Obs!
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Du kan bruke Python, et programmeringsspråk som brukes mye av statistikere, dataforskere og dataanalytikere, i Power BI Desktop-Power Query-redigering. Denne integreringen av Python i Power Query-redigering lar deg utføre datarensing ved hjelp av Python, og utføre avansert dataforming og analyse i datasett, inkludert fullføring av manglende data, prognoser og klynger, bare for å nevne noen. Python er et kraftig språk, og kan brukes i Power Query-redigering til å klargjøre datamodellen og opprette rapporter.
Forutsetninger
Du må installere Python og pandaer før du begynner.
Installer Python – Hvis du vil bruke Python i Power BI Desktops Power Query-redigering, må du installere Python på den lokale maskinen. Du kan laste ned og installere Python gratis fra mange steder, inkludert den offisielle Python-nedlastingssiden og Anaconda.
Installer pandaer – Hvis du vil bruke Python med Power Query-redigering, må du også installere pandaer. Pandaer brukes til å flytte data mellom Power BI og Python-miljøet.
Bruk Python med Power Query-redigering
Hvis du vil vise hvordan du bruker Python i Power Query-redigering, kan du ta dette eksemplet fra et datasett for aksjemarkedet, basert på en CSV-fil som du kan laste ned herfra og følge med. Trinnene for dette eksemplet er følgende fremgangsmåte:
Først laster du inn dataene i Power BI Desktop. I dette eksemplet laster du inn EuStockMarkets_NA.csv-filen og velger Hent datatekst>/CSV fra Hjem-båndet i Power BI Desktop.
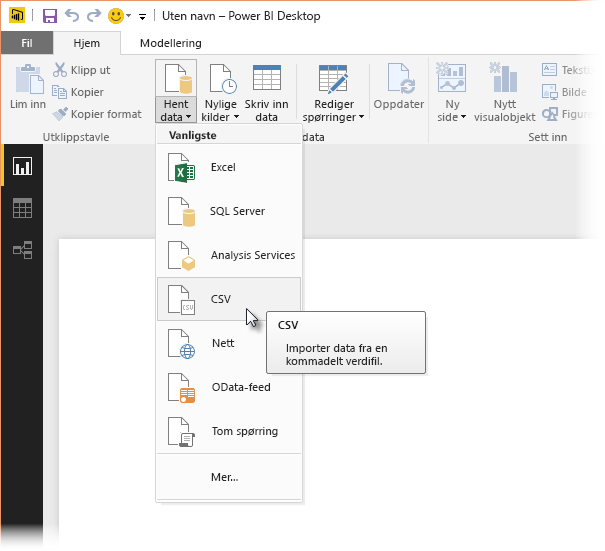
Velg filen, og velg Åpne, og CSV vises i dialogboksen CSV-fil .
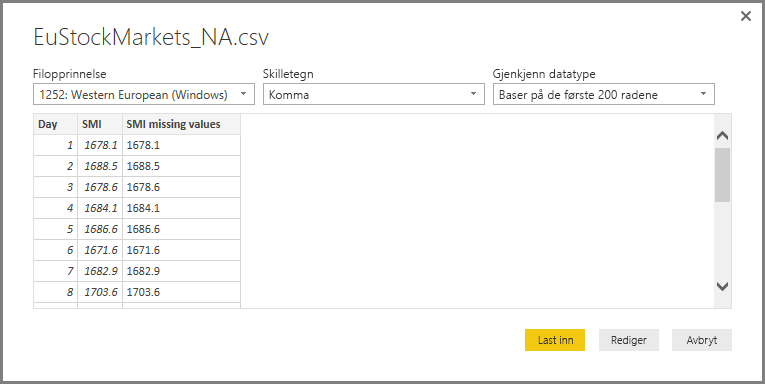
Når dataene er lastet inn, ser du dem i Felter-ruten i Power BI Desktop.
Åpne Power Query-redigering ved å velge Transformer data fra Hjem-faneni Power BI Desktop.
