Beregnede tabellscenarioer og brukstilfeller
Det er fordeler med å bruke beregnede tabeller i en dataflyt. Denne artikkelen beskriver brukstilfeller for beregnede tabeller og beskriver hvordan de fungerer bak kulissene.
Hva er en beregnet tabell?
En tabell representerer datautdataene for en spørring som er opprettet i en dataflyt, etter at dataflyten er oppdatert. Den representerer data fra en kilde, og eventuelt transformasjonene som ble brukt på den. Noen ganger vil du kanskje opprette nye tabeller som er en funksjon i en tidligere inntatt tabell.
Selv om det er mulig å gjenta spørringene som opprettet en tabell og bruke nye transformasjoner på dem, har denne tilnærmingen ulemper: data inntas to ganger, og belastningen på datakilden dobles.
Beregnede tabeller løser begge problemene. Beregnede tabeller ligner på andre tabeller ved at de henter data fra en kilde, og du kan bruke ytterligere transformasjoner for å opprette dem. Dataene kommer imidlertid fra lagringsdataflyten som brukes, og ikke den opprinnelige datakilden. Dette er at de tidligere ble opprettet av en dataflyt og deretter gjenbrukt.
Beregnede tabeller kan opprettes ved å referere til en tabell i samme dataflyt eller ved å referere til en tabell som er opprettet i en annen dataflyt.

Hvorfor bruke en beregnet tabell?
Det kan være tregt å utføre alle transformasjonstrinnene i én tabell. Det kan være mange årsaker til denne nedgangen – datakilden kan være treg, eller transformasjonene du gjør, må kanskje replikeres i to eller flere spørringer. Det kan være en fordel å først innta dataene fra kilden og deretter bruke dem på nytt i én eller flere tabeller. I slike tilfeller kan du velge å opprette to tabeller: én som henter data fra datakilden, og en annen – en beregnet tabell – som bruker flere transformasjoner på data som allerede er skrevet inn i datasjøen som brukes av en dataflyt. Denne endringen kan øke ytelsen og gjenbruk av data, noe som sparer tid og ressurser.
Hvis for eksempel to tabeller deler en del av transformasjonslogikken, uten en beregnet tabell, må transformasjonen gjøres to ganger.
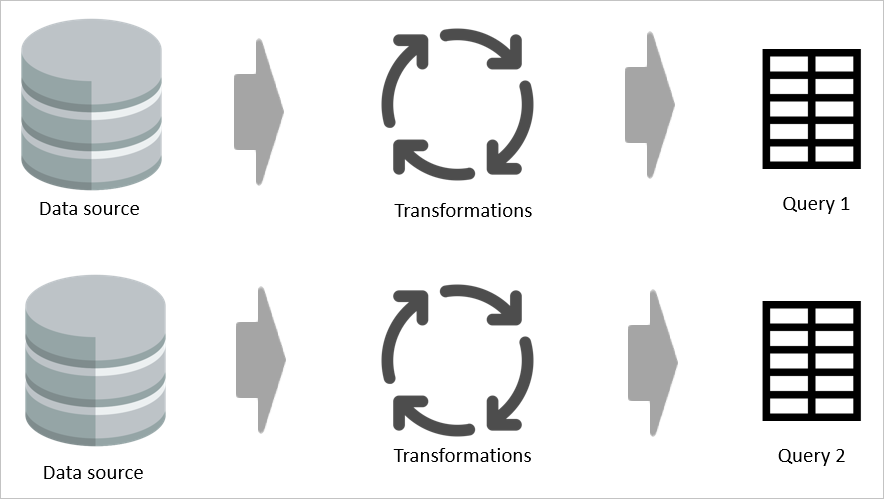
Hvis en beregnet tabell brukes, behandles imidlertid den vanlige (delte) delen av transformasjonen én gang og lagres i Azure Data Lake Storage. De gjenværende transformasjonene behandles deretter fra utdataene fra den vanlige transformasjonen. Samlet sett er denne behandlingen mye raskere.
