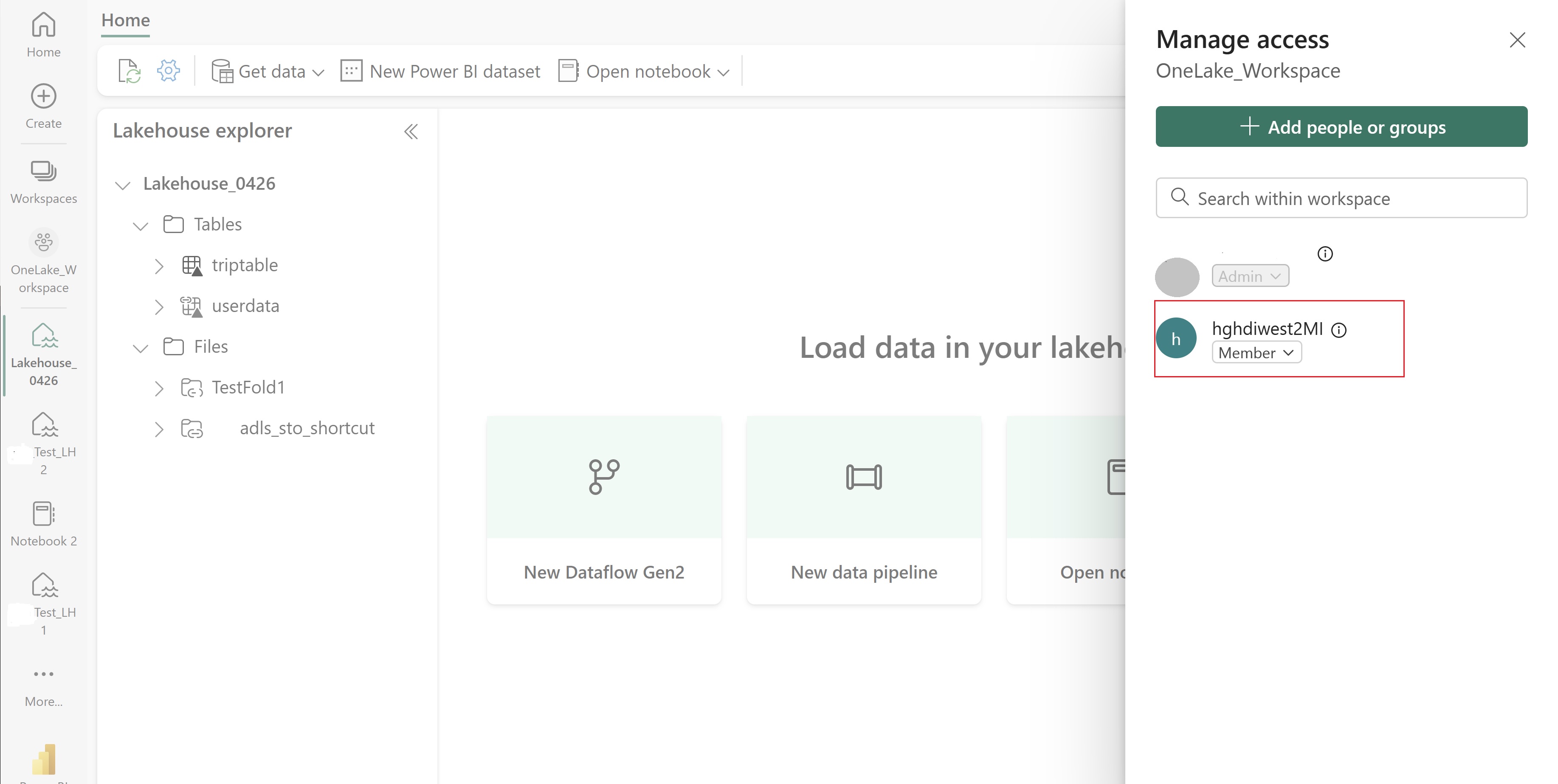
Gå til lakehouse og finn navnet på arbeidsområdet og lakehouse. Du finner dem i nettadressen til lakehouse eller Egenskaper-ruten for en fil.
Se etter klyngen i Azure-portalen, og velg notatblokken.