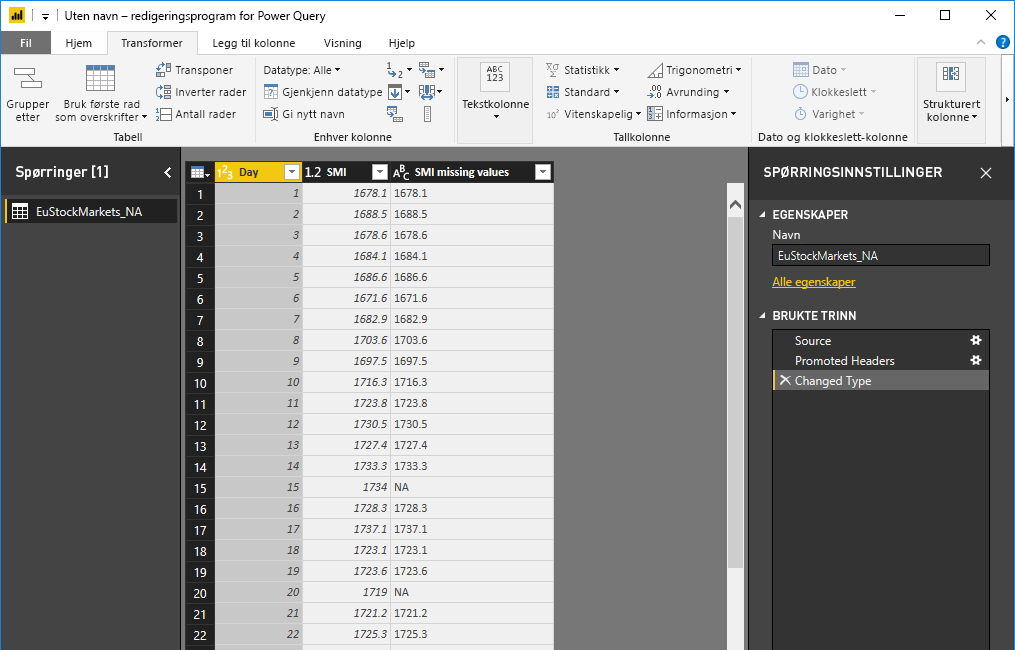
Velg Kjør Python-skript på Transformer-fanen, og redigeringsprogrammet Kjør Python-skript vises som vist i neste trinn. Rad 15 og 20 lider av manglende data, det samme gjør andre rader du ikke kan se i bildet nedenfor. Fremgangsmåten nedenfor viser hvordan Python fullfører disse radene for deg.
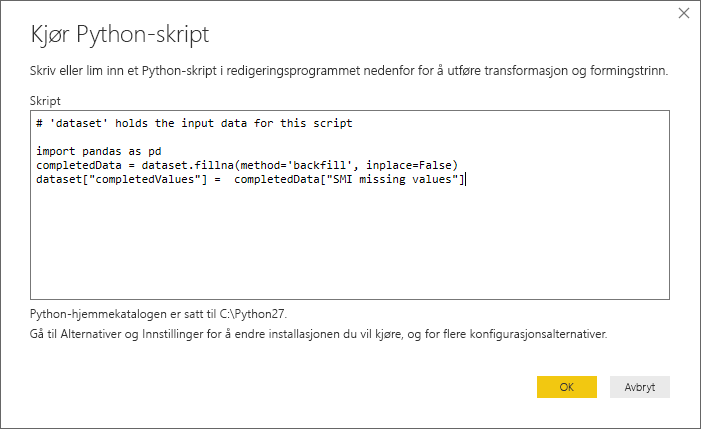
I dette eksemplet skriver du inn følgende skriptkode:
import pandas as pd completedData = dataset.fillna(method='backfill', inplace=False) dataset["completedValues"] = completedData["SMI missing values"]Notat
Du må ha pandabiblioteket installert i Python-miljøet for at den forrige skriptkoden skal fungere som den skal. Hvis du vil installere pandaer, kjører du følgende kommando i Python-installasjonen:
pip install pandasNår den settes inn i dialogboksen Kjør Python-skript , ser koden ut som følgende eksempel:
Når du har valgt OK, viser Power Query-redigering en advarsel om personvern.