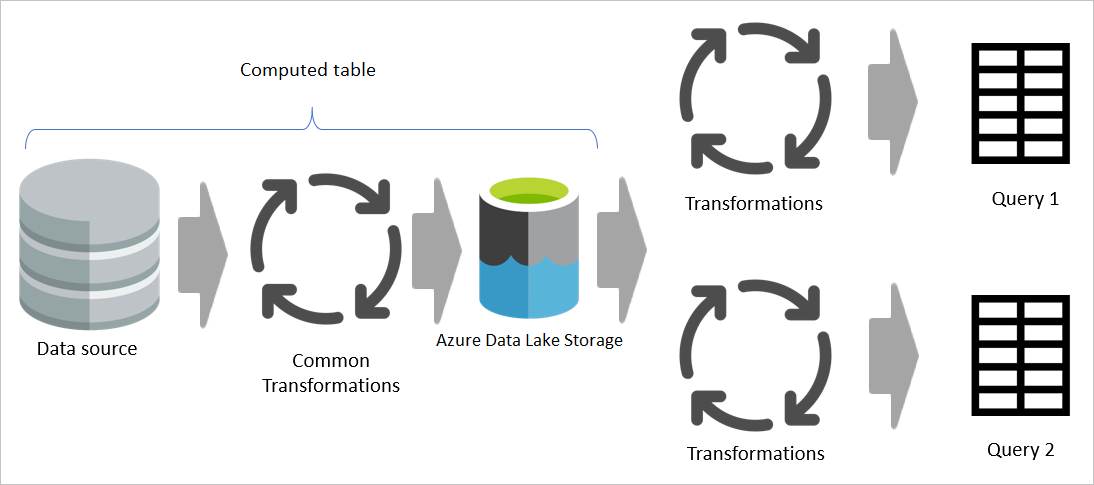
En beregnet tabell gir ett sted som kildekoden for transformasjonen og øker hastigheten på transformasjonen fordi den bare må gjøres én gang i stedet for flere ganger. Belastningen på datakilden reduseres også.
Eksempelscenario for bruk av en beregnet tabell
Hvis du bygger en aggregert tabell i Power BI for å øke hastigheten på datamodellen, kan du bygge den aggregerte tabellen ved å referere til den opprinnelige tabellen og bruke flere transformasjoner på den. Ved å bruke denne fremgangsmåten trenger du ikke å replikere transformasjonen fra kilden (delen som er fra den opprinnelige tabellen).
Figuren nedenfor viser for eksempel en Ordrer-tabell.

Ved hjelp av en referanse fra denne tabellen kan du bygge en beregnet tabell.
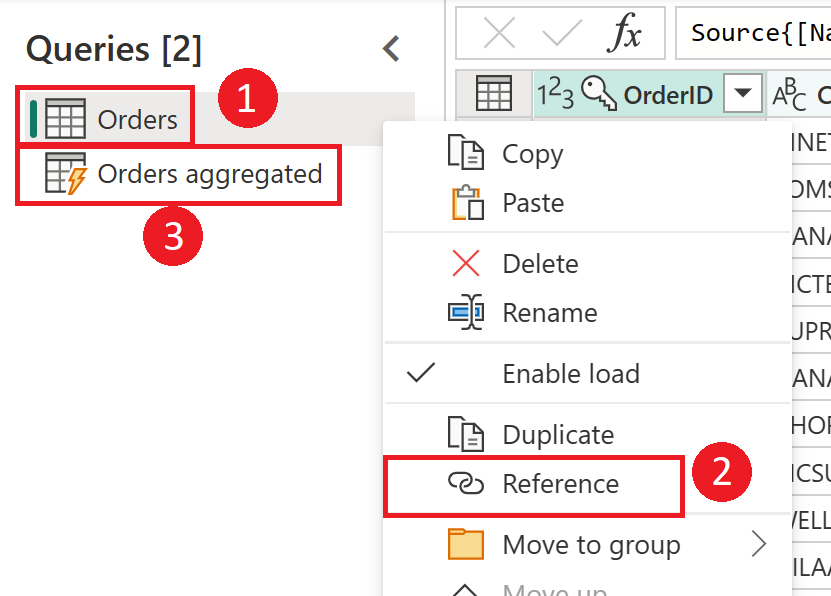
Skjermbilde som viser hvordan du oppretter en beregnet tabell fra Ordrer-tabellen. Høyreklikk Ordrer-tabellen i Spørringer-ruten, og velg referansealternativet fra rullegardinmenyen. Denne handlingen oppretter den beregnede tabellen, som har fått nytt navn her til Ordrer aggregert.
Den beregnede tabellen kan ha ytterligere transformasjoner. Du kan for eksempel bruke Grupper etter til å aggregere dataene på kundenivå.