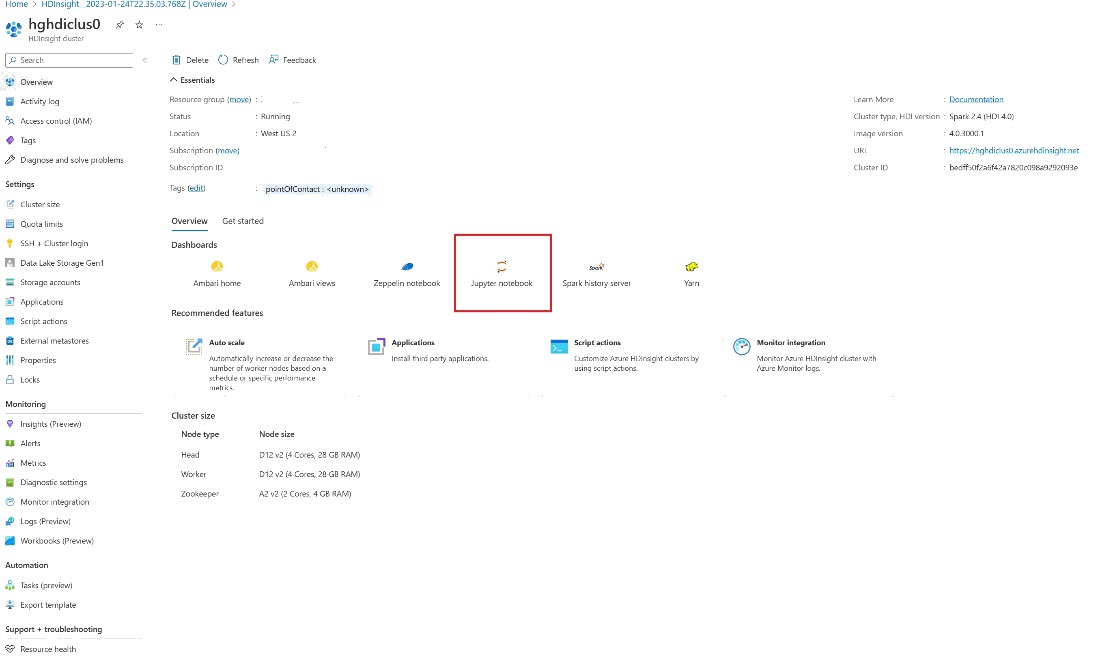
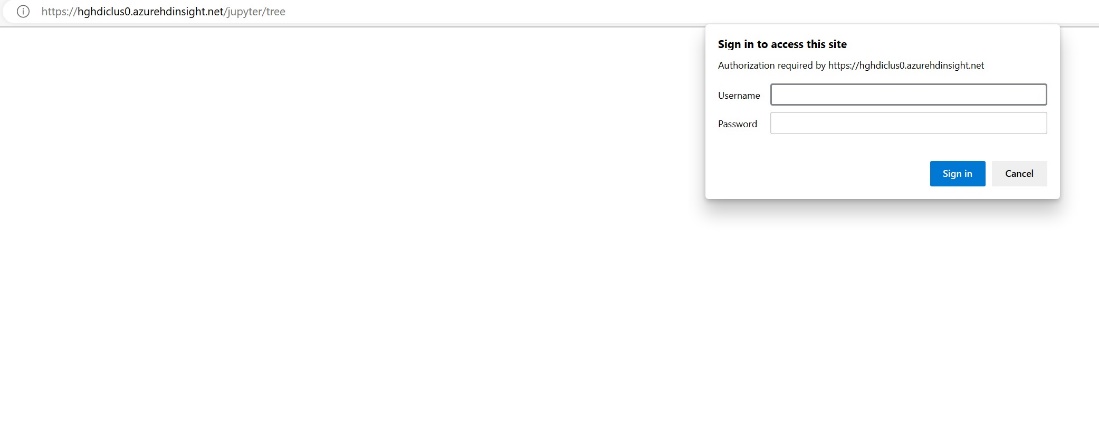
Angi legitimasjonsinformasjonen du oppgav under oppretting av klyngen.
Opprett en ny Apache Spark-notatblokk.
Kopier arbeidsområde- og lakehouse-navnene til notatblokken, og bygg OneLake-nettadressen for lakehouse. Nå kan du lese en fil fra denne filbanen.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Prøv å skrive noen data inn i lakehouse.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Test at dataene ble skrevet ved å sjekke lakehouse eller ved å lese den nylig lastede filen.




Nå kan du lese og skrive data i OneLake ved hjelp av Jupyter-notatblokken i en HDI Spark-klynge.
Relatert innhold
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for