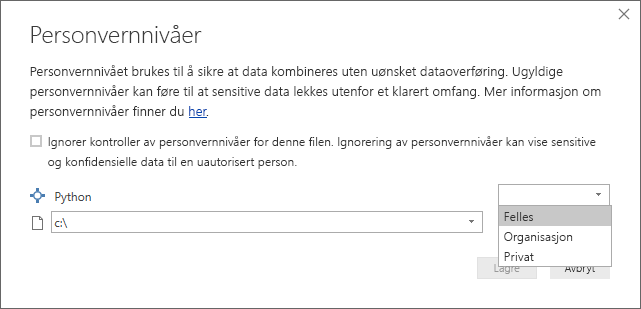
For at Python-skriptene skal fungere som de skal i Power Bi-tjeneste, må alle datakilder settes til offentlig. Hvis du vil ha mer informasjon om personverninnstillinger og deres implikasjoner, kan du se Personvernnivåer.
Legg merke til en ny kolonne i Felter-ruten kalt completedValues. Legg merke til at det er noen manglende dataelementer, for eksempel på rad 15 og 18. Ta en titt på hvordan Python håndterer det i neste del.
Med bare tre linjer python-skript fylte Power Query-redigering ut de manglende verdiene med en prediktiv modell.
Opprette visualobjekter fra Python-skriptdata
Nå kan vi opprette et visualobjekt for å se hvordan Python-skriptkoden ved hjelp av pandabiblioteket fullførte de manglende verdiene, som vist på følgende bilde:
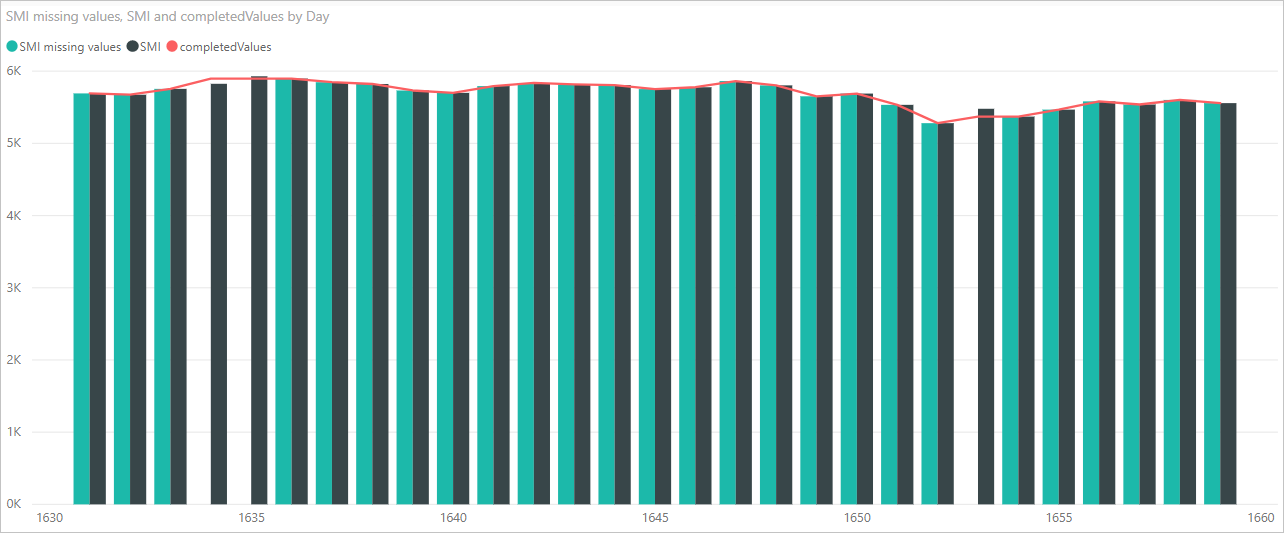
Når visualobjektet er fullført, og eventuelle andre visualobjekter du kanskje vil opprette ved hjelp av Power BI Desktop, kan du lagre Power BI Desktop-filen . Power BI Desktop-filer lagres med filtypen PBIX . Bruk deretter datamodellen, inkludert Python-skriptene som er en del av den, i Power Bi-tjeneste.
Notat
Vil du se en fullført PBIX-fil med disse trinnene fullført? Du har flaks. Du kan laste ned den fullførte Power BI Desktop-filen som brukes i disse eksemplene her.
Når du laster opp PBIX-filen til Power Bi-tjeneste, er det nødvendig med et par trinn til for å aktivere data som skal oppdateres i tjenesten, og for å gjøre det mulig for visualobjekter å oppdateres i tjenesten. Dataene trenger tilgang til Python for at visualobjekter skal oppdateres. De andre trinnene er følgende fremgangsmåte:
- Aktiver planlagt oppdatering for datasettet. Hvis du vil aktivere planlagt oppdatering for arbeidsboken som inneholder datasettet med Python-skript, kan du se Konfigurere planlagt oppdatering, som også inneholder informasjon om personlig gateway.
- Installer den personlige gatewayen. Du trenger en personlig gateway installert på maskinen der filen er plassert, og hvor Python er installert. Power Bi-tjeneste må få tilgang til arbeidsboken og gjengi eventuelle oppdaterte visualobjekter på nytt. Hvis du vil ha mer informasjon, kan du se installere og konfigurere Personlig gateway.
Hensyn og begrensninger
Det finnes noen begrensninger for spørringer som inkluderer Python-skript opprettet i Power Query-redigering:
Alle innstillinger for Python-datakilde må være satt til Offentlig, og alle andre trinn i en spørring som er opprettet i Power Query-redigering, må også være offentlige. Hvis du vil gå til datakildeinnstillinger, velger du Filalternativer > og innstillinger > for datakildeinnstillinger i Power BI Desktop.
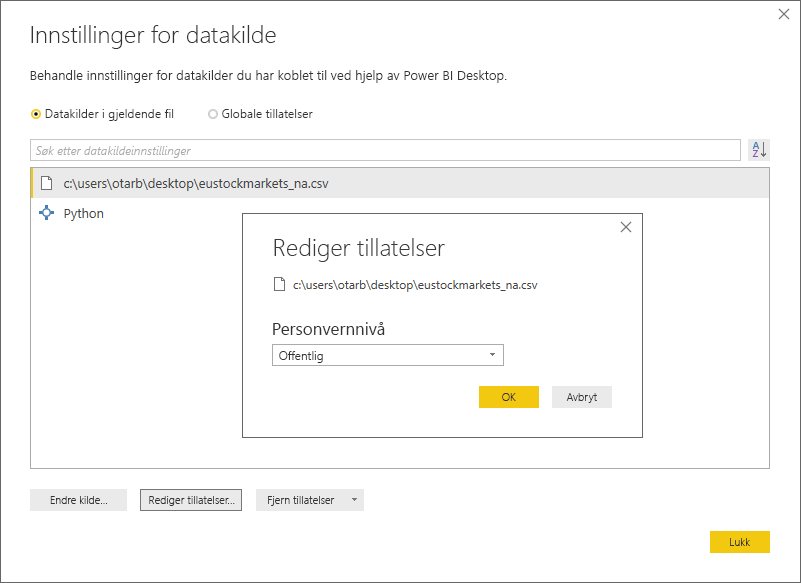
Velg datakildene i dialogboksen Datakilde Innstillinger, og velg deretter Rediger tillatelser... og kontroller at personvernnivået er satt til Offentlig.
Hvis du vil aktivere planlagt oppdatering av Python-visualobjekter eller datasett, må du aktivere planlagt oppdatering og ha en personlig gateway installert på datamaskinen som huser arbeidsboken og Python-installasjonen. Hvis du vil ha mer informasjon om begge deler, kan du se den forrige delen i denne artikkelen, som inneholder koblinger for å lære mer om hver av dem.
Nestede tabeller, som er tabelltabeller, støttes for øyeblikket ikke.
Det finnes mange ting du kan gjøre med Python og egendefinerte spørringer, så utforsk og form dataene akkurat slik du vil at det skal vises.