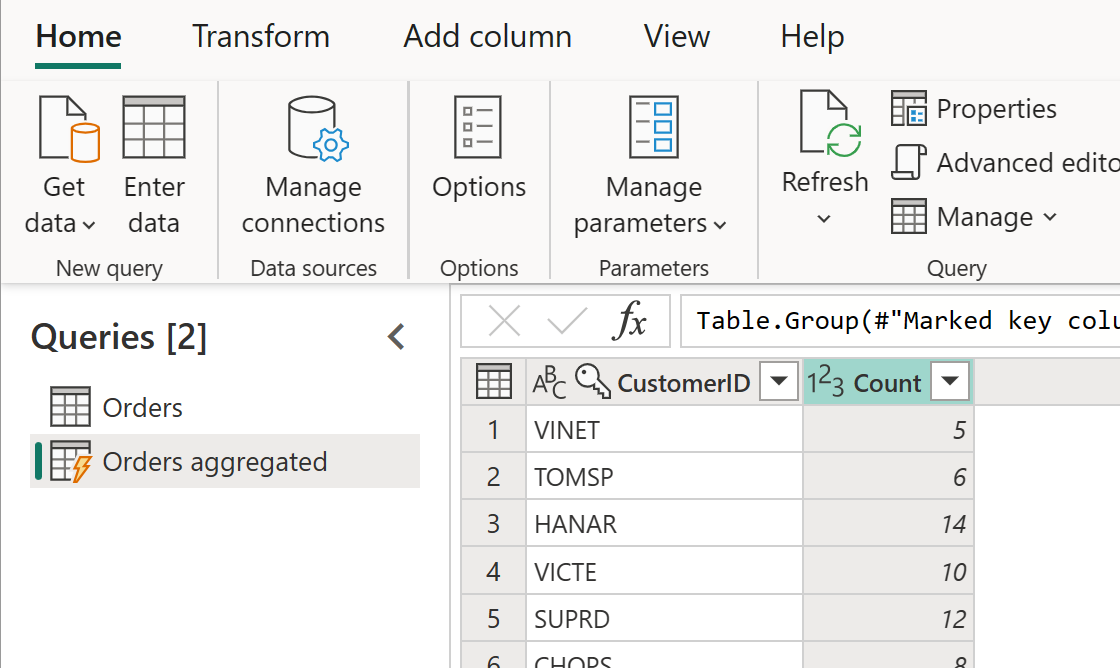
Dette betyr at tabellen Ordrer aggregert henter data fra Ordrer-tabellen, og ikke fra datakilden på nytt. Fordi noen av transformasjonene som må gjøres, allerede er gjort i Ordrer-tabellen, er ytelsen bedre og datatransformasjonen raskere.
Beregnet tabell i andre dataflyter
Du kan også opprette en beregnet tabell i andre dataflyter. Den kan opprettes ved å hente data fra en dataflyt med Microsoft Power Platform-dataflytkoblingen.
Bildet fremhever Power Platform-dataflytkoblingen fra power query-vinduet for å velge datakilde. Også inkludert er en beskrivelse som sier at én dataflyttabell kan bygges oppå dataene fra en annen dataflyttabell, som allerede er lagret.
Konseptet med den beregnede tabellen er å beholde en tabell i lagring, og andre tabeller hentet fra den, slik at du kan redusere lesetiden fra datakilden og dele noen av de vanlige transformasjonene. Denne reduksjonen kan oppnås ved å hente data fra andre dataflyter gjennom dataflytkoblingen eller referere til en annen spørring i samme dataflyt.
Beregnet tabell: Med transformasjoner eller uten?
Nå som du vet at beregnede tabeller er flotte for å forbedre ytelsen til datatransformasjonen, er et godt spørsmål å stille om transformasjoner alltid skal utsettes for den beregnede tabellen eller om de skal brukes i kildetabellen. Det vil si at dataene alltid skal inntas i én tabell og deretter transformeres i en beregnet tabell? Hva er fordeler og ulemper?
Laste inn data uten transformasjon for Tekst-/CSV-filer
Når en datakilde ikke støtter spørringsdelegering (for eksempel tekst-/CSV-filer), er det liten fordel å bruke transformasjoner når du henter data fra kilden, spesielt hvis datavolumene er store. Kildetabellen skal bare laste inn data fra Tekst/CSV-filen uten å bruke transformasjoner. Deretter kan beregnede tabeller hente data fra kildetabellen og utføre transformasjonen på toppen av de inntatte dataene.
Du kan spørre, hva er verdien for å opprette en kildetabell som bare inntar data? En slik tabell kan fortsatt være nyttig, fordi hvis dataene fra kilden brukes i mer enn én tabell, reduseres belastningen på datakilden. I tillegg kan data nå brukes på nytt av andre personer og dataflyter. Beregnede tabeller er spesielt nyttige i scenarioer der datavolumet er stort, eller når en datakilde åpnes gjennom en lokal datagateway, fordi de reduserer trafikken fra gatewayen og belastningen på datakilder bak seg.
Gjør noen av de vanlige transformasjonene for en SQL-tabell
Hvis datakilden støtter spørringsdelegering, er det godt å utføre noen av transformasjonene i kildetabellen fordi spørringen er brettet til datakilden, og bare de transformerte dataene hentes fra den. Disse endringene forbedrer den generelle ytelsen. Settet med transformasjoner som er vanlig i nedstrøms beregnede tabeller, bør brukes i kildetabellen, slik at de kan brettes til kilden. Andre transformasjoner som bare gjelder for nedstrøms tabeller, bør gjøres i beregnede tabeller.
